HBase的数据模型和整体架构
一、HBase的数据模型
1)Table:表名,在创建表时需要指定列族即可,也可以指定一些数据属性、超时时间和压缩算法等;create 'test', {NAME => 'info', VERSIONS => 1, COMPRESSION => 'LZO'},name是列族,compression是压缩算法,可以是LZO,snappy,Gzip等;
2)Row:由一个rowkey和多个列组成,这些列通过列族来分类;
3)RowKey:主键,按照rowkey的字典顺序进行存储的;
4)Col Family:列族,多个列的集合;
5)Col Qualifier:列
6)Cell:每个列可以存储多个版本的数据,每个版本数据就是一个cell;
7)Region:由一个表的若干行组成,内部按照rowkey的字典顺序进行排序,当超过一定量时(默认10G)会分裂,且region是不能跨RegionServer;
二、HBase的整体架构
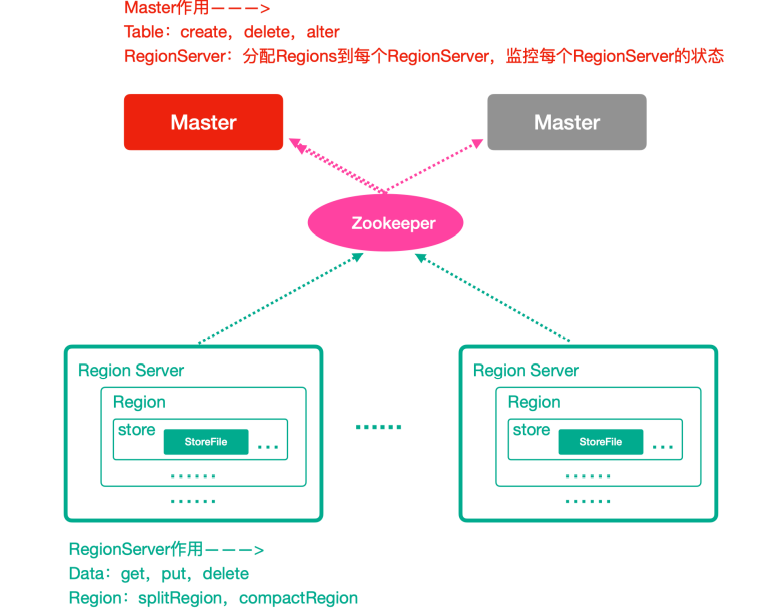
1)zookeeper:实现HMaster的HA,保存HMaster的元数据信息,是所有HBase表的寻址入口;对HMaster和RegionServer进行监控;
2)HMaster:为RegionServer分配region,保存整个集群的元数据信息;负责整个集群的负载均衡;当发现失效的region时,将其移动到正常的RegionServer上;
3)HRegionServer:负责管理Region;接收客户端的读写请求;超过一定量的Region进行分区;
4)Region:由一个或多个store组成,一个store就是一个列族,有几个列族就有几个store;每个store有一个menStore和多个storeFile组成,menStore是内存中的内容,storeFile是刷到磁盘上的文件,也就是HFile的存储格式;
三、HBase Shell
# 查看所有的表
hbase(main):004:0> list
# 创建表,table_name: t_test, 有两个列族:meta,data | 指定压缩格式为LZO | 指定VERSION表示每个单元格保留多少版本
hbase(main):004:0> create 't_test','meta','data'
hbase(main):004:0> create 't_test', {NAME='meta', COMPRESSION='lzo'},{NAME='data', COMPRESSION='lzo'}
# 插入数据 put table_name,rowkey,colFamily:colName,value
put 't_test','u000001','data:name','张三'
put 't_test','u000001','data:age','17'
put 't_test','u000001','data:address','shanghai'
# 查询数据
get 't_test','u000001'
get 't_test','u000001','data:name','data:age'
get 't_test','u000001','data','meta'
get 't_test','u000001', {FILTER => "ValueFilter(=, 'binary:wang')"}
# scan 查询所有数据
scan 't_test'
scan 't_test',{COLUMNS=>'data'}
# 范围查询:rowkey是按照字典顺序进行存储的
scan 't_test',{COLUMNS=>'data', STARTROW=>'RK1', ENDROW=>'RK2'}
# 删除数据
delete 't_test', 'rk1', 'data:age'
# 清空数据
truncate 't_test'
# 删除表
disable 't_test'
drop 't_test'
四、BlockCache重点
BlockCache也称为读缓存,HBase会将一次文件查找的Block块(默认64k)缓存到Cache中,以便后续同一请求或者邻近数据查找请求直接从内存中获取,避免昂贵的IO操作;
对于读缓存,存在两种机制:LRUBlockCache和BucketCache

 浙公网安备 33010602011771号
浙公网安备 33010602011771号