[LeetCode]287. Find the Duplicate Number 图解Floyd判圈(龟兔赛跑)算法
题目描述
LeetCode原题链接:287. Find the Duplicate Number
Given an array of integers nums containing n + 1 integers where each integer is in the range [1, n] inclusive.
There is only one repeated number in nums, return this repeated number.
You must solve the problem without modifying the array nums and uses only constant extra space.
Example 1:
Input: nums = [1,3,4,2,2] Output: 2
Example 2:
Input: nums = [3,1,3,4,2] Output: 3
Example 3:
Input: nums = [1,1] Output: 1
Example 4:
Input: nums = [1,1,2] Output: 1
Constraints:
1 <= n <= 105nums.length == n + 11 <= nums[i] <= n- All the integers in
numsappear only once except for precisely one integer which appears two or more times.
解法:快慢指针(c++版)
1 class Solution { 2 public: 3 int findDuplicate(vector<int>& nums) { 4 int fast = 0, slow = 0; 5 while(true) { 6 slow = nums[slow]; 7 fast = nums[nums[fast]]; 8 if(slow == fast) break; 9 } 10 fast = 0; 11 while(true) { 12 slow = nums[slow]; 13 fast = nums[fast]; 14 if(slow == fast) break; 15 } 16 return slow; 17 } 18 };
先上代码,这个精简的解法相信大家在各种解析评论里已经见烂了。其核心是使用Floyd判圈算法(Floyd Cycle Detection Algorithm),又称龟兔赛跑算法(Tortoise and Hare Algorithm)来找到环的入口,即那个重复的数。网友 在线疯狂 的 参考解法 里的解析已经比较详细了,但是理解起来还是稍微有点难度的(起码对于我是这样TAT...看了好几遍才看懂)。下面给出一个带图的详细解析作为补充,希望能让大家更好理解Floyd判圈算法背后的逻辑原理以及这道题目是如何和该算法挂钩的。不得不感慨一下这道题的设计,真是无巧不成题呀!
题干分析
题目告诉我们,数组中的元素范围是 [1, n] ,在该范围内如果没有重复,那应当有 n 个元素;但是给定的数组却有 n+1 个元素,这很明显说明在这些数中有且仅有一个数是重复的,即数组中的元素是由1到n范围内的所有正整数和重复的那个数构成的。对于一个有 n+1 个元素的数组,它的下标取值范围是 [0, n],等等!这里是不是觉得有点意思:给定数组下标范围是[0, n],数组中元素取值范围是[1, n] 。什么意思呢?我们可以巧妙地运用下标和元素的值来访问数组。具体来说,我们可以把数组的每一项看作是一个“任意门”,把当前位置的元素值当作是下一个要传送到的位置的下标值,比如 nums[3] = 4 就表示我们将要被传送到下标为4的位置,然后再根据 nums[4] 中存储的值决定下一次被传送的位置;进一步思考,倘若数组中有重复的元素,假设为k,那么将会有两个“任意门”可以到达 nums[k] ;把这两扇“任意门”合并成一个,是不是就能形成一个环路了呢?nums[k] 就是这个环路的入口。而对于 nums[0] 这个位置,因为数组中的元素都是 >= 1的数,因此没有任何一个“任意门”可以到达 nums[0] 位置,也就是说 nums[0] 到 nums[k] 之间是一个直线型链条,nums[0] 位置就是这个链条的起点。
把数组变成环
话不多说直接举个栗子🌰,假设给定的数组是 [1, 3, 2, 4, 7, 3, 5, 6] ,按照上面的解释,我们可以简单的画出从下标为0的位置访问这个数组时的路线:

需要补充说明的是,对于 nums[2] 这个位置的元素,没有其他任何元素可以到达它而它也只能到达自己所在的位置,所以该元素其实是不参与整个链路的构成的,可以忽略。进一步简化这个链路图,我们就能很清晰地看到,整个过程其实是一个 ρ 型环:一条链条型元素 + 一个环(形似 ρ 这个字母的样子,因此得名)。

