【数据采集与融合技术】第三次大作业
【数据采集与融合技术】第三次大作业
「数据采集」实验三
一、作业①
1.1 题目
-
要求:指定一个网站,爬取这个网站中的所有的所有图片,例如中国气象网(http://www.weather.com.cn)。分别使用单线程和多线程的方式爬取。(限定爬取图片数量为学号后3位)
-
输出信息:
将下载的Url信息在控制台输出,并将下载的图片存储在images子文件夹中,并给出截图。
1.2 代码及思路
单线程:3/1-1.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
多线程:3/1-2.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
1.2.1 确定要爬取的目标图片的Xpath路径
进入目标网页的【高清图集】界面如下,每张图片点击进去都是一个子网页,子网页中的图片就是我们要爬取的目标
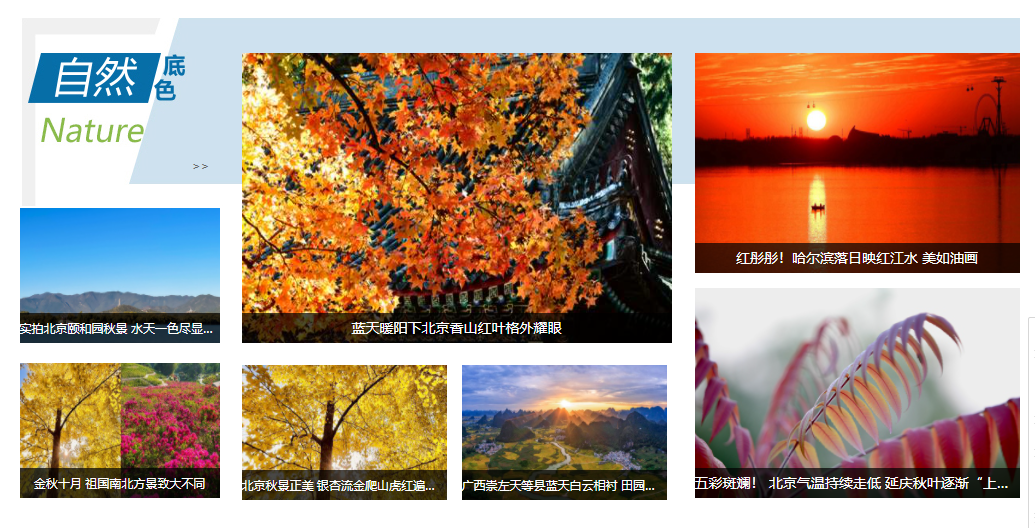
用浏览器的F12功能审查元素如下,发现一个<'li class="child"'>tag对应一张图片

因此我们的爬取思路是:先访问【高清图集】,在将这个页面下的所有子网页的链接保存下来。接着依次遍历子网页,保存每个子网页所有图片的url,最后统一下载这些图片到本地(方便计数)
1.2.2 访问【高清图集】获取子网页url
#设置起始URL和请求头
url = "http://p.weather.com.cn/"
headers = {"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47'}
#get方法发送请求报文,获取XML文档
resp = requests.get(url) # 返回resquest.Response对象
# print(resp.status_code)
# print(resp.text)
resp.encoding = 'utf-8'
demo = resp.text
soup = BeautifulSoup(demo, "lxml")
#links为【高清图集】总页面下的子链接
links=soup.select('a[href$=".shtml"][target]')
1.2.3 访问每个子页面并获取子页面下所有图片的URL
#存储图片路径的空列表
srcs_str = []
#共爬取22个子链接,每个子链接最多爬取5张图
for i in range(22):
count=0 #爬取图片计数器
pic_url=links[2*i]["href"]
#访问子链接获取子链接的XML文档
rp=requests.get(pic_url)
rp.encoding = 'utf-8'
do = rp.text
sp = BeautifulSoup(do, "lxml")
#在子链接的XML文档下搜索图片的url
pics=sp.select('img[src$=".jpg"]')
for pic in pics:
print(pic["src"])
srcs_str.append(pic["src"])
count+=1
if count==5:
break
1.2.4 单线程爬取
