分布式的一些概念
一、分布式架构
1)集中式:指由一台或者多台主计算机组成的中心节点,数据其中存储在这个中心节点中,并且整个业务单元都集中部署在这个中心节点上,系统的所有功能均由其集中处理。但是由于采用单机部署,难于维护,容易发生单点故障,扩展性差;
2)分布式:一个硬件或者软件分布在不同的网络计算机上,彼此之间仅仅通过消息传递进行通信和协调系统。
二、分布式理论
1、CAP定理:指在一个分布式系统中,Consistency(一致性)、Availability(可用性)、Partition tolerance(分区容错性)这三个基本需求,最多只能满足其中两个。
一致性:指数据在多个副本之间能够保持强一致性;
可用性:系统提供的服务必须一直处于可用状态;
分区容错性:分布式系统在遇到网络故障时仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境发生故障;
2、CAP原则论证:
假设一个场景:网络中两个节点node1和node2,他们之间的网络是互通的,两个节点中分别有不同的应用程序A和B,数据库V(V数据存储的两个子数据库)。
-
-
- 在满足一致性时:node1和node2的数据是一样的,V0 = V0
- 在满足可用性时:用户不管请求node1还是node2,都能提供服务,得到响应
- 在满足分区容错性时:node1和node2任何一方宕机,或者是网络不通的时候,都不会影响node1和node2的正常运作
-
理想的场景下:node1和node2的数据库数据是完全一致的(一致性);node1和node2对于客户端请求都是正常响应的(可靠性);node1和node2之间的网络是互通的(分区容 错性)
假设node1和node2之间网络断开的时候,有用户向node1发送更新请求,则node1的数据将被更新为V1。但由于网络是断开的,node1的数据不会被同步到node2,导致node2仍然是V0,此时用户向node2发送请求,无法返回最新的数据。
此时存在两种选择:
1)牺牲一致性,保证可用性:响应旧的数据给用户
2)牺牲可用性,保证一致性:阻塞等待,直到网络恢复连接,数据更新同步之后,在返回最新数据
由此可知:要满足分区容错性的分布式系统,只能在一致性和可用性两者中,选择其一;
3、CAP权衡:由上可知,分布式系统无法满足一致性、可用性和分区容错性
1)CA:分区容错性是始终会存在的(网络是不可靠的),分布式系统更多的是允许分区后各子系统依然保持CA;
2)CP:相当于每个请求都需要在Server之间强一致,而P(分区)会导致同步时间无限延长,如此CP也是可以保证的。很多传统的数据库分布式事务都属于这种模式
3)AP:高可用且允许分区,需要放弃一致性,一旦分区发生,节点之间可能会失去联系,为了高可用,每个节点只能用本地数据提供服务,而这样会导致全局数据的不一致性。现在众多的NoSQL都属于此类。
三、2PC和3PC
1)2PC(两阶段提交):先由一方进行提议并收集其他节点的反馈,再根据反馈决定提交或者终止事务,即协调者和参与者
-
-
- phase one:协调者发起一个提议,询问各个参与者是否接收
- phase two:协调者根据参与者的反馈,提交或者中止事务,参与者全部接收则提交,其中一个或多个不同意就中止。在异步环境并且没有节点宕机的情况下,2PC是可以解决一致性问题。但如果考虑节点存在宕机的可能,2PC将不在保证一致性的问题。当协调者发出提议后宕机,此时参与者将进入阻塞状态,等待协调者回应。此时需要另一个角色辅助完成此次事件,新增的这一角色叫协调者备份(coordinator watchdog)。coordinator宕机一定时间后,watchdog接替原coordinator工作,通过问询(query) 各participant的状态,决定阶段2是提交还是中止。这也要求 coordinator/participant 记录(logging)历史状态,以备coordinator宕机后watchdog对participant查询、coordinator宕机恢复后重新找回状态。
-
2)3PC:在2PC中参与者的状态只有它本身和协调者知道,加入协调者提交后宕机,在watchdog启动之前,其中一个参与者宕机,其他的参与者将会进入既不能回滚,又不能commit的阻塞状态,知道参与者恢复。
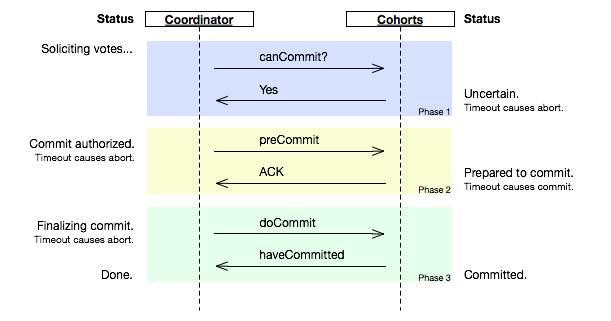
-
-
- phase one:coordinator或watchdog未收到宕机participant的vote,直接中止事务;宕机的participant恢复后,读取logging发现未发出赞成vote,自行中止该次事务
- phase two:coordinator未收到宕机participant的precommit ACK,但因为之前已经收到了宕机participant的赞成反馈(不然也不会进入到阶段2),coordinator进行commit;watchdog可以通过问询其他participant获得这些信息,过程同理;宕机的participant恢复后发现收到precommit或已经发出赞成vote,则自行commit该次事务
- phase three:即便coordinator或watchdog未收到宕机participant的commit ACK,也结束该次事务;宕机的participant恢复后发现收到commit或者precommit,也将自行commit该次事务
-

 浙公网安备 33010602011771号
浙公网安备 33010602011771号