Spark2.4-cdh6.2.1集成hudi0.10初探
一、hudi编译
1)下载0.10版本的hudi,因为cdh6..2自带spark是2.4.0版本的,需要改下代码,注释掉整个if内容,否则会报错
2)将编译完成的hudi-spark-bundle_2.11-0.10.0.jar放到spark home的jars下
# 编译
mvn clean package -DskipTests
# 移动jar到spark home
mv ./hudi-spark-bundle_2.11-0.10.0.jar ${SPARK_HOME}/jars
二、spark-shell测试
1)启动spark shell
# cdh上使用默认的spark即可,已经配置在环境变量里面了
spark-shell --packages org.apache.spark:spark-avro_2.11:2.4.4 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
# 使用其他版本的spark,例如spark-2.4.4, on yarn模式
spark-shell --master yarn-client --driver-memory 1g --num-executors 2 --executor-cores 2 --executor-memory 2g --jars ../jars/hudi-spark-bundle_2.11-0.10.0.jar --packages org.apache.spark:spark-avro_2.11:2.4.4 --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer'
2)官方测试用例
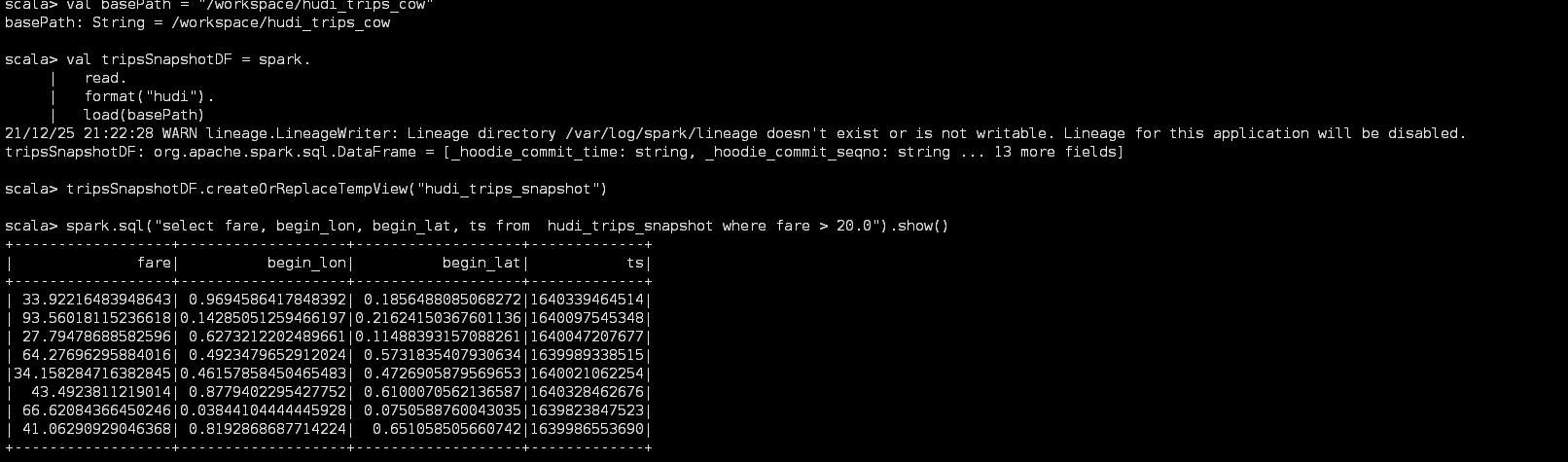
// shell中执行 import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ val tableName = "hudi_trips_cow" // 这里使用hdfs路径,不适用本地路径 // val basePath = "file:///tmp/hudi_trips_cow" val basePath = "/tmp/hudi_trips_cow" val dataGen = new DataGenerator val inserts = convertToStringList(dataGen.generateInserts(10)) val df = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) // 插入数据 df.write.format("hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option(TABLE_NAME, tableName). mode(Overwrite). save(basePath) // 查询数据 val frame: DataFrame = spark.read.format("hudi") .load(basePath) frame.show() frame.where("fare > 20.0").select("fare", "begin_lon", "begin_lat", "ts").show() frame.createOrReplaceTempView("hudi_trips_snapshot") spark.sql("select _hoodie_commit_time, _hoodie_record_key, _hoodie_partition_path, rider, driver, fare from hudi_trips_snapshot").show() // 按照时间轴进行查询 spark.read.format("hudi") .option("as.of.instant", "2021-12-24") .load(basePath)
3)Idea上测试代码,需要将编译的hudi-spark-bundle_2.11-0.10.0.jar放入自己的工程下
- pom.xml
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.shydow</groupId> <artifactId>spark-hudi-tutorial</artifactId> <version>1.0-SNAPSHOT</version> <dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.4.0-cdh6.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.0-cdh6.2.1</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_2.11</artifactId> <version>2.4.0-cdh6.2.1</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-library</artifactId> <version>2.11.12</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-avro_2.11</artifactId> <version>2.4.4</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>3.0.0-cdh6.2.1</version> </dependency> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>8.0.25</version> </dependency> </dependencies> <build> <plugins> <!-- 指定编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <!