大叔算法分享(5)聚类算法DBSCAN
一 简介
DBSCAN:Density-based spatial clustering of applications with noise
is a data clustering algorithm proposed by Martin Ester, Hans-Peter Kriegel, Jörg Sander and Xiaowei Xu in 1996.It is a density-based clustering algorithm: given a set of points in some space, it groups together points that are closely packed together (points with many nearby neighbors), marking as outliers points that lie alone in low-density regions (whose nearest neighbors are too far away). DBSCAN is one of the most common clustering algorithms and also most cited in scientific literature.
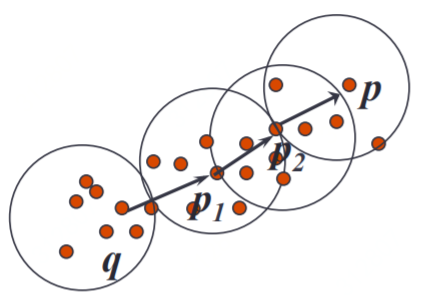
二 原理
DBSCAN是一种基于密度的聚类算法,算法过程比较简单,即将相距较近的点(中心点和它的邻居点)聚成一个cluster,然后不断找邻居点的邻居点并加到这个cluster中,直到cluster无法再扩大,然后再处理其他未访问的点;
三 算法伪代码
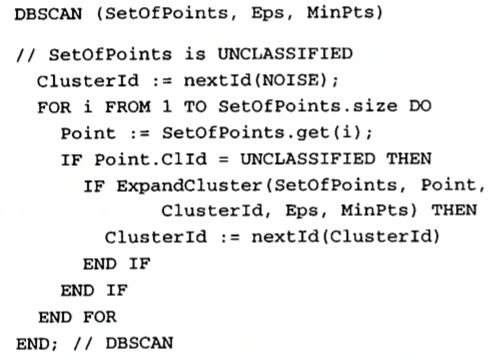
子方法伪代码

DBSCAN requires two parameters: ε (eps) and the minimum number of points required to form a dense region (minPts).
DBSCAN算法主要有两个参数,一个是距离Eps,一个是最小邻居的数量MinPts,即在中心点半径Eps之内的邻居点数量超过MinPts时,中心点和邻居点才可以组成一个cluster;
四 应用代码实现
python
示例代码
def main_fun(): loc_data = [(40.8379295833, -73.70228875), (40.750613794,-73.993434906), (40.6927066969, -73.8085984165), (40.7489736586, -73.9859616017), (40.8379525833, -73.70209875), (40.6997066969, -73.8085234165), (40.7484436586, -73.9857316017)] epsilon = 10 db = DBSCAN(eps=epsilon, min_samples=1, algorithm='ball_tree', metric='haversine').fit(np.radians(loc_data)) labels = db.labels_ print(labels) print(db.core_sample_indices_) print(db.components_) n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0) for i in range(0, n_clusters_): print(i) indexs = np.where(labels == i) for j in indexs: print(loc_data[j]) if __name__ == '__main__': main_fun()
主要结果说明
|
详见官方文档:https://scikit-learn.org/stable/modules/generated/sklearn.cluster.DBSCAN.html
scala
依赖
<dependency>
<groupId>org.scalanlp</groupId>
<artifactId>nak_2.11</artifactId>
<version>1.3</version>
</dependency><dependency>
<groupId>org.scalanlp</groupId>
<artifactId>breeze_2.11</artifactId>
<version>0.13</version>
</dependency>
示例代码
import breeze.linalg.DenseMatrix import nak.cluster.{DBSCAN, GDBSCAN, Kmeans} val matrix = DenseMatrix( (40.8379295833, -73.70228875), (40.6927066969, -73.8085984165), (40.7489736586, -73.9859616017), (40.8379525833, -73.70209875), (40.6997066969, -73.8085234165), (40.7484436586, -73.9857316017), (40.750613794,-73.993434906)) val gdbscan = new GDBSCAN( DBSCAN.getNeighbours(epsilon = 1000.0, distance = Kmeans.euclideanDistance), DBSCAN.isCorePoint(minPoints = 1) ) val clusters = gdbscan cluster matrix clusters.foreach(cluster => { println(cluster.id + ", " + cluster.points.length) cluster.points.foreach(p => p.value.data.foreach(println)) })
详见官方文档:https://github.com/scalanlp/nak
算法细节详见参考
参考:A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise
其他:
http://www.cs.fsu.edu/~ackerman/CIS5930/notes/DBSCAN.pdf
https://www.oreilly.com/ideas/clustering-geolocated-data-using-spark-and-dbscan
---------------------------------------------------------------- 结束啦,我是大魔王先生的分割线 :) ----------------------------------------------------------------
- 由于大魔王先生能力有限,文中可能存在错误,欢迎指正、补充!
- 感谢您的阅读,如果文章对您有用,那么请为大魔王先生轻轻点个赞,ありがとう

 浙公网安备 33010602011771号
浙公网安备 33010602011771号