分布式架构介绍及演进过程
什么是分布式?
互联网应用的特点是:高并发,海量数据。互联网应用的用户数是没有上限的(取决于其开放特性),这也是和传统应用的本质区别。高并发指系统单位时间内收到的请求数量(取决于使用的用户数),没有上限。海量数据包括:海量数据的存储和海量数据的处理。这两个工程难题都可以使用分布式系统来解决。
简单理解,分布式系统就是把一些计算机通过网络连接起来,然后协同工作。协同工作需要解决两个问题:
1)任务分解
把一个问题拆解成若干个独立任务,每个任务在一台节点上运行,实现多任务的并发执行。
2)节点通信
节点之间互相通信,需要设计特定的通信协议来实现。协议可以采用RPC或Message Queue等方式。
分布式和集群的关系
分布式:一个业务分拆多个子业务,部署在不同的服务器上
集群:同一个业务,部署在多个服务器上
架构的发展演变过程
一个成熟的大型网站系统架构并不是一开始就设计的非常完美,也不是一开始就具备高性能、高可用、安全性等特性,而是随着用户量的增加、业务功能的扩展逐步完善演变过来的。在这个过程中,开发模式、技术架构等都会发生非常大的变化。而针对不同业务特征的系统,会有各自的侧重点,比如像淘宝这类的网站,要解决的是海量商品搜索、下单、支付等问题;像腾讯,要解决的是数亿级别用户的实时消息传输;百度所要解决的是海量数据的搜索。每一个种类的业务都有自己不同的系统架构。我们简单模拟一个架构演变过程。
什么是大型网站
如何定义一个网站是不是大型网站,一般我们会从两个纬度去考衡,访问量以及数据量,二者缺一不可。
我们以javaweb为例,来搭建一个简单的电商系统,从这个系统中来看系统的演变历史;要注意的是,接下来的演示模型,关注的是数据量、访问量提升,网站结构发生的变化, 而不是具体关注业务功能点。其次,这个过程是为了让大家更好的了解网站演进过程中的一些问题和应对策略。
