大数据基础之Benchmark(4)TPC-DS测试结果(hive/hive on spark/spark sql/impala/presto)
1 测试集群
内存:256G
CPU:32Core (Intel(R) Xeon(R) CPU E5-2640 v3 @ 2.60GHz)
Disk(系统盘):300G
Disk(数据盘):1.5T*1
2 测试数据
- tpcds parquet 10g
- tpcds orc 10g
3 测试对象
- hive-2.3.4 【set mapreduce.map.memory.mb=4096; set mapreduce.map.java.opts=-Xmx3072m;】【yarn 200g*3】
- hive-2.3.4 on spark-2.4.0 【--master yarn --driver-memory 4g --num-executors 10 --executor-memory 4g】
- spark-2.4.0 【--master yarn --driver-memory 4g --num-executors 10 --executor-memory 4g】
- impala-2.12 【MEM_LIMIT=20gb * 3】
默认配置,未经优化;
4 测试结果
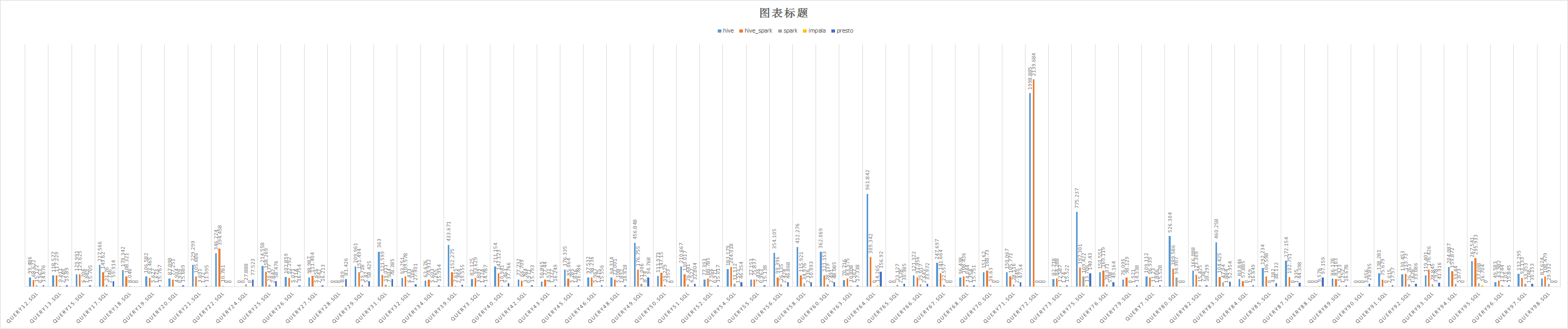
4.1 parquet
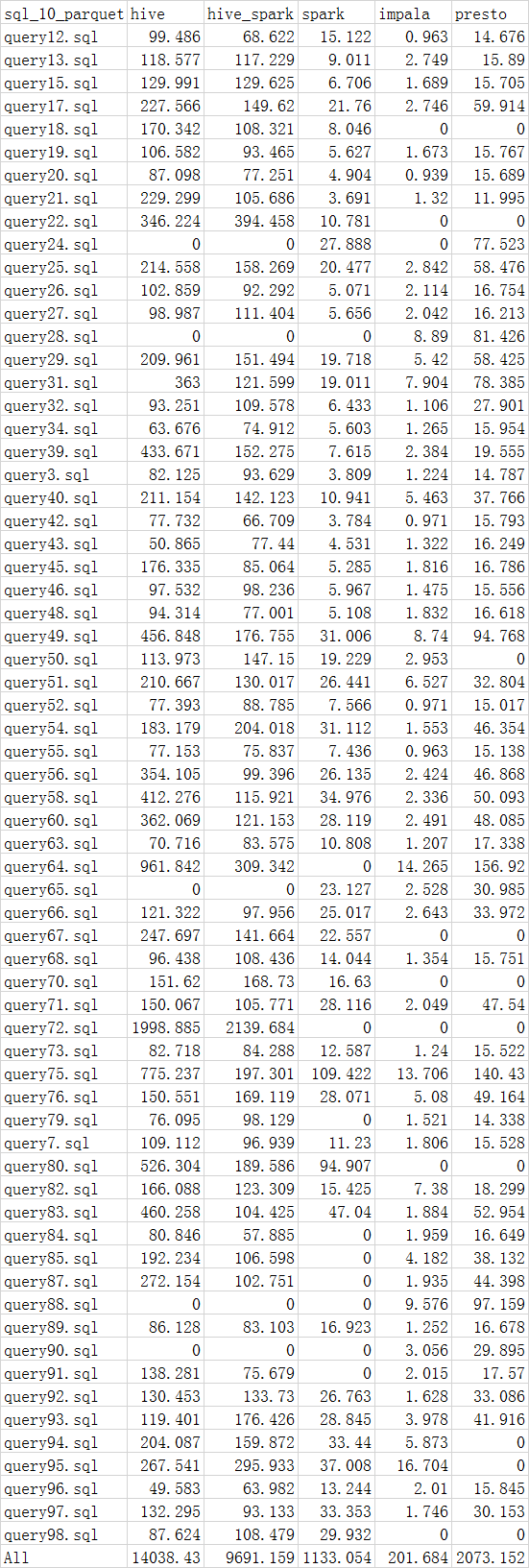
ps:0 means 执行失败
4.2 orc
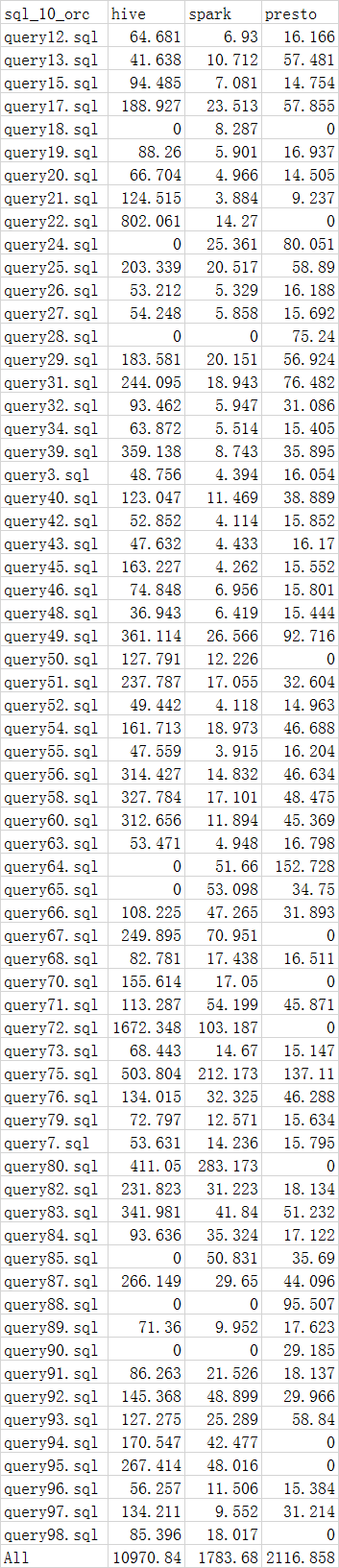
ps:0 means 执行失败
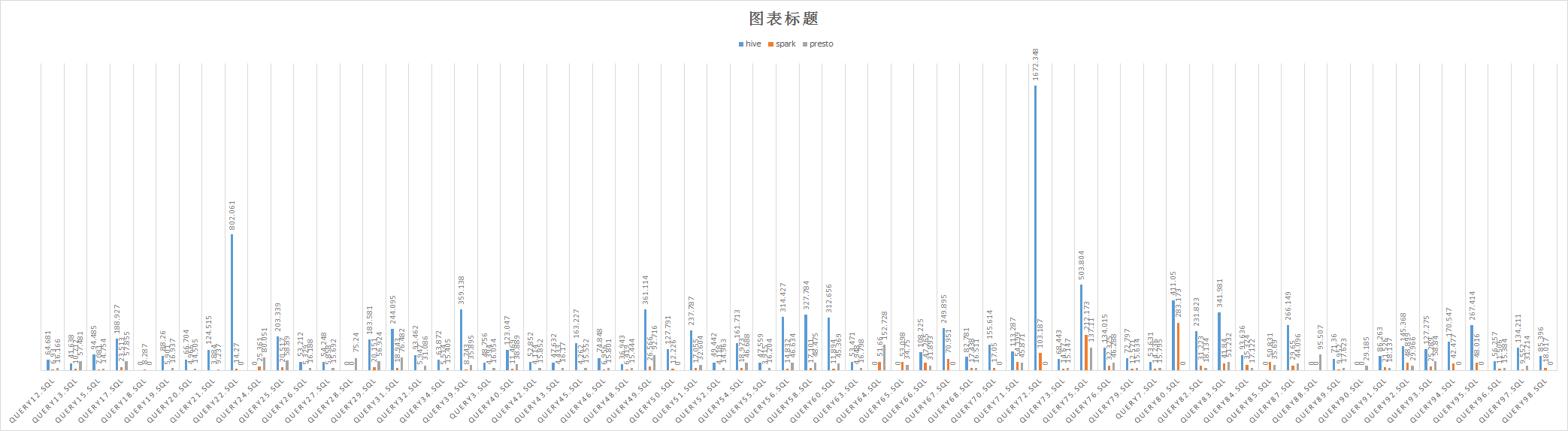
可见:
hive orc相比parquet性能提升22%;
spark parquet相比orc性能提升36%;
---------------------------------------------------------------- 结束啦,我是大魔王先生的分割线 :) ----------------------------------------------------------------
- 由于大魔王先生能力有限,文中可能存在错误,欢迎指正、补充!
- 感谢您的阅读,如果文章对您有用,那么请为大魔王先生轻轻点个赞,ありがとう

 浙公网安备 33010602011771号
浙公网安备 33010602011771号