Hive架构与执行流程
- 架构
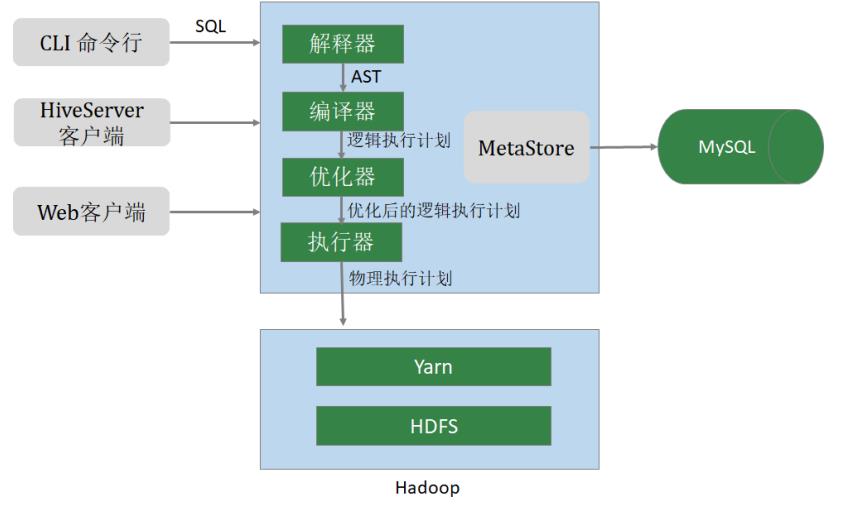
CLI用户接口:接受SQL,并返回运行结果
Thrift Server:通过JDBC或者ODBC访问hive
MetaStore:hive的元数据存储在关系型数据库中,元数据包括:数据库名,表名及类型,字段名称及数据类型,数据存储位置等
驱动程序:
解析器:使用第三方工具(antlr)将HSQL解析位抽象语法树AST,同时对抽象语法树进行check,检查字段,表是否存在,SQL是否有误等
编译器:将抽象语法树编译为逻辑执行计划
优化器:对逻辑计划进行优化,谓词下推,分区裁剪列裁剪等
执行器:将优化后的逻辑执行计划编译为物理执行计划
1、词法,语法解析:根据Antlr定义的sql语法规则,将相关sql进行词法、语法解析,转化为抽象语法树AST Tree;
2、语义解析:遍历AST,抽象出查询单元组QueryBlock:AST生成后由于其复杂度依旧较高,不便于翻译为mapreduce程序,需要进行进一步抽象和结构化为查询单元组,QueryBlock是一条SQL最基本的组成单元,包括三个部分:输入源,计算过程,输出,查询单元组可以理解为是一个子查询,AST是由多个子查询的组合,QueryBlock的生成过程为一个递归过程,先序遍历 AST,遇到不同的 标记节点,保存到相应的属性中;
3、生成逻辑执行计划:生成逻辑执行计划遍历QueryBlock,翻译为执行操作树OperatorTree;Hive最终生成的MapReduce任务,Map阶段和Reduce阶段均由OperatorTree组成;
4、优化逻辑执行计划:谓词下推,投影修剪等;
5、生成物理执行计划:生成物理执行计划即是将逻辑执行计划生成的OperatorTree转化为MapReduce Job的过程;
6、优化物理执行计划:分区,列裁剪,基于分区和桶的优化等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号