

了解一下UTF-16
1)先啰嗦一下
UTF-16是一种编码格式。啥是编码格式?就是怎么存储,也就是存储的方式。 存储啥?存二进制数字。为啥要存二进制数字? 因为Unicode字符集里面把二进制数字和字符一一对应了,存二进制数字就相当于存了二进制数字对应的字符了。为啥不直接存字符?因为计算机只能处理二进制数字。
UTF是 Unicode Translation Format的缩写,即把Unicode转做某种格式的意思
UTF-16跟UTF-8比较,好处在于大部分字符都以固定长度的字节 (2字节) 储存,但UTF-16却无法兼容ASCII编码。
2)
utf-16编码方式 ? 1.utf-16编码方式源于ucs-2(universal character set coded in 2 octets、2-byteuniversal character set)。 而ucs-2,是早期遗留下来的历史产物。 ucs-2将字符编号直接映射为字符编码(cef,而非ces,详见前文中对现代字符编码模型的解释),亦即字符编号就是字符编码,中间没有经过特别的编码算法
Unicode字符集(CCS)到目前为止定义了包括1个基本平面BMP和16个增补平面SP在内的共17个平面。
每个平面的码点数量为2^16=65536个,因此17个平面的码点总数为共65536*17=1114112个。其中,基本平面码点为65536个(码点编号范围为0x0000~0xFFFF),增补平面码点为1114112-65536=65536*16=1048576个(码点编号范围为0x10000~0x10FFFF)。
很明显,简单地用一个16位码元肯定无法表示所有17个平面的这么多码点(因为2^16=65536,而码点总数为65536*17=1114112)。而UCS-2,正是用两个字节共16位来表示一个字符的。为支持字符编号超过U+FFFF的增补字符,扩展势在必行。
UCS因而又提出了UCS-4,即用四个字节共32位来表示一个字符(此时UCS-4同样既可认为是编号字符集CCS中的字符编号,也可认为是字符编码方式CEF中的字符编码)。但码元也因此从16位扩展到了32位。
具体来说,就是Unicode字符集基本平面BMP中的字符(大致相当于UCS字符集中的UCS-2字符,但必须除开U+D800~U+DFFF这一在Unicode字符集BMP中称之为代理码点的部分),仍然是直接映射关系,亦即这部分字符的字符编号与字符编码是等同的。
UTF-16中16的意思是16个bit的意思,也就是说是用16位来存储,但是它比较奇葩,它使用 2 个或者 4 个字节来存储
对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储,并且直接存储 Unicode 编号,不用进行编码转换,这跟 UTF-32 非常类似。
对于 Unicode 编号范围在 10000~10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。

位于 D800~0xDFFF 之间的 Unicode 编码是特别为四字节的 UTF-16 编码预留的,所以不应该在这个范围内指定任何字符。如果你真的去查看 Unicode 字符集,会发现这个区间内确实没有收录任何字符。
UTF-16 要求在制定 Unicode 字符集时必须考虑到编码问题,所以真正的 Unicode 字符集也不是随意编排字符的
3)举例UTF-16 两个字节
用UTF-16表示"汉"
unicode是6C49(这是用十六进制表示,用十进制表示是27721,
UTF-16表示的话就是01101100 01001001(共16 bit,两个字节).