-- 指定编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> <configuration> <args> <arg>-dependencyfile</arg> <arg>${project.build.directory}/.scala_dependencies</arg> </args> </configuration> </execution> </executions> </plugin> <!-- 把依赖jar中的用到的类,提取到自己的jar中 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-assembly-plugin</artifactId> <version>2.6</version> <configuration> <descriptorRefs> <descriptorRef>jar-with-dependencies</descriptorRef> </descriptorRefs> </configuration> <!--下面是为了使用 mvn package命令,如果不加则使用mvn assembly--> <executions> <execution> <id>make-assemble</id> <phase>package</phase> <goals> <goal>single</goal> </goals> </execution> </executions> </plugin> </plugins> </build> </project>
- 测试用例
package com.shydow.Hudi import org.apache.spark.sql.{DataFrame, SparkSession} import org.apache.hudi.QuickstartUtils._ import scala.collection.JavaConversions._ import org.apache.spark.sql.SaveMode._ import org.apache.hudi.DataSourceReadOptions._ import org.apache.hudi.DataSourceWriteOptions._ import org.apache.hudi.config.HoodieWriteConfig._ /** * @author Shydow * @date 2021/12/25 15:13 * @desc Hudi写入测试: 阿里云服务器搭建的cdh需要设置hdfs-site.xml:dfs.client.use.datanode.hostname = true */ object HudiTest { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[*]") .appName("insert") .config("spark.serializer", "org.apache.spark.serializer.KryoSerializer") .enableHiveSupport() .getOrCreate() spark.sparkContext.setLogLevel("WARN") import spark.implicits._ /* 插入数据 */ // insertData(spark) /* 查询数据 */ queryData(spark, "/workspace/hudi_trips_cow") /* 按时间轴查询数据 */ queryWithTime(spark, "/workspace/hudi_trips_cow", "2021-12-24") spark.close() } /** * @param spark */ def insertData(spark: SparkSession) = { val dataGen = new DataGenerator() val inserts = convertToStringList(dataGen.generateInserts(10)) val frame: DataFrame = spark.read.json(spark.sparkContext.parallelize(inserts, 2)) frame.write.format("hudi"). options(getQuickstartWriteConfigs). option(PRECOMBINE_FIELD_OPT_KEY, "ts"). option(RECORDKEY_FIELD_OPT_KEY, "uuid"). option(PARTITIONPATH_FIELD_OPT_KEY, "partitionpath"). option("hoodie.table.name", "hudi_trips_cow"). mode(Overwrite). save("/workspace/hudi_trips_cow") } /** * @param spark * @param basePath */ def queryData(spark: SparkSession, basePath: String) = { val frame: DataFrame = spark.read.format("hudi") .load(basePath) frame.show() frame.where("fare > 20.0").select("fare", "begin_lon", "begin_lat", "ts").show() } /** * @param spark * @param basePath * @param time : "2021-07-28" -> "2021-07-28 00:00:00" * @return */ def queryWithTime(spark: SparkSession, basePath: String, time: String) = { val frame: DataFrame = spark.read.format("hudi") .option("as.of.instant", time) .load(basePath) frame.show() } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号