


python pandas 基础理解
其实每一篇博客我都要用很多琐碎的时间片段来学完写完,每次一点点,用到了就学一点,学一点就记录一点,要用上好几天甚至一两个礼拜才感觉某一小类的知识结构学的差不多了。
Pandas 是基于 NumPy 的一个开源 Python 库,它被广泛用于快速分析数据,以及数据清洗和准备等工作。它的名字来源是由“ Panel data”(面板数据,一个计量经济学名词)两个单词拼成的。简单地说,你可以把 Pandas 看作是 Python 版的 Excel。
一. 数据结构介绍
在pandas中有两类非常重要的数据结构,即序列Series和数据框DataFrame。Series类似于numpy中的一维数组,除了通吃一维数组可用的函数或方法,而且其可通过索引标签的方式获取数据,还具有索引的自动对齐功能;DataFrame类似于numpy中的二维数组,同样可以通用numpy数组的函数和方法,而且还具有其他灵活应用
1.Series的介绍
1)用一维数组创建序列
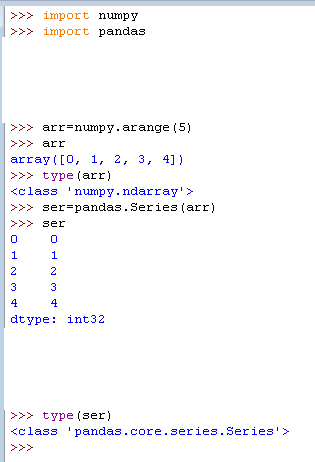
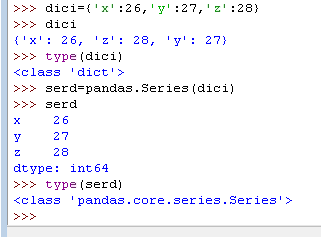
2)通过字典创建序列
2.DataFrame
1)用字典创建DataFrame

2)查 其中某一列
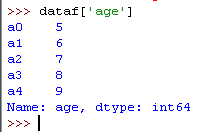
我们只获取一列,所以返回的就是一个 Series。可以用 type() 函数确认返回值的类型

3)查多列
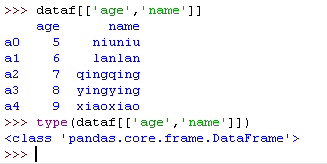
多列的是DataFrame
4)增加一个新列--------直接加

5)增加一个新列--------用现有的列去产生新的列

6)从 DataFrame 里删除行/列
想要删除某一行或一列,可以用 .drop() 函数。在使用这个函数的时候,你需要先指定具体的删除方向,axis=0 对应的是行 row,而 axis=1 对应的是列 column 。