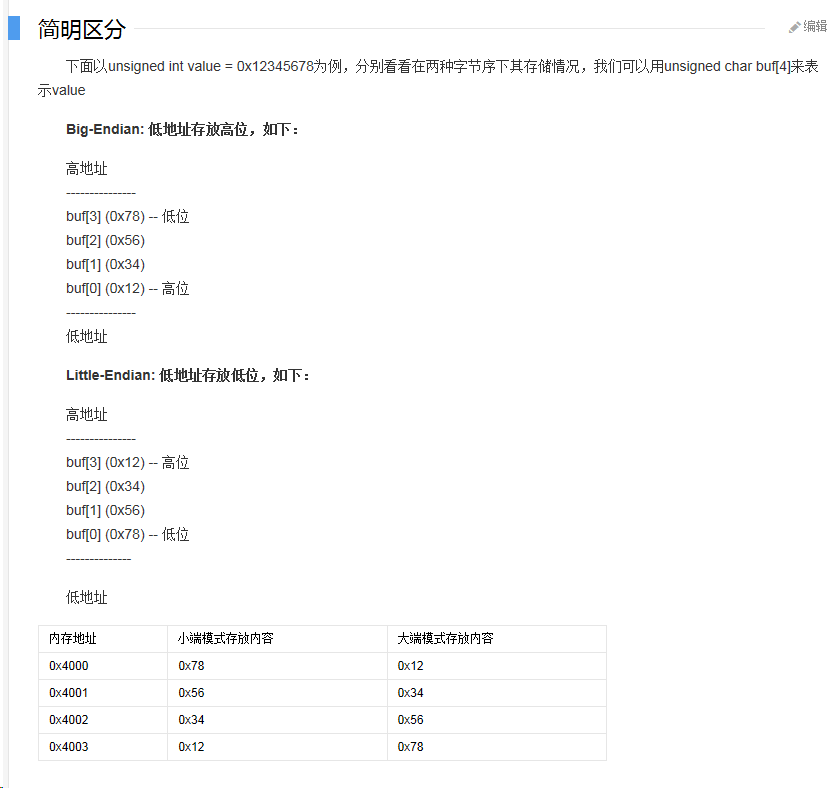
4)大小端模式
文重点讲解的是 UTF-16 编码格式字节数组的转化。UTF-16 顾名思义,就是用两个字节表示一个字符。那么用两个字节表示必然存在字节序的问题,即大端小端的问题。下面就来讲讲 UTF-16BE、UTF-16LE、UTF-16 三者之间的区别吧。
UTF-16BE,其后缀是 BE 即 big-endian,大端的意思。大端就是将高位的字节放在低地址表示。
UTF-16LE,其后缀是 LE 即 little-endian,小端的意思。小端就是将高位的字节放在高地址表示。
UTF-16,没有指定后缀,即不知道其是大小端,所以其开始的两个字节表示该字节数组是大端还是小端。即FE FF表示大端,FF FE表示小端。
采用UTF-16BE,UTF-16LE,一个字符编码成两个字节,采用UTF-16,一个字符编码成4个字节,与UTF-16BE和UTF-16LE相比,在前边加上了\uFEFF表示UTF-16BE,或加上\uFFEF表示UTF-16LE。
图来自大小端模式百度百科
5)UTF-16 还有很多问题
- UTF-16 能表示的字符数有 6 万多,看起来很多,但是实际上目前 Unicode 5.0 收录的字符已经达到 99024 个字符,早已超过 UTF-16 的存储范围;这直接导致 UTF-16 地位颇为尴尬——如果谁还在想着只要使用 UTF-16 就可以高枕无忧的话,恐怕要失望了
- UTF-16 存在大小端字节序问题,这个问题在进行信息交换时特别突出——如果字节序未协商好,将导致乱码;如果协商好,但是双方一个采用大端一个采用小端,则必然有一方要进行大小端转换,性能损失不可避免(大小端问题其实不像看起来那么简单,有时会涉及硬件、操作系统、上层软件多个层次,可能会进行多次转换)
- 另外,容错性低有时候也是一大问题——局部的字节错误,特别是丢失或增加可能导致所有后续字符全部错乱,错乱后要想恢复,可能很简单,也可能会非常困难。(这一点在日常生活里大家感觉似乎无关紧要,但是在很多特殊环境下却是巨大的缺陷)
目前支撑我们继续使用 UTF-16 的理由主要是考虑到它是双字节的,在计算字符串长度、执行索引操作时速度很快。当然这些优点 UTF-32 都具有,但很多人毕竟还是觉得 UTF-32 太占空间了。
这一点摘自https://www.cnblogs.com/fnlingnzb-learner/p/6163205.html
6)U+D800~U+DFFF
UTF-16还能表示一部分的UCS-4代码点——U+10000~U+10FFFF。表示算法比较复杂,简单说明如下:
- 从代码点U中减去0x10000,得到U'。这样U+10000~U+10FFFF就变成了 0x00000~0xFFFFF。
- 用20位二进制数表示U'。 U'=yyyyyyyyyyxxxxxxxxxx
- 将前10位和后10位用W1和W2表示,W1=110110yyyyyyyyyy,W2=110111xxxxxxxxxx,则 W1 = D800~DBFF,W2 = DC00~DFFF。
例如,U+12345表示为 D8 08 DF 45(UTF-16BE),或者08 D8 45 DF(UTF-16LE)。
但是由于这种算法的存在,造成UCS-2中的 U+D800~U+DFFF 变成了无定义的字符。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号