

Neo4j分布式集群架构
总体架构
从下图可见,Neo4j集群由两个不同的角色Core Servers和Read Replicas组成,这两个角色是任何生产部署中的基础,但彼此之间的管理规模不同,并且在管理整个集群的容错性和可伸缩性方面承担着不同的角色。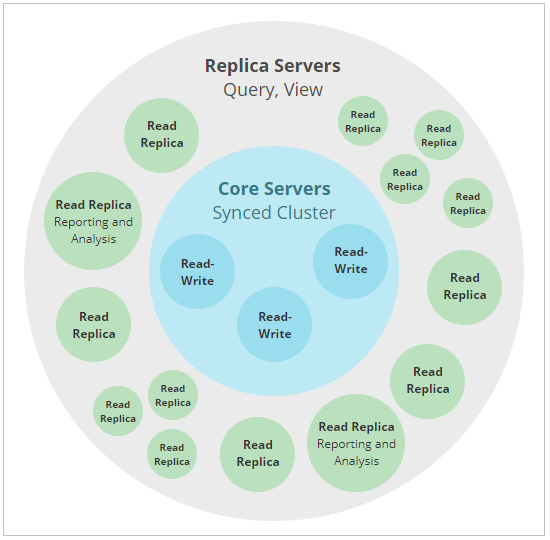
Core Servers
核心服务器的主要责任是保护数据。 核心服务器通过使用Raft协议复制所有事务来做到这一点。 在确认向最终用户应用程序提交事务之前,Raft确保数据安全持久。 在实际环境中,这意味着一旦集群(N / 2 + 1)中的大多数核心服务器都接受了事务,安全性要求会影响写入延迟。 隐式写入将以最快的多数Core Servers被确认,但是随着群集中核心服务器数量的增加,确认一次写入所需的Core Servers的数量也会增加。实际上,这意味着典型的Core Server集群中需要一定数量的服务器,足以为特定部署提供足够的容错能力。 这是使用公式M = 2F +1计算的,其中M是容忍F故障所需的核心服务器数量。 例如:
- 为了容忍两个发生故障的核心服务器,我们需要部署五个核心的集群。
- 最小的容错群集(一个可以容忍一个故障的群集)必须具有三个内核。
- 也可以创建仅包含两个核心的因果集群。 但是,该群集不是容错的。 如果两个服务器之一发生故障,其余服务器将变为只读。
请注意,如果Core Server集群遭受足够的故障而无法处理写入,则它将变为只读状态以保持安全。
Read Replicas
只读副本的主要职责是扩展图数据负载能力(密码查询,过程等)。 只读副本的作用类似于Core Server保护的数据的缓存,但它们不是简单的键值缓存。 实际上,只读副本是功能齐全的Neo4j数据库,能够完成任意(只读)图数据查询和过程。
只读副本是通过事务日志传送从Core Servers异步复制的。 只读副本将定期(通常在ms范围内)轮询核心服务器以查找自上次轮询以来已处理的任何新事务,并且核心服务器会将这些事务发送到只读副本。 可以从相对较少的Core Server中馈送许多只读副本数据,从而使查询工作量大为增加,从而扩大规模。
但是,与核心服务器不同,只读副本不参与有关群集拓扑的决策。 只读副本通常应以相对较大的数量运行,并视为一次性使用。 丢失只读副本不会影响群集的可用性,除了丢失其图表查询吞吐量的一部分。 它不会影响群集的容错能力。
因果一致性
从应用程序的角度来看,集群的运行机制很有趣,但是考虑应用程序将如何使用数据库完成工作也很有帮助。 在应用程序中,我们通常希望从图中读取并写入图中。 根据工作负载的性质,我们通常希望从图中进行读取以考虑先前的写入,以确保因果一致性。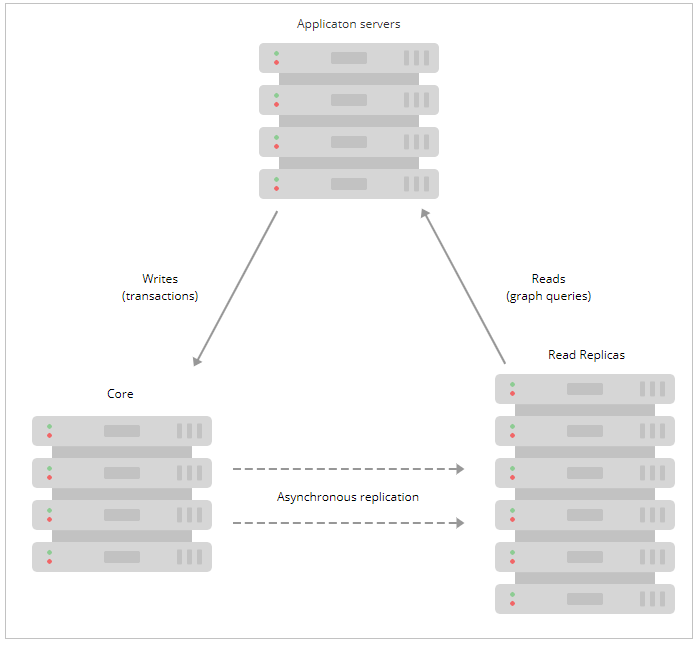
因果一致性使得可以写入Core Server(数据是安全的)并从Read Replica(其中图操作被扩展)中读取这些写入。 例如,因果一致性可确保当该用户随后尝试登录时,会出现创建该用户帐户的写操作。
在执行事务时,客户可以要求书签,然后将其作为参数提供给后续事务。 使用该书签,集群可以确保只有处理了该客户已添加书签的事务的服务器才能运行其下一个事务。 这提供了因果链,从客户的角度确保了正确的写后读语义。
除了书签之外,其他所有事情都由集群处理。 数据库驱动程序与群集拓扑管理器一起使用,以选择最合适的核心服务器和只读副本,以提供高质量的服务。
Reference
https://neo4j.com/docs/operations-manual/3.5/clustering/introduction/