假如我们系统具备以下功能:
用户模块:用户注册和管理
商品模块:商品展示和管理
交易模块:创建交易及支付结算
阶段一 , 单应用架构
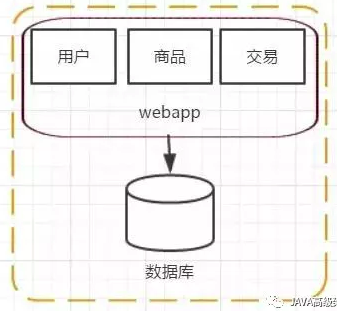
网站的初期也可以认为是互联网发展的早起,我们经常会在单机上跑我们所有的程序和软件。
把所有软件和应用都部署在一台机器上,这样就完成一个简单系统的搭建,这个时候的讲究的是效率
阶段二,应用服务器和数据库服务器分离
随着网站的上线,访问量逐步上升,服务器的负载慢慢提高,在服务器还没有超载的时候,我们应该做好规划,提升网站的负载能力。假如代码层面的优化已经没办法继续提高,在不提高单台机器的性能,增加机器是一个比较好的方式,投入产出比非常高。这个阶段增加机器的主要目的是讲web服务器和数据库服务器拆分,这样不仅提高了单机的负载能力,也提高了容灾能力

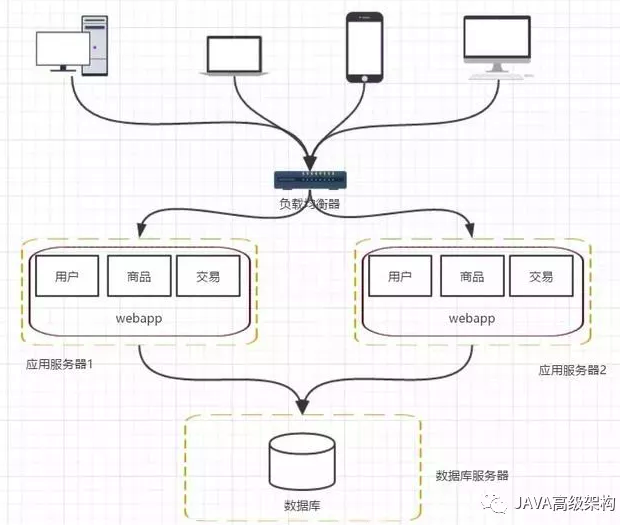
阶段三,应用服务器集群-应用服务器负载告警,如何让应用服务器走向集群
随着访问量的继续增加,单台应用服务器已经无法满足需求。在假设数据库服务器还没有遇到性能问题的时候,我们可以增加应用服务器,通过应用服务器集群将用户请求分流到各个服务器中,从而继续提升负载能力。此时多台应用服务器之间没有直接的交互,他们都是依赖数据库各自对外提供服务
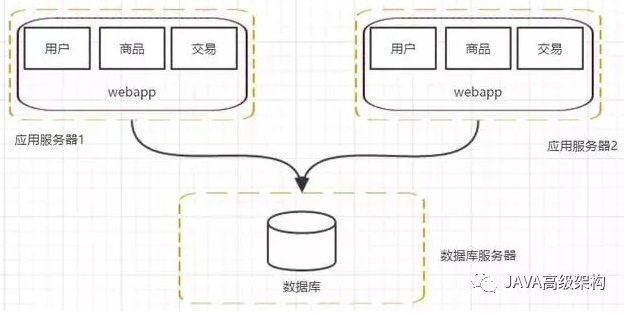
架构发展到这个阶段,各种问题也会慢慢呈现
-
用户请求由谁来转发到具体的应用服务器
-
用户如果每次访问到的服务器不一样,那么如何维护session
