

mysql企业常用集群架构
转自 https://blog.csdn.net/kingice1014/article/details/76020061
1、mysql企业常用集群架构
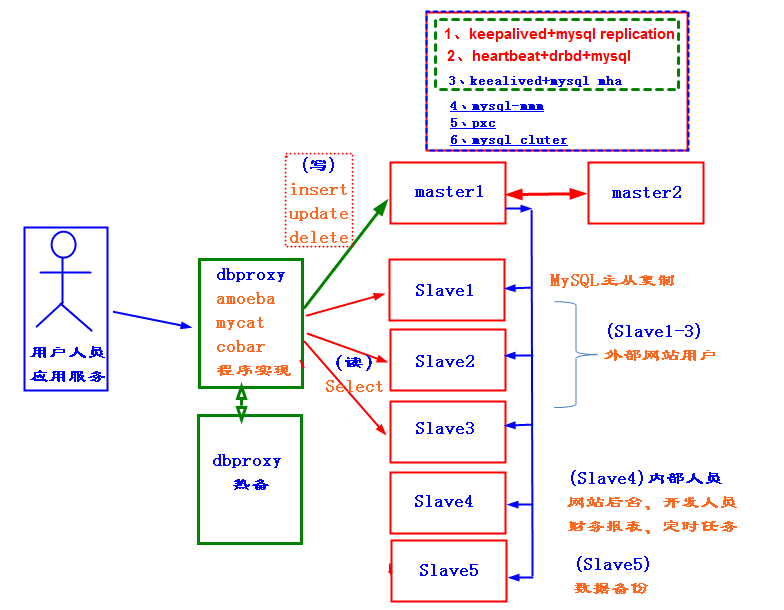
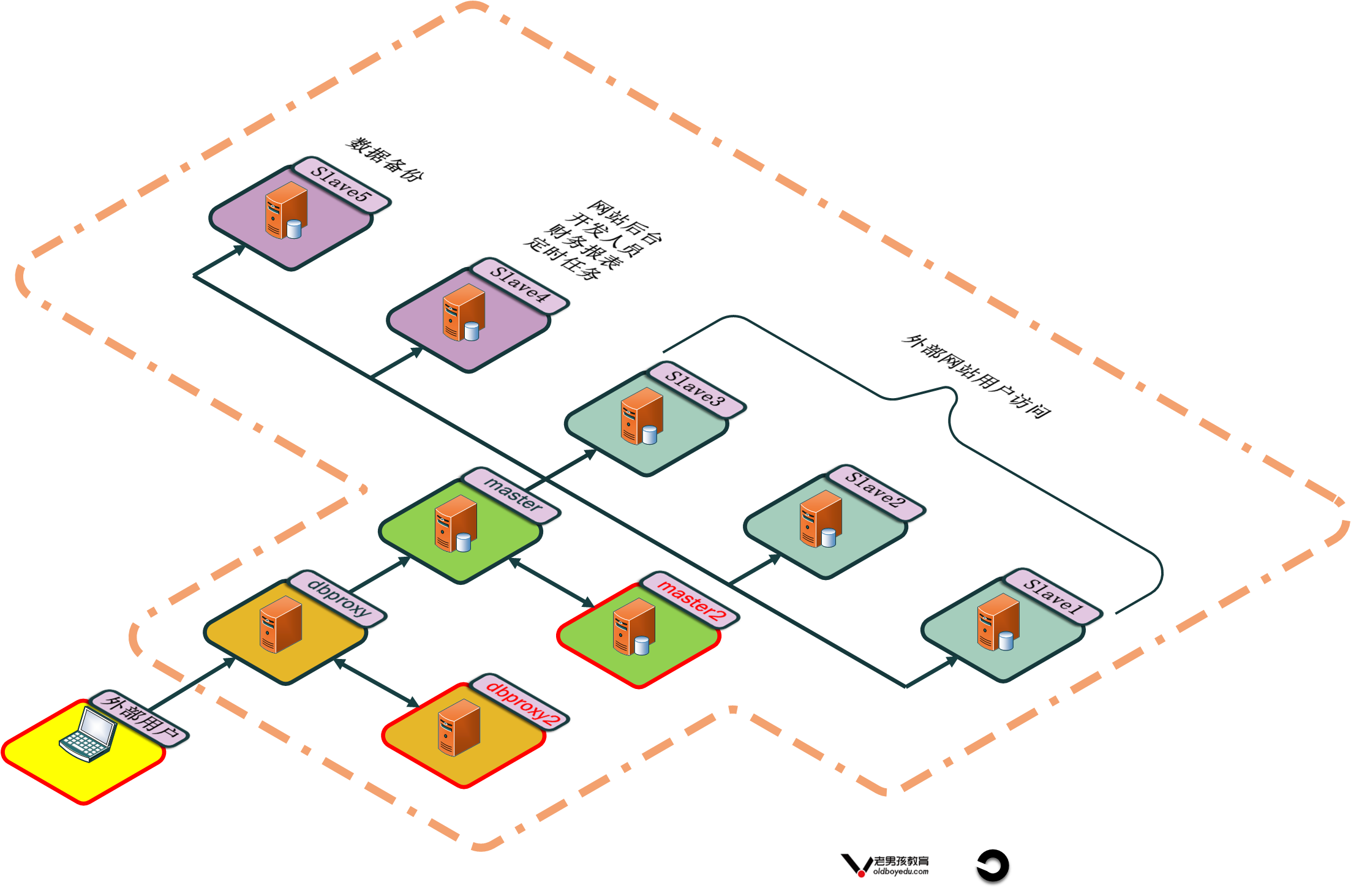
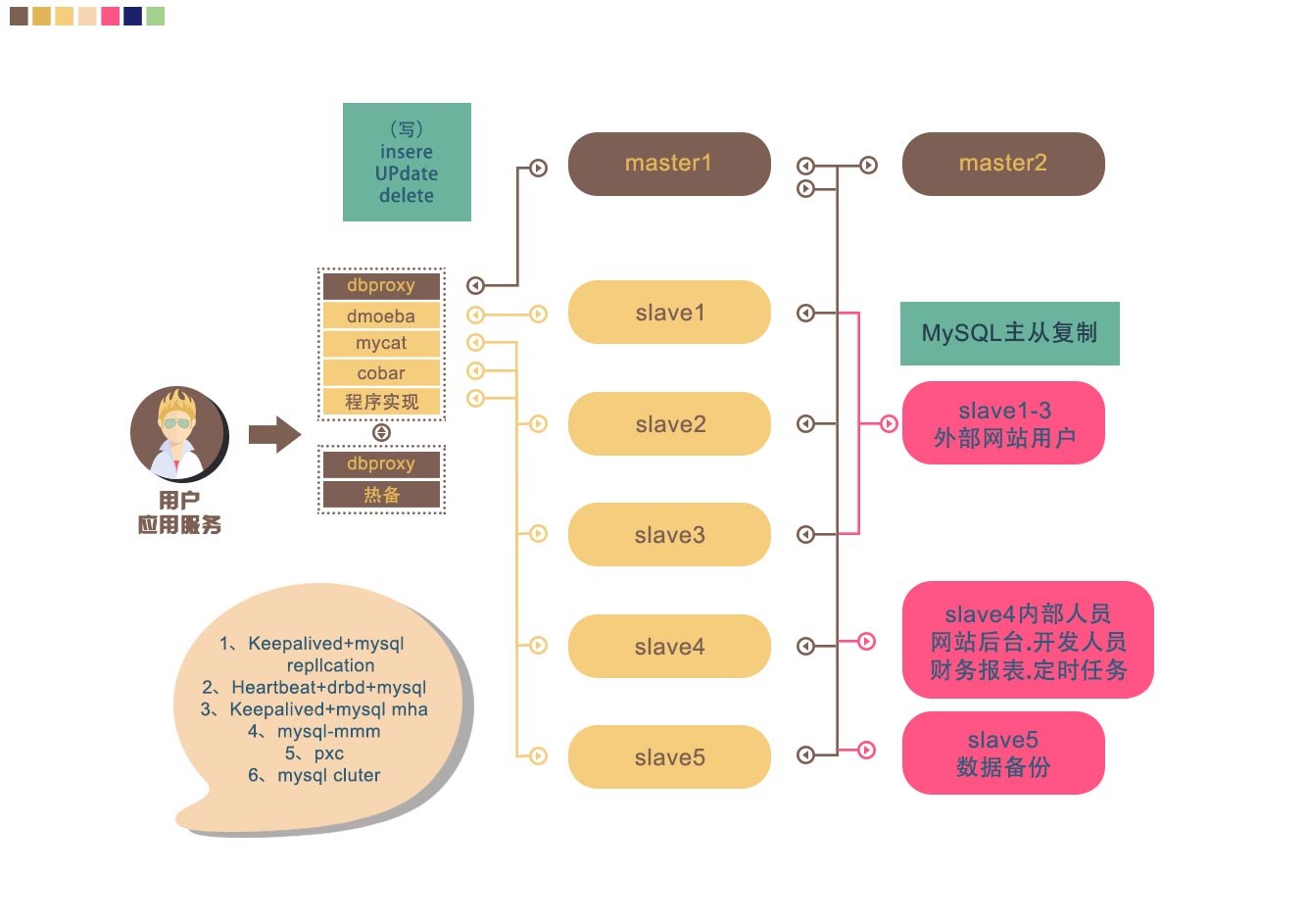
在中小型互联网的企业中。mysql的集群一般就是上图的架构。WEB节点读取数据库的时候读取dbproxy服务器。dbproxy服务器通过对SQL语句的判断来进行数据库的读写分离。读请求负载到从库(也可以把主库加上),写请求写主库。
这里的dbproxy是数据库集群的唯一出口所以也需要做高可用。
drproxy是数据库读写分离的常用软件,amoeba、mycat、cobar也很常用。这类软件不仅带有读写分离功能,还可以实现负载均衡以及后端节点的健康检查。
数据库的读写分离除了通过这类数据库中间件软件实现,还可以写在程序中。
通常我们的主库要做双主高可用,实现主库挂掉另一个主库立刻接管。如果不做双主,从库接管主库的时候需要做状态迁移,会有延迟。
数据库主库的高可用重点需要考虑的是数据同步。比较常用的高可用方案有:
1、keepalived+mysql replication。通过keepalived实现VIP飘逸,通过mysql自带的同步方案replication实现数据同步。
2、hearbeat+drbd。通过drbd实现双主数据的同步,这个数据同步是基于块设备的。比一般的同步方案要快很多。通过heartbeat实现VIP漂移以及drbd资源的切换管理。
3、keepalived+mha。
对于从库,最好不要超过5个。我们可以把其中的三个作为用户访问的节点,把另外一个作为内部人员的查询节点。因为内部人员查询节点的时候一般是按照时间段查询,不经过索引,占用的资源比较多,所以要把这个节点单独专用,以免影响客户访问。最后我们应该留一个从库进行数据库的数据备份。
从库的数据一致性保持可以通过直接于主库进行主从辅助,也可以从其他从库那进行主从复制(优点是减少主库压力,缺点是延迟稍大)。
2、MYSQL数据架构
数据库服务器==》数据库(多个实例)==》多个库==》多个表==》多个字段行列(数据)
在一台数据库服务器上可以跑多个实例,一个实例中有多个库,一个库有多个表,一个表有多个行列。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号