# 单线程保存图片到指定路径
path = r"C:\Users\qq203\Desktop\数据采集与融合技术\第三次实验\单线程"
cnt = 1
for url in srcs_str:
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % cnt + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % cnt)
if cnt == 111:
break
cnt += 1
1.2.5 多线程爬取
为每个图片设置一个线程任务,并将其设置为前台进程
def Download(path,url,c):
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % (c+1) + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % (c+1))
try:
threads=[]
c=0
for i in range(22):
#构建soup对象
count = 0
pic_url = links[2 * i]["href"]
rp = requests.get(pic_url)
rp.encoding = 'utf-8'
do = rp.text
sp = BeautifulSoup(do, "lxml")
pics = sp.select('img[src$=".jpg"]')
for pic in pics:
print(pic["src"])
url=pic["src"]
count += 1
if count == 5:
break
#新建下载线程下载图像
path=r"C:\Users\qq203\Desktop\数据采集与融合技术\第三次实验\多线程"
if c<111:
t=threading.Thread(target=Download,args=(path,url,c))
t.setDaemon(False) #设置为前台进程
t.start()
threads.append(t)
c+=1
else:
break
for thread in threads:
thread.join()
except Exception as err:
print(err)
1.3 运行结果
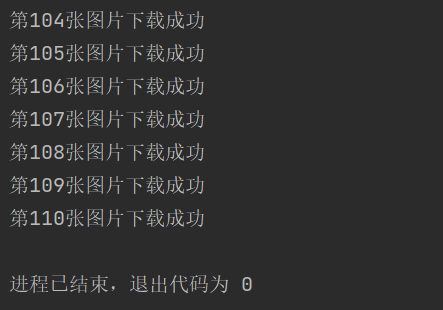
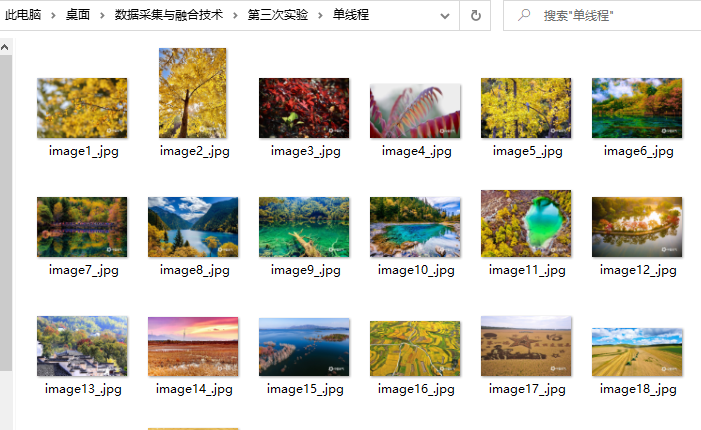
1.3.1 单线程运行结果
可以看到单线程按顺序爬取和下载,非常直观。

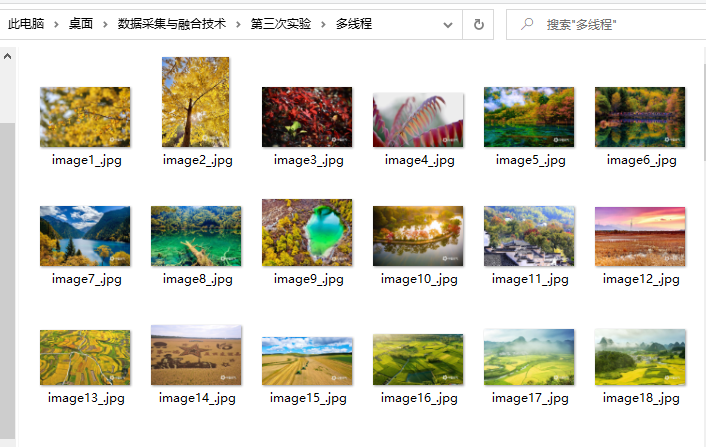
1.3.2 多线程运行结果
可以看到多线程爬取图片url和下载图片是同步进行的,所以交叉输出,且按顺序进入进程池的任务不一定按顺序执行,但最后爬取的图片总数与单线程相同。

1.4 心得体会
● 单线程简单直观,多线程速度快但需要考虑进程执行顺序的问题,并且需要进行访问控制防止对一个路径的重复写入或读出。
● 不一定要手动判断元素的Xpath路径,可以利用浏览器的F12功能实现:右键点击目标元素,选择复制,可以看到复制选项下的【复制Xpath路径】,点击即可复制目标元素的Xpath路径
二、作业②
2.1 题目
-
作业②
-
