
《现代操作系统》笔记-内存管理1
写在前面
鄙人是一个初入职场的码畜,由于爱好希望多看一些计算机方面的资料。同时因为平时工作时一直打代码,已经很头疼了,因此希望在下班后了解一些不需要打代码的技术,操作系统就自然而然成了选择(不就是懒么,说这么多)。
之前看过网上的评论,《现代操作系统》是一本不错的书,但是中文版翻译的很不好,几乎像是扔进百度翻译直接拿出来的。我在网上找过一些资源,确实如此。于是购入了英文版。无奈英语不好,而且有些复杂的句子就看不太懂了,因此用中文的电子版作参考#(滑稽)
对于这本书,作者有的部分写的很详细,有的部分则是一带而过。我觉得,学习这本书并不是要仔仔细细的了解每个细节,因为体现细节的是源代码,文字的描述多少会有偏差;但是也不能浅尝辄止。而是要学习了解设备,软件发展的过程,解决问题、安排调度的主要思路,它们的优势缺点和解决方法。如果作者给出了代码,则应当仔细斟酌。
这本书鄙人也正在看,希望以写博客为动力,每周学习,每周更新。已经看到了“内存管理”,就从这开始吧,之前的慢慢补上。
内存管理
操作系统的工作:跟踪内存的使用,在需要时分配内存,在用完后回收内存。
内存抽象的演化过程
1. 无内存抽象
某一时间只可能有一个运行的程序在内存中,但可以通过在内存和硬盘中的反复交换,达到同时运行多个程序的目的
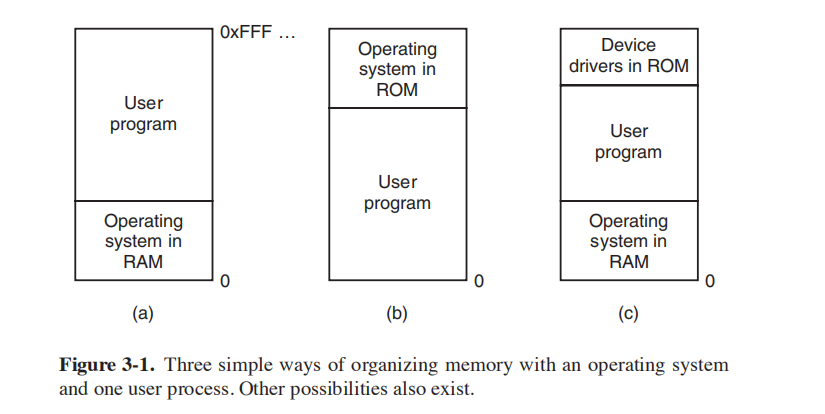
图(a)常用于之前的大型机和迷你电脑,现在很少使用
图(b)常用于手持电脑和嵌入式设备
图(c)常用于早期的个人电脑
因为(a)和(c)的操作系统在RAM中,因此程序可能有擦除操作系统的风险
在IBM 360中,内存中可以存在多个进程,使用“保护键”来限制程序对内存的访问。只有当程序状态字(PSW)与内存中的Key一致时,才允许访问
缺陷:尽管多个可以在内存中同时存在(顺序存放),但将每个程序中书写的地址直接当作要访问的地址来使用,而不是相对自身放置的位置的地址,就会访问到其它程序中。(见下图)
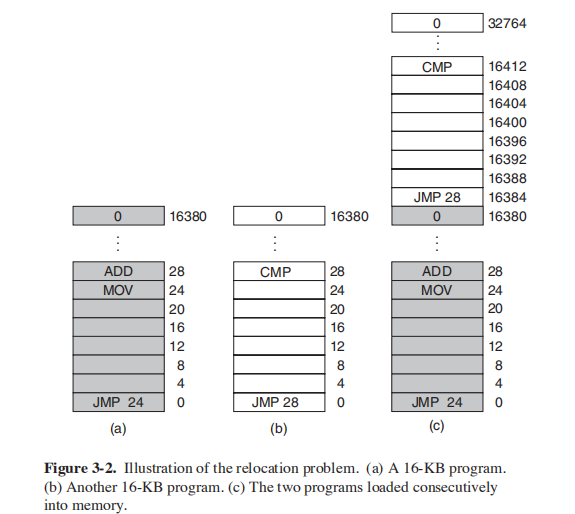
解决:每个程序访问自己的地址集——静态地址重定位(static relocation)。在程序载入时,将程序中的地址通过计算变为内存中的实际地址(程序中的相对地址变为绝对地址)。但这样的缺陷是:
- 程序载入时需要计算,因此速度会变慢;
- 需要区分哪些数字是地址,哪些数字是操作的数值。
虽然无内存抽象应用在大型机上的历史距今已经很久远了,但在现在的收音机、洗衣机等嵌入式设备中很普遍。因为所有程序已经提前写好,并且用户无法改变其中的程序,因此无需内存抽象。
2.一种内存抽象:地址空间
无内存抽象的缺点:用户程序可以随意访问内存,有可能损坏操作系统;难以实现多个进程同时运行
(1)地址空间 (address space):
一个进程可以使用的一段内存的地址合集