查一下

这是为了防止误删除
7) 真删除某列,再加个参数就好了
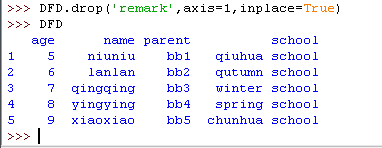
8)获取某行,或者某几行
 ]
]
列是同一个道理
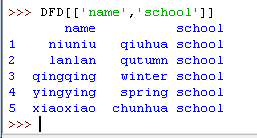
9)加筛选条件
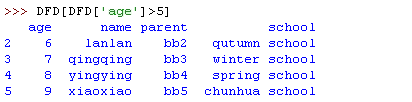
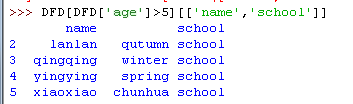
10)新加一列
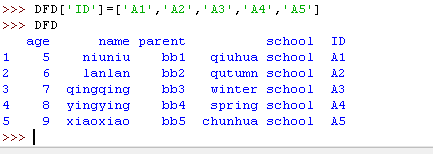
11)重置索引
可以用 .reset_index() 简单地把整个表的索引都重置掉
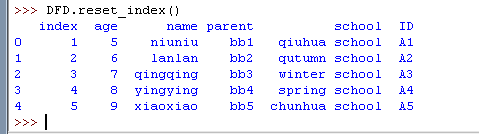
和删除操作差不多,.reset_index() 并不会永久改变你表格的索引,除非你调用的时候明确传入了 inplace 参数,比如:.reset_index(inplace=True)
还可以用 .set_index() 方法,将 DataFrame 里的某一列作为索引来用
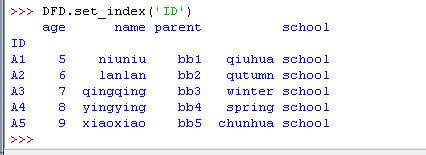
注意,不像 .reset_index() 会保留一个备份,然后才用默认的索引值代替原索引,.set_index() 将会完全覆盖原来的索引值。
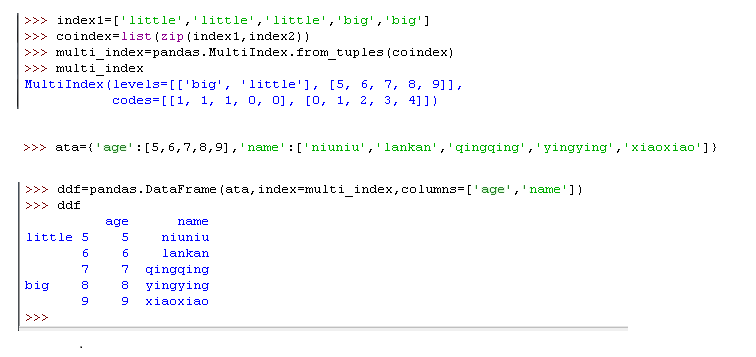
12)创建多级索引ata
多级索引其实就是一个由元组(Tuple)组成的数组,每一个元组都是独一无二的
可以从一个包含许多数组的列表中创建多级索引(调用 MultiIndex.from_arrays ),
也可以用一个包含许多元组的数组(调用 MultiIndex.from_tuples )
用一对可迭代对象的集合(比如两个列表,互相两两配对)来构建(调用MultiIndex.from_product )。
举个例子
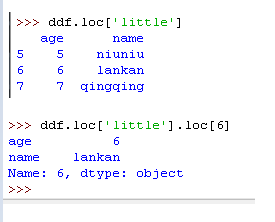
13) 获取多级索引中的数据,还是用到 .loc[]
3.清洗数据
1)删除或者填充空值
在许多情况下,如果你用 Pandas 来读取大量数据,往往会发现原始数据中会存在不完整的地方。在 DataFrame 中缺少数据的位置, Pandas 会自动填入一个空值,比如 NaN或 Null 。因此,我们可以选择用 .dropna() 来丢弃这些自动填充的值,或是用.fillna() 来自动给这些空值填充数据。
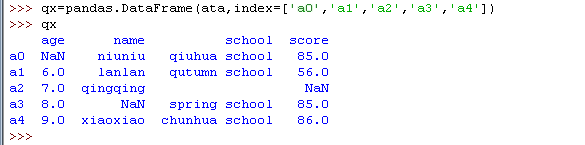
当你使用 .dropna() 方法时,就是告诉 Pandas 删除掉存在一个或多个空值的行(或者列)。删除行用的是 .dropna(axis=0) ,删除列用的是 .dropna(axis=1) 。

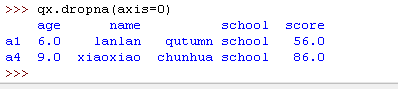
请注意,如果你没有指定 axis 参数,默认是删除行。
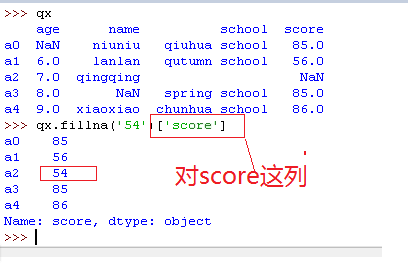
2)替换na
如果你使用 .fillna() 方法,Pandas 将对这个 DataFrame 里所有的空值位置填上你指定的默认值
4.数据描述
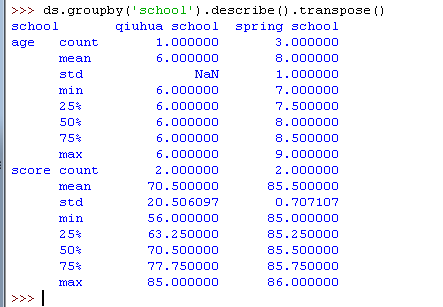
1) describe()
Pandas 的 .describe() 方法将对 DataFrame 里的数据进行分析,并一次性生成多个描述性的统计指标,方便用户对数据有一个直观上的认识。
生成的指标,从左到右分别是:计数、平均数、标准差、最小值、25% 50% 75% 位置的值、最大值。