要求:使用scrapy框架复现作业①。
-
输出信息:
同作业①
-
2.2 代码及思路
总文件夹:3/demo · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
myScrapy:3/demo/demo/spiders/myScrapy.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
items:3/demo/demo/items.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
pipelines:3/demo/demo/pipelines.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
2.2.1 确定要爬取的目标图片的Xpath路径
思路同题目一,先保存【高清图集】下每个子页面的路径,再依次遍历爬取每个页面上的图片,但scrapy的默认爬虫的start_urls只有一个初始爬取路径,因此我们采用scrapy.Request()方法主动发送爬取请求,可以实现在同一个Scrapy访问多个页面
其中子页面路径的Xpath如下

2.2.2 Items-items
将每个图片视为一个项,属性只有一个url
import scrapy
class pics(scrapy.Item):
url = scrapy.Field()
2.2.3 Spider-myScrapy
翻页功能主要是在Spider实现的
设置初始url,即为【高清图集】的url
name = 'myScrapy'
allowed_domains = ['p.weather.com.cn']
start_urls = ['http://p.weather.com.cn/tqxc/index.shtml']
对start_urls调用parse方法,爬取子网页url,每爬取到一个子网页的url就用scrapy.Request(url,callback)方法爬取
def parse(self, response):
#用XML文档构建Selector对象
data = response.body.decode()
selector = scrapy.Selector(text=data)
#获取子网页链接
links = selector.xpath("//div[@class='oi']/div[@class ='tu']/a/@href")
srcs_str = []
for i in range(len(links)):
count = 0
link=links[i].extract()
yield scrapy.Request(url=link, callback=self.parse1)
对子网页的url调用parse1方法,获取子网页图片的url,将url用Item传递给pipelines
def parse1(self,response):
#用XML文档构建Selector对象
data = response.body.decode()
selector = scrapy.Selector(text=data)
#获取图片路径
pics_url=selector.xpath("//li[@class='child']/a[@class='img_back']/img/@src")