由此产生:基地址寄存器和界限寄存器
程序载入时(需要连续的内存),基地址寄存器设为程序在内存中的起始地址,界限寄存器设为程序的长度。程序载入时,不进行地址重定位。而是在访问内存时,有硬件加上基地址寄存器中的值后再访问(动态地址重定位(dynamic relocation))。缺点是,每次访问内存都要计算(基地址寄存器)和比较(界限寄存器)
(2)交换(swapping):
内存不足以容纳所有的进程,在内存和硬盘中随程序的运行来回交换。 另一种解决的方法是使用“虚拟内存(virtual memory)”。
内存压缩(memory compaction):不同程序反复移入、移出内存,中间小的内存区域会越来越多,需要合并为大的内存空间以供继续分配。缺点是太耗时,很少使用
如果进程的数据段部分会增长,切没有相邻的空闲空间可以使用,它或其它相邻的进程就必须移出,以创造更大的空间使用。
(3)管理空闲内存
方式:位图和链表
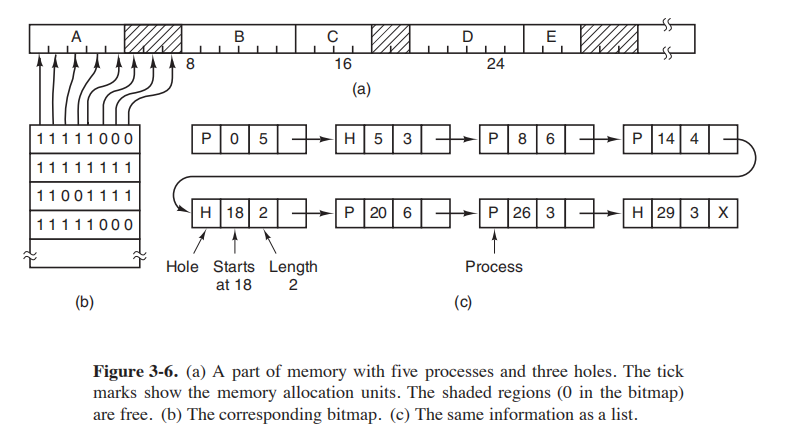
位图:内存被分为小到几个字和大到几K的基本单元,在位图中用0表示空闲,1表示正在使用。位图的大小取决于内存的大小和基本单元的大小。
优点:方式简单
缺点:在位图中查找指定长度的连续空间是耗时的操作
链表:每个节点由 空闲(Hole)/使用(Process)标志位、开始地址、长度、下一个节点指针 组成,按地址顺序排序,优点是当内存被换出时,更新表的操作比较直接。由于进程表中通常由指向内存链表某一节点的指针,因此通常实现为双向链表,以便于向前向后查找,合并空闲区域。
(4)为新调入的进程分配内存的算法
a. 首次适配(first fit)
找到第一个足够大的空间并为其分配。
优点:算法简单,查询少
b. 下次适配(next fit)
保存每一次查找的位置,下次查找时从保存的位置开始查找
c. 最佳适配(best fit)
遍历,找到最小的且足够使用的区域
缺点:需要遍历查找,而且更容易产生小的无用的空闲区域(最佳适配往往找到的合适空间难以完全与需求空间相等,而是会略大一点,因此会剩下小的区域)
d. 最差适配(worst fit)
总是寻找最大的空间来分配
以上几种可以有一些改进
稍微改进1: 把链表分开为进程链表和空闲链表来加速查找(是否在使用)。但在回收内存时,速度会降低(需要操作两个链表)。
稍微改进2: 将空闲区的链表按空闲区域大小顺序排序。首次适配和最佳适配效果相同,下次适配失去意义。
稍微改进3: 在空闲区的直接写入开始地址,大小,下一个节点等指针信息,而不必再用专门的节点。
e. 快速适配(quick fit)
维护几种常用长度的空内存链表,4K、8K、12K。
所有将链表分开的的策略都会有的问题:查找相邻合并区域的代价很高。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号