如果你不喜欢这个排版,你可以用 .transpose() 方法获得一个竖排的格式:
2) 堆叠(Concat)

因为我们没有指定堆叠的方向,Pandas 默认按行的方向堆叠,把每个表的索引按顺序叠加。如果你想要按列的方向堆叠,那你需要传入 axis=1 参数:
3)归并(Merge)
使用 pd.merge() 函数,能将多个 DataFrame 归并在一起,它的合并方式类似合并 SQL 数据表的方式。
归并操作的基本语法是 pd.merge(left, right, how='inner', on='Key') 。其中 left 参数代表放在左侧的 DataFrame,而 right 参数代表放在右边的 DataFrame;how='inner' 指的是当左右两个 DataFrame 中存在不重合的 Key 时,取结果的方式:inner 代表交集;Outer 代表并集。最后,on='Key' 代表需要合并的键值所在的列,最后整个表格会以该列为准进行归并。
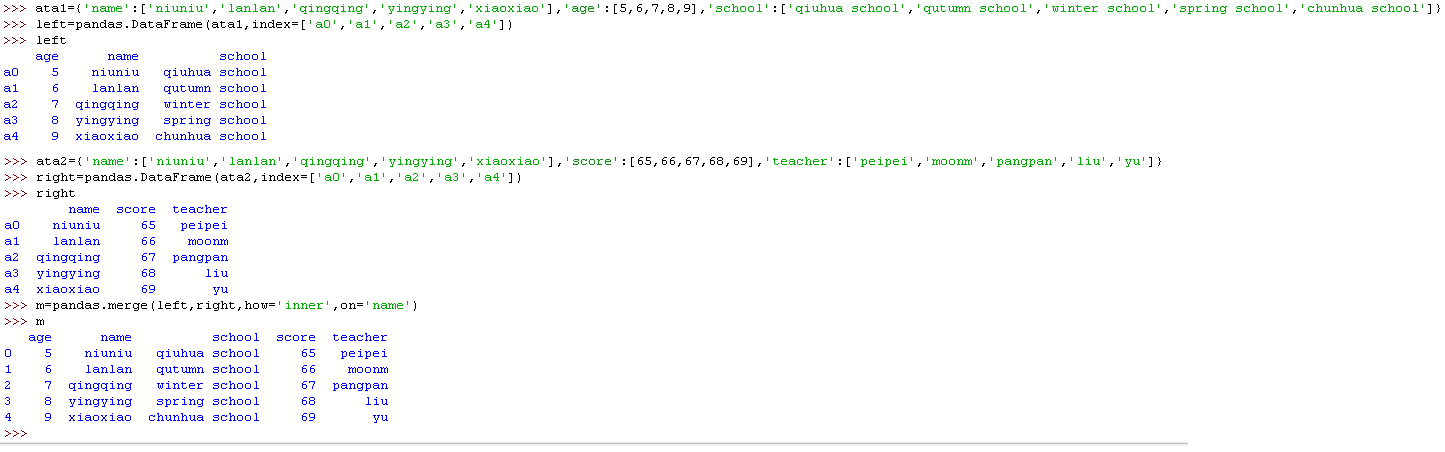
其他的 就 不 一一举例了
同时,我们可以传入多个 on 参数,这样就能按多个键值进行归并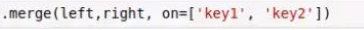
4)join
如果你要把两个表连在一起,然而它们之间没有太多共同的列,那么你可以试试 .join() 方法。和 .merge() 不同,连接采用索引作为公共的键,而不是某一列。
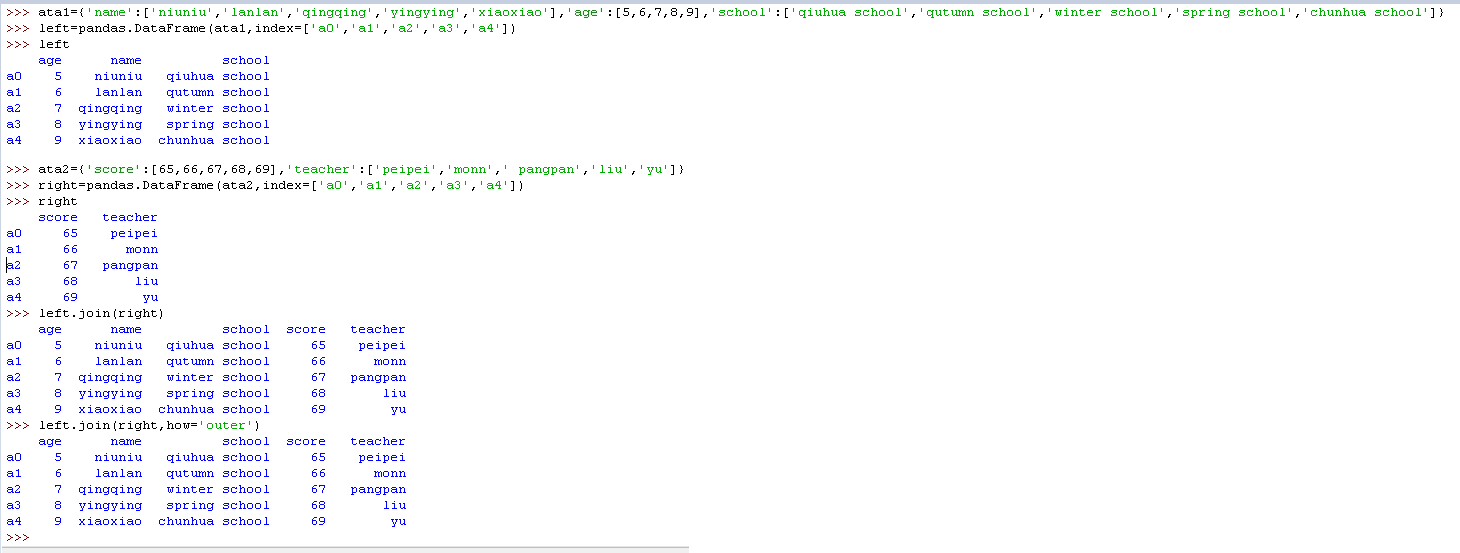
同样,inner 代表交集,Outer 代表并集
5.数值处理
1)查找不重复的值
unique() 方法

