


python XML文件解析:用xml.dom.minidom来解析xml文件
python解析XML常见的有三种方法:
一是xml.dom.*模块,是W3C DOM API的实现,若需要处理DOM API则该模块很合适,
二是xml.sax.*模块,它是SAX API的实现,这个模块牺牲了便捷性来换取速度和内存占用,SAX是一个基于事件的API,这就意味着它可以“在空中”处理庞大数量的的文档,不用完全加载进内存
三是xml.etree.ElementTree模块(简称 ET),它提供了轻量级的Python式的API,相对于DOM来说ET 快了很多,而且有很多令人愉悦的API可以使用,相对于SAX来说ET的ET.iterparse也提供了 “在空中” 的处理方式,没有必要加载整个文档到内存,ET的性能的平均值和SAX差不多,但是API的效率更高一点而且使用起来很方便
xml.dom.*
文件对象模型(Document Object Model,简称DOM),是W3C组织推荐的处理可扩展置标语言的标准编程接口。一个 DOM 的解析器在解析一个XML文档时,一次性读取整个文档,把文档中所有元素保存在内存中的一个树结构里,之后你可以利用DOM 提供的不同的函数来读取或修改文档的内容和结构,也可以把修改过的内容写入xml文件。python中用xml.dom.minidom来解析xml文件。
a. 获得子标签
b. 区分相同标签名的标签
c. 获取标签属性值
d. 获取标签对之间的数据
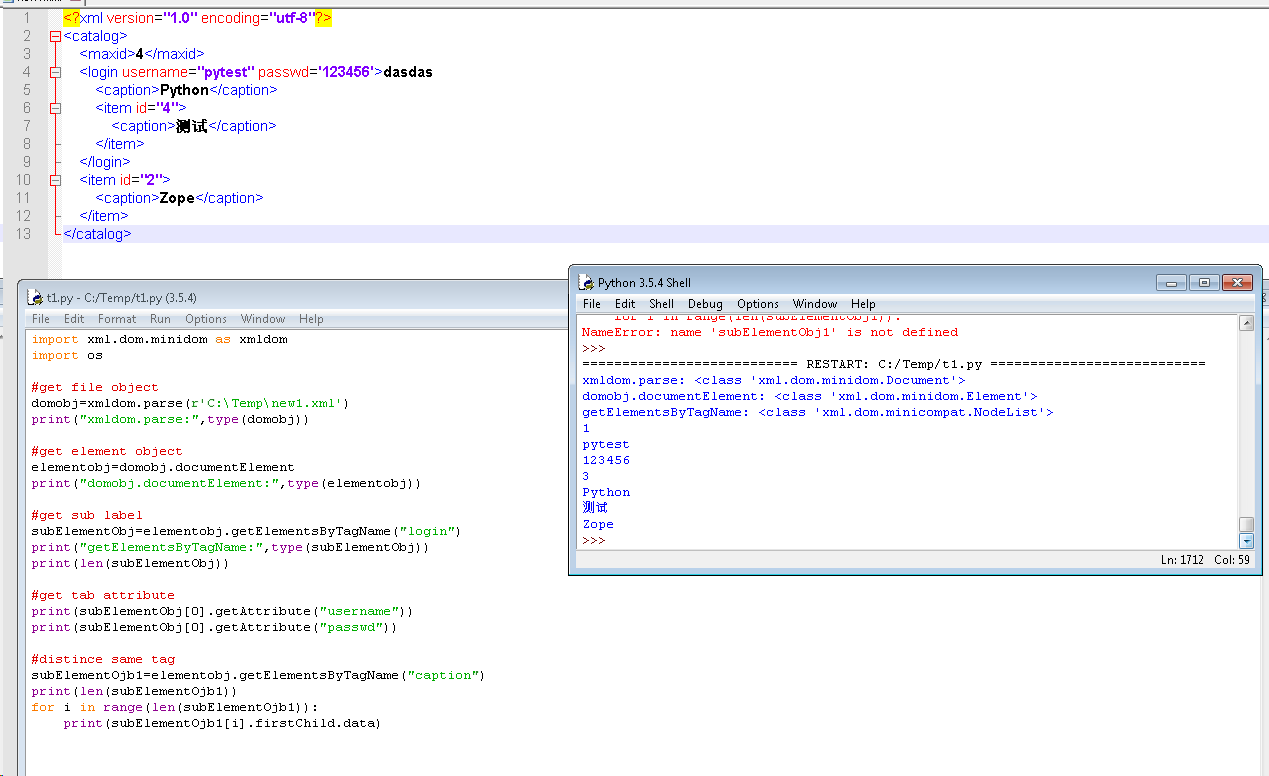
#通过minidom解析xml文件
import xml.dom.minidom as xmldom
import os
#get file object
domobj=xmldom.parse(r'C:\Temp\new1.xml')
print("xmldom.parse:",type(domobj))
#get element object
elementobj=domobj.documentElement
print("domobj.documentElement:",type(elementobj))
#get sub label
subElementObj=elementobj.getElementsByTagName("login")
print("getElementsByTagName:",type(subElementObj))
print(len(subElementObj))
#get tab attribute
print(subElementObj[0].getAttribute("username"))
print(subElementObj[0].getAttribute("passwd"))
#distince same tag
subElementOjb1=elementobj.getElementsByTagName("caption")
print(len(subElementOjb1))
for i in range(len(subElementOjb1)):
print(subElementOjb1[i].firstChild.data)
Learn from : https://www.cnblogs.com/xiaobingqianrui/p/8405813.html