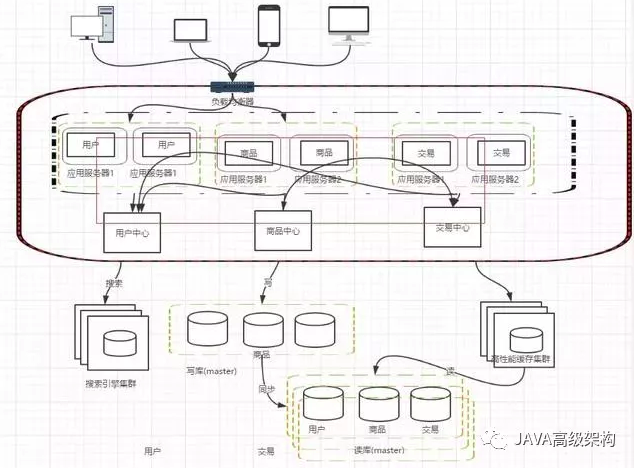
阶段四,数据库压力变大,数据库读写分离
架构演变到这里,并不是终点。上面我们把应用层的性能拉上来了,但是数据库的负载也在慢慢增大,那么怎么去提高数据库层面的负载呢?有了前面的思路以后,自然会想到增加服务器。但是假如我们单纯的把数据库一分为二,然后对于后续数据库的请求,分别负载到两台数据库服务器上,那么一定会造成数据库不统一的问题。所以我们一般先考虑读写分离的方式
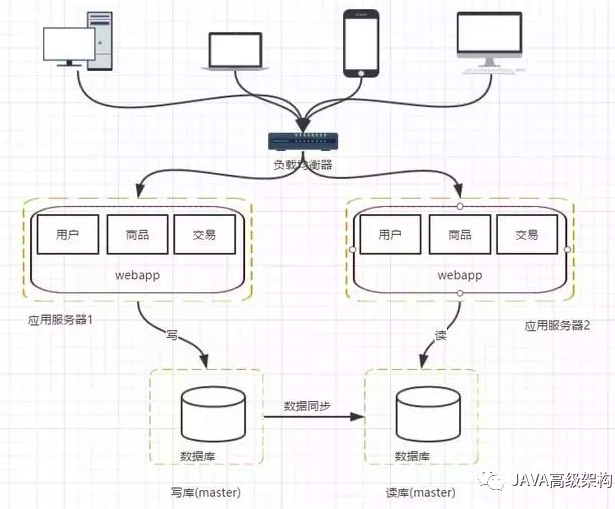
这个架构的变化会带来几个问题
-
主从数据库之间的数据同步 ; 可以使用mysql自带的master-slave方式实现主从复制
-
对应数据源的选择 ; 采用第三方数据库中间件,例如mycat
阶段五,使用搜索引擎缓解读库的压力
数据库做读库的话,尝尝对模糊查找效率不是特别好,像电商类的网站,搜索是非常核心的功能,即便是做了读写分离,这个问题也不能有效解决。那么这个时候就需要引入搜索引擎了
使用搜索引擎能够大大提高我们的查询速度,但是同时也会带来一些附加的问题,比如维护索引的构建。
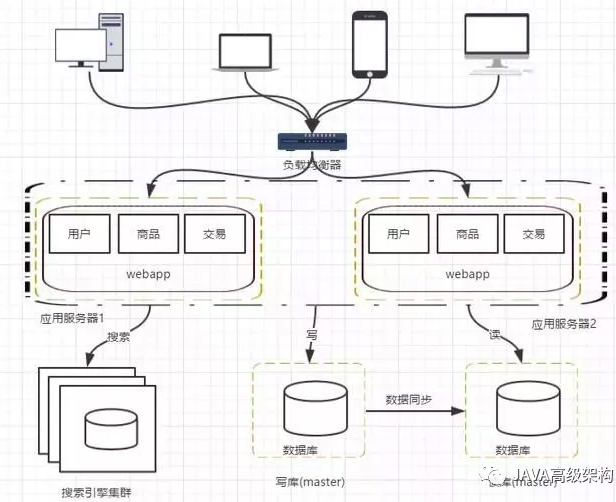
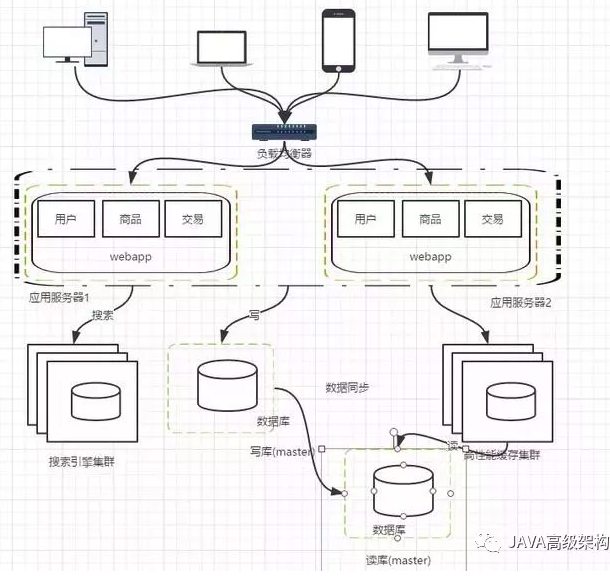
阶段六,引入缓存机制缓解数据库的压力
随着访问量的持续增加,逐渐出现许多用户访问统一部分内容的情况,对于这些热点数据,没必要每次都从数据库去读取,我们可以使用缓存技术,比如memcache、redis来作为我们应用层的缓存;另外在某些场景下,比如我们对用户的某些IP的访问频率做限制,那这个放内存中又不合适,放数据库又太麻烦,这个时候可以使用Nosql的方式比如mongDB来代替传统的关系型数据库