查个数

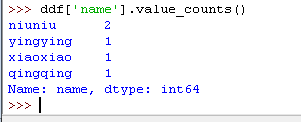
还可以用 .value_counts() 同时获得所有值和对应值的计数
2).apply() 方法,应用自定义函数
用 .apply() 方法,可以对 DataFrame 中的数据应用自定义函数,进行数据处理

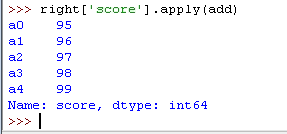
3)调用内置函数
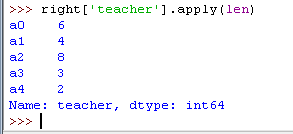
4) 用 lambda 表达式
你定义了一个函数,而它其实只会被用到一次。那么,我们可以用 lambda 表达式来代替函数定义,简化代码

5) DataFrame 的属性
DataFrame 的属性包括列和索引的名字。假如你不确定表中的某个列名是否含有空格之类的字符,你可以通过 .columns 来获取属性值,以查看具体的列名。

6)排序
如果想要将整个表按某一列的值进行排序,可以用 .sort_values() :
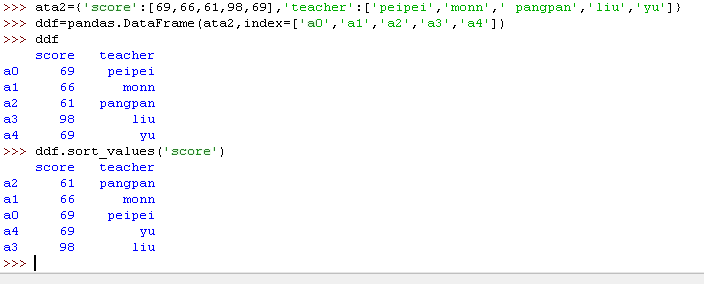
如上所示,表格变成按 col2 列的值从小到大排序。要注意的是,表格的索引 index 还是对应着排序前的行,并没有因为排序而丢失原来的索引数据。
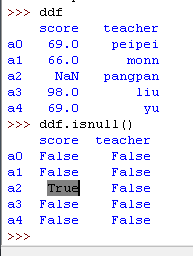
7)查找空值
可以用 Pandas 的 .isnull() 方法,方便快捷地发现表中的空值
参考:
https://blog.csdn.net/qq_42156420/article/details/82813482
https://www.cnblogs.com/nxld/p/6058591.html