好了,现在我们已经把这个题目转换成找 ρ 型环中环的入口了。是时候让「Floyd判圈算法」登场了!
Floyd判圈算法是个啥
一、环存在性判断
我们可以回忆一下小学时候常做的跑步应用题:两个小朋友一个跑的快,一个跑的慢,他们在400m的圆形操场上从同一起点出发赛跑,求相遇的时间。 我们注意到,这个应用题的背景或前提是在圆形赛道上,因为根据常识我们很容易知道,两者从同一位置出发速度不同,如果是在直线方向移动的话,永远不可能相遇。仿照跑步的例子,我们可以用快慢指针来检测是否有环:让两个指针从同一位置出发,以不同的速度移动,如果两者在链表头以外的某一点相遇(即相等)了,那么说明链表中存在环路;否则,如果(快指针)到达了链表的结尾则说明没环。
二、求环的长度
设相遇的点是 A 点,此时让一个指针固定在这个位置不动,另一个指针以一个单位步长向前移动,再次相遇时走过的总步数即为环的长度。
三、求环的入口
设相遇的点是 A 点,将一个指针会退到链表起点,另一个指针在相遇的点,然后同时出发,每次移动一个单位的步长,再次相遇时的位置即为环的入口。
四、数学证明
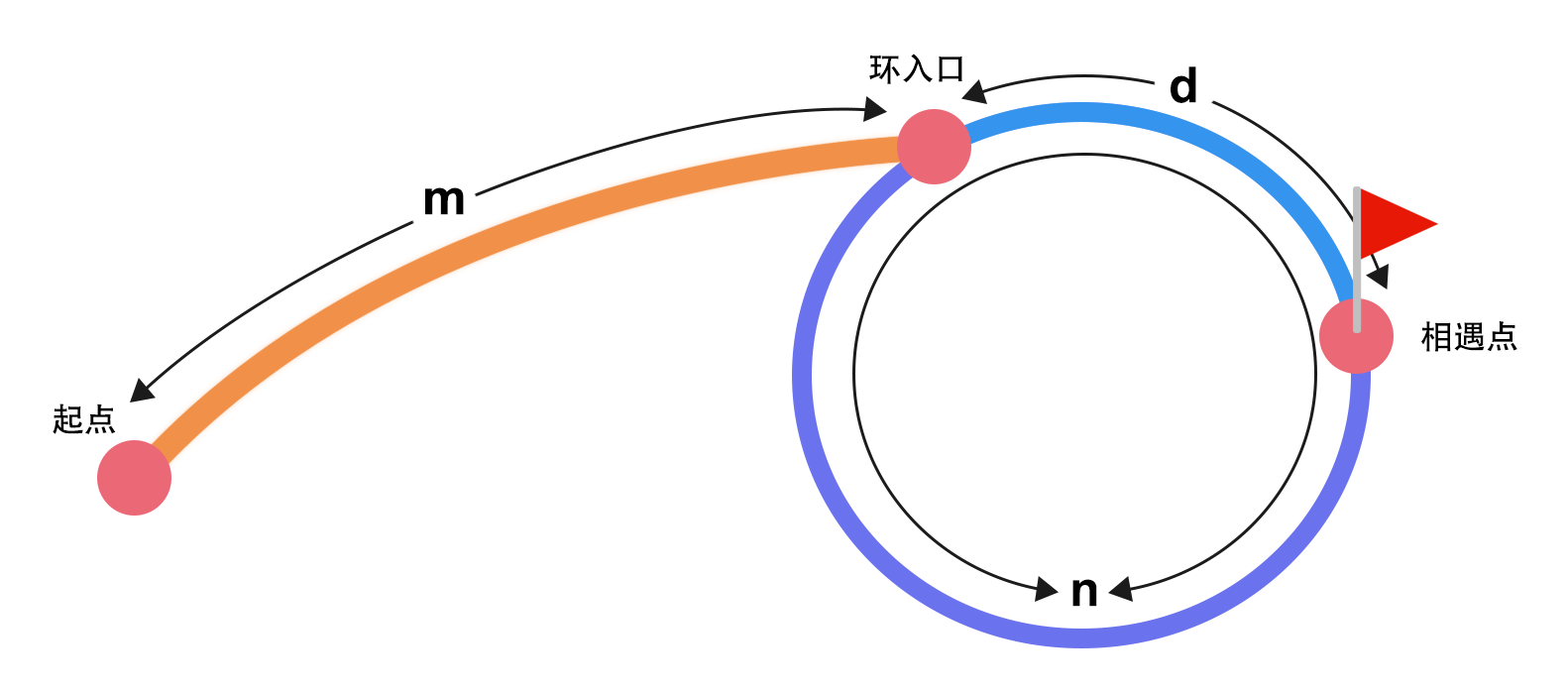
怎么证明上面的结论呢?我们来推导一下。设 ρ 型环的链条部分的长度为m,环形部分的长度为n,第一次相遇时慢指针走过的路程为X,相遇的点距离环形入口的距离为d,则有:
X = m + n * a + d (a为慢指针在环形区域转过的圈数)
如果快指针的速度是满指针的二倍,则相遇时(两者运动了相同的时间)快指针走过的路程为:
2 * X = m + n * b + d (b为快指针在环形区域转过的圈数)
两式相减,可以得到:
X = n * (b - a)
也就是说慢指针走过的路程为圈长的整数倍。
此时如果将快指针移到起点,慢指针在相遇点,两者同时向前以一个单位步长移动,当从起点出发的指针到达环入口时,其移动距离为m,而从相遇点出发的指针和起点相距 X + m;因为 X 是圈长的整数倍,所以实际该指针距离起点也为m,即位于环的入口。也就是说,两个指针再次相遇时候的位置就是环的入口。
上述推导过程就是结论三可以这么做的理论依据,至于结论二,很好理解:第一次相遇的位置一定位于环的某处,此时一个指针固定不动,另一个指针以单位步长移动,再次相遇时走过的路程必然就是环长了。
最后再来撸一遍代码
再来回头看一遍最开始给出的代码,不得不再次感慨这道题实在是太巧妙了!非常有趣~
class Solution { public: int findDuplicate(vector<int>& nums) { int fast = 0, slow = 0; // 初始化时将两个指针都放到起点 nums[0] while(true) { // 慢指针每次移动一个单位 slow = nums[slow]; // 快指针每次移动两个单位 // 相当于把下面两个语句合并成了一个: // fast = nums[fast]; // fast = nums[fast]; fast = nums[nums[fast]]; // 第一次相遇 if(slow == fast) break; } // 将其中一个指针放回起点 fast = 0; while(true) { // 两个指针每次都移动一个单位 slow = nums[slow]; fast = nums[fast]; // 第二次相遇 if(slow == fast) break; } return slow; } };

 浙公网安备 33010602011771号
浙公网安备 33010602011771号