for i in pics_url:
url=i.extract()
print(url)
item=pics()
item['url']=url
yield item
2.2.4 pipelines-pipelines
对Spider传递过来的每个Item,获取其url属性,并下载目的图片存入本地。
class DemoPipeline:
def open_spider(self,spider):
self.conut = 0 #启动时初始化计数器
def process_item(self, item, spider):
import requests #用requests库下载图片
path=r"C:\Users\qq203\Desktop\数据采集与融合技术\第三次实验\Scrapy"
url=item['url']
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
with open(path + '\\image%d_' % (self.conut+1) + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % (self.conut+1))
self.conut+=1
2.3 运行结果
爬取图片到本地结果如下
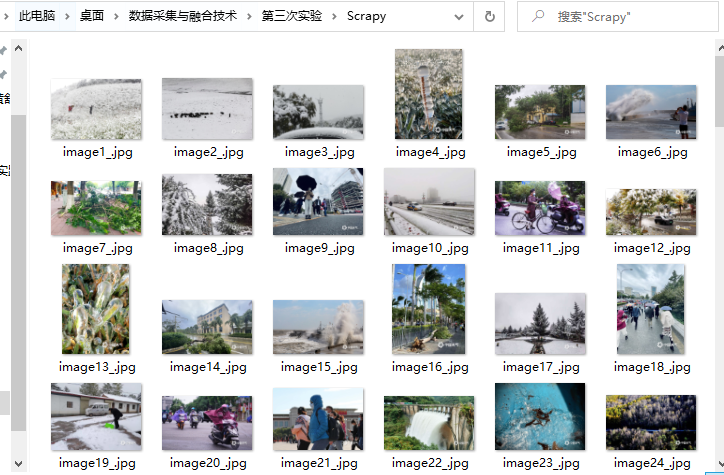
2.4 心得体会
●当需要爬取多个页面时,可以在spider的start_urls中加入多个url,项目会依次爬取,也可以主动调用scrapy.Request(url,callback)方法实现 对其他页面的访问
●可以在Settings中设置:
1、是否遵循robot协议

2、是否启用pipeline
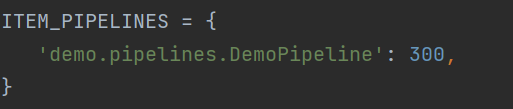
3、添加请求头和cookies

●用scrapy框架实现翻页及图片的下载更为方便,通过此次实验,我对scrapy的使用有了进一步了解。
三、作业③
3.1 题目
-
要求:爬取豆瓣电影数据使用scrapy和xpath,并将内容存储到数据库,同时将图片存储在
imgs路径下。
-
输出信息:
| 序号 | 电影名称 | 导演 | 演员 | 简介 | 电影评分 | 电影封面 |
|---|---|---|---|---|---|---|
| 1 | 肖申克的救赎 | 弗兰克·德拉邦特 | 蒂姆·罗宾斯 | 希望让人自由 | 9.7 | ./imgs/xsk.jpg |
| 2.... |
3.2 代码及思路
总文件夹:3/demo2 · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
mySpider:3/demo2/demo2/spiders/mySpider.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
items:3/demo2/demo2/items.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
pipelines:3/demo2/demo2/pipelines.py · 灰色/2019级数据采集与融合技术 - 码云 - 开源中国 (gitee.com)
