
Flume概述和内部原理
一、Flume概述
- 定义:一个分布式的、高可靠、高可用的日志采集,聚合,传输的系统;具有三个重要的组件:Source,Channel,Sink
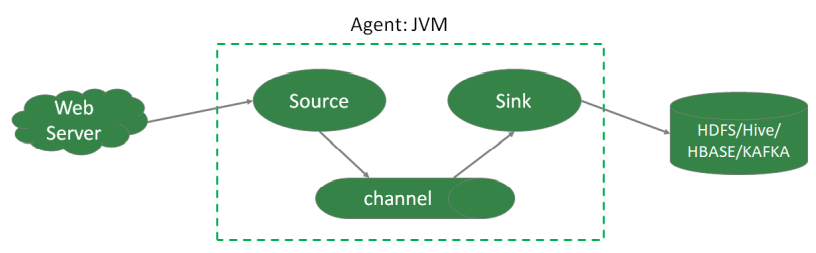
- 结构:
![]()
1)Agent:实质上是一个JVM进程,控制event数据从外部日志生产者流向指定的目的地(或者下一个Agent节点),Source负责接收数据到Agent组件,可以是exec,tail,netcat等;Channel是缓冲区,常用的的channel是memory channel和file channel,在允许数据丢失的情况下可以采用memory channel,当出现机器退出重启可能存在数据丢失;file channel会将数据写到本地磁盘,不存在数据丢失;Sink会不断的轮询channel中的数据并会批量的移除event,并批量的写入下游存储系统,Sink是完全事务的,批量任务一旦成功写入下游存储系统,就开始提交事务,事务成功,channel移除event;
2)模式
串行模式:将多个Agent连接起来,从最初的source到最终的下游的存储系统
复制模式:单Source,多channel和多sink
负载均衡模式:单Source,channel,多sink
聚合模式:将分布在不同机器上的日志汇聚起来,每台日志服务器部署一个Agent,汇集到最终的Agent上处理,流入下游存储系统
二、Flume内部原理
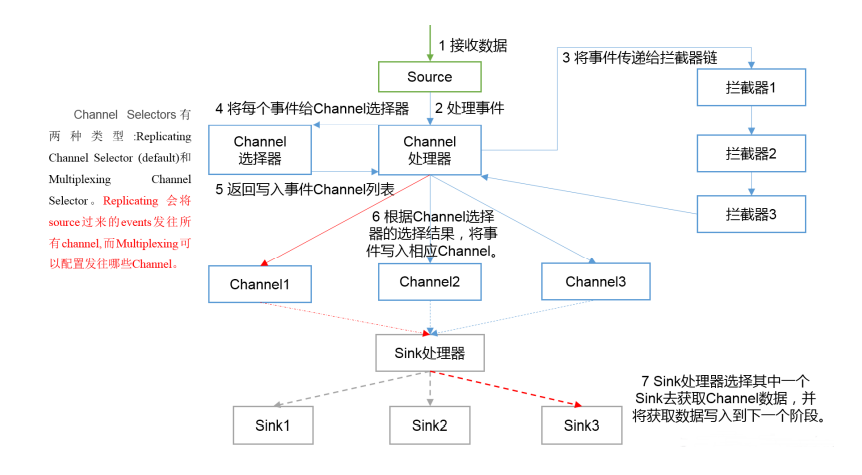
具体流程:
1)Source接收数据,交给Channel处理器进行处理event
2)处理器通过拦截器对event进行过滤清洗:比如时间拦截,分类等
3)经过拦截器处理的数据经过channel选择器,发往不同的channel;channel选择器有两种:一类Replicating Channel Selector,会将source中的event发往所有channel,能够冗余副本,提高可用性;Multiplexing Channel Selector:会根据event中header中的某个value将数据发到对应的channel
4)最后sink处理器处理每个channel中的事件
三、Flume事务机制和可靠性
在Flume中巨头Put事务和Take事务,Put事务存在Souce和Channel之间,Take事务存在于Channel和Sink之间;中间处理Flume是把数据封装成一个Event,批量进行的
Put事务:
1)事务开始会调用doput方法,将数据(也就是event)放入putList中;
2)putList在向channel发送数据时,会先检查channel的容量能否放得下,假设放不下,整批数据将会回滚;
3)数据批的大小取决于配置的batch size,putList的容量取决配置的transcation capacity,channel的容量取决于配置参数capatity
4)数据完全放入到putList中后,执行docommit方法,把putList中所有的event放入channel中,成功放完后清空putList
Take事务:
1)事务开始调用doTake方法将数据放入takeList中,如果后面接的时hdfs的sink,同时也会往hdfs的IO缓冲流中当一份数据(hdfs中数据写入先放在IO缓冲流中在flush到hdfs上)
2)当takeList的数量达到配置的batch size时执行docommit方法,将会进行两个操作:手动将IO缓冲流中数据flush到hdfs上;清空takeList的数据;在此过程中出现异常,执行回滚操作,takeList中是有备份数据的,数据重新放回channel,完成事务的回滚;
3)当将数据flush到hdfs时,数据可能flush一半后出现问题,此时已经有一半的数据已经写入hdfs了,此时也会执行回滚操作,将takeList中备份数据回写channel,继续进行读写操作,将会导致hdfs上数据重复;

 浙公网安备 33010602011771号
浙公网安备 33010602011771号