阶段七,数据库的水平/垂直拆分
我们的网站演进的变化过程,交易、商品、用户的数据都还在同一个数据库中,尽管采取了增加缓存,读写分离的方式,但是随着数据库的压力持续增加,数据库的瓶颈仍然是个最大的问题。因此我们可以考虑对数据的垂直拆分和水平拆分
垂直拆分:把数据库中不同业务数据拆分到不同的数据库
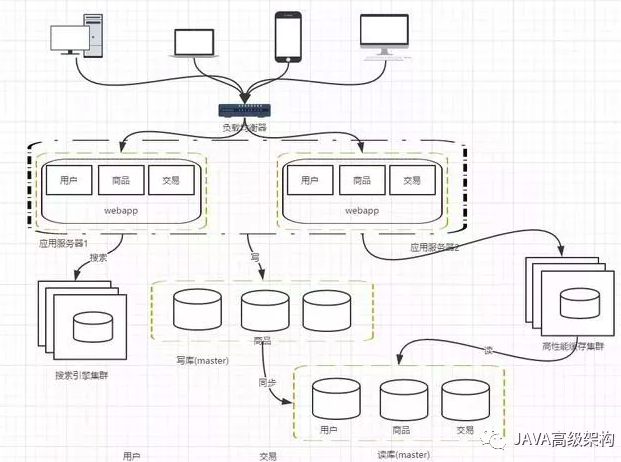
水平拆分:把同一个表中的数据拆分到两个甚至跟多的数据库中,水平拆分的原因是某些业务数据量已经达到了单个数据库的瓶颈,这时可以采取讲表拆分到多个数据库中
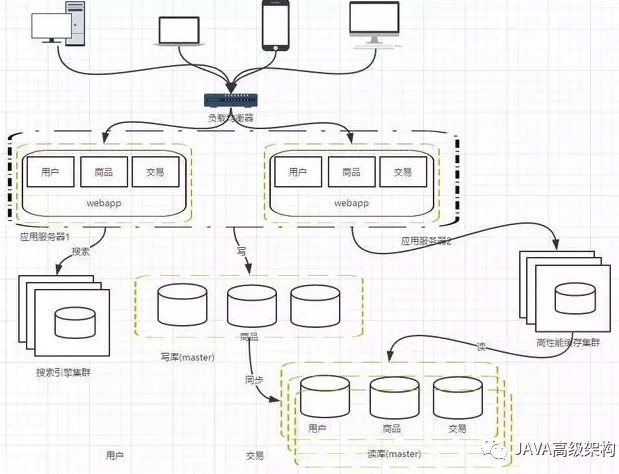
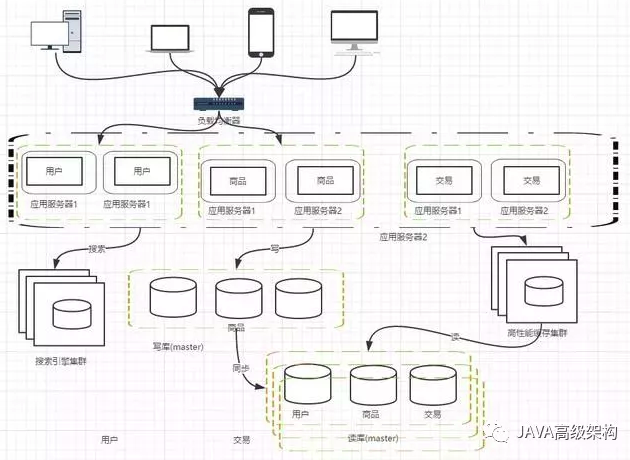
阶段八,应用的拆分
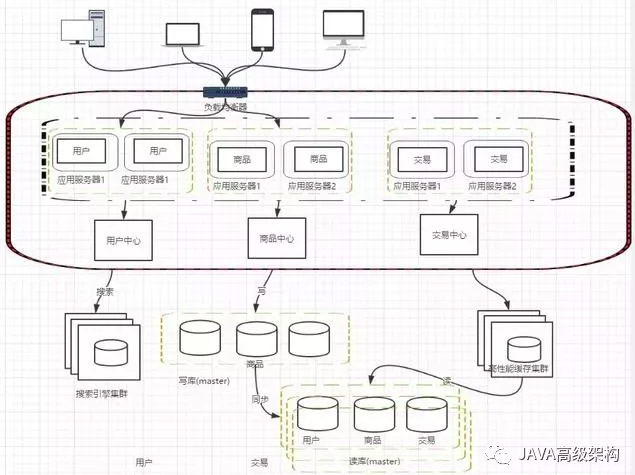
随着业务的发展,业务越来越多,应用的压力越来越大。工程规模也越来越庞大。这个时候就可以考虑讲应用拆分,按照领域模型讲我们的用户、商品、交易拆分成多个子系统
这样拆分以后,可能会有一些相同的代码,比如用户操作,在商品和交易都需要查询,所以会导致每个系统都会有用户查询访问相关操作。这些相同的操作一定是要抽象出来,否则就会是一个坑。所以通过走服务化路线的方式来解决
那么服务拆分以后,各个服务之间如何进行远程通信呢?
通过RPC技术,比较典型的有:webservice、hessian、http、RMI等等
前期通过这些技术能够很好的解决各个服务之间通信问题,but,互联网的发展是持续的,所以架构的演变和优化还在持续。