3.2.1 翻页规律
在浏览器进行翻页,其中第四页如下
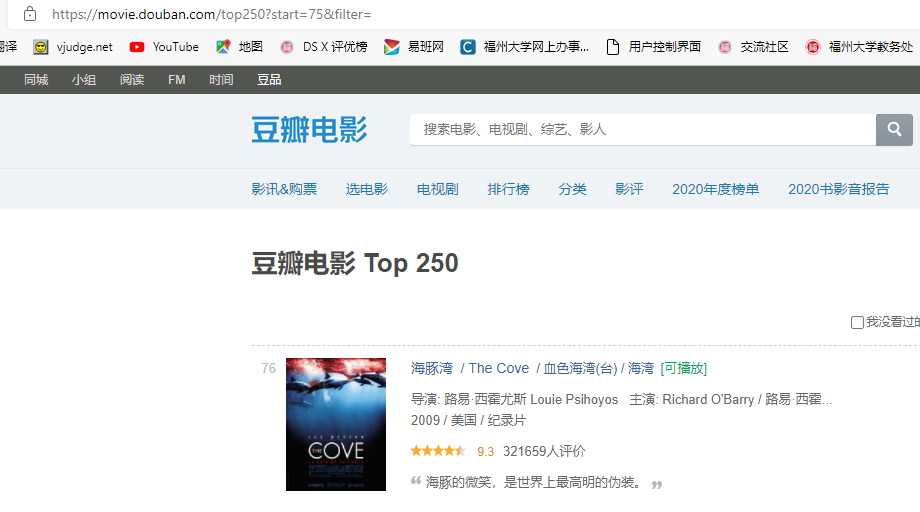
第六页如下
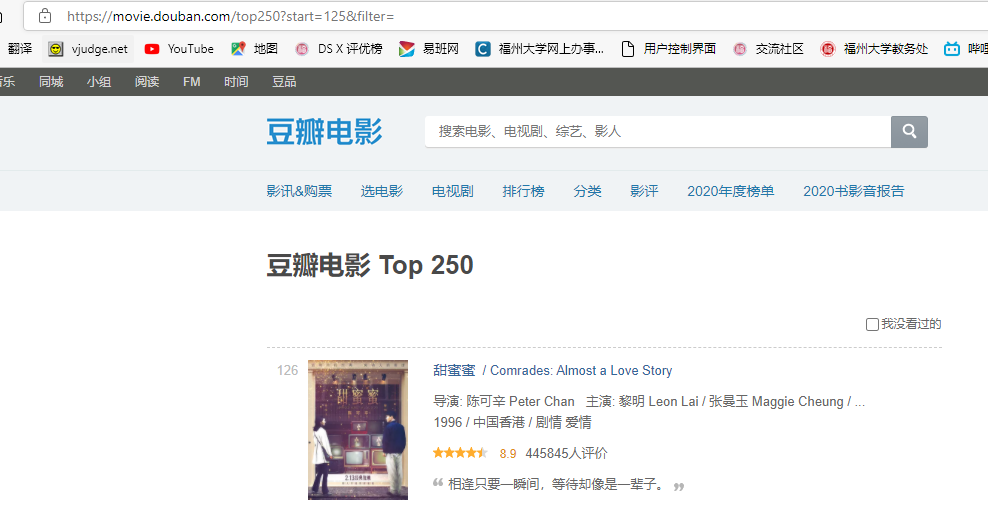
因为一页共25部电影,推断第i页url应该为"https://movie.douban.com/top250?start=(25*i)&filter="
之后观察页面源码,获取每个属性的Xpath规律,推断<'ol class="grid_view"'>下的每个<'li'>tag对应一部电影
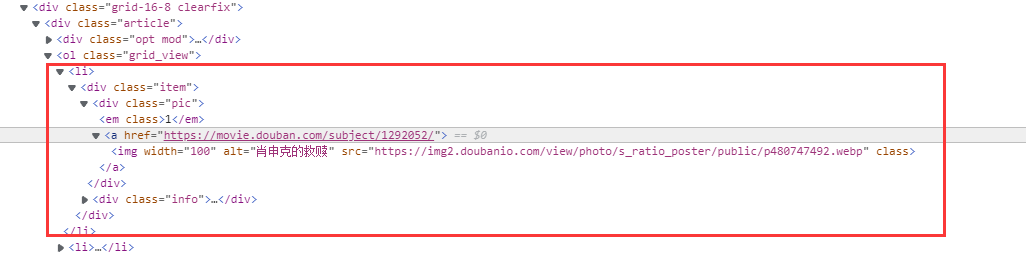
3.2.2 Items-items
一部电影对应一个Item,属性如下
import scrapy
class MovieItem(scrapy.Item):
seq=scrapy.Field() #排名
name=scrapy.Field() #电影名称
director=scrapy.Field() #导演
actors=scrapy.Field() #主演
quote=scrapy.Field() #简介
score=scrapy.Field() #评分
dyfm=scrapy.Field() #电影封面
3.2.3 Spider-mySpider
首先组织需要爬取页面的url放入start_urls
name = 'mySpider'
allowed_domains = ['movie.douban.com/top250']
url='http://movie.douban.com/top250'
start_urls=[]
for i in range(10):
if i==0:
start_urls.append(url)
else:
start_urls.append(url+"?start="+str(i * 25))
接下来依次爬取每部电影的每个属性,并将其作为Item的属性,封装好Item传给pipelines
def parse(self, response):
print(self.start_urls)
data = response.body.decode()
selector = scrapy.Selector(text=data)
print(selector)
movies=selector.xpath('//div[@id="content"]//li')
cnt=1
for movie in movies:
item=MovieItem()
#序号
item['seq']=cnt
#电影名
item['name']=movie.xpath('./div/div[@class="pic"]/a[@href]/img/@alt').extract_first()
#导演+主演
#导演和主演在同一行内
text=movie.xpath('./div/div[@class="info"]/div[@class="bd"]/p[@class]/text()').extract_first()
text=text.strip().replace('\xa0\xa0\xa0','')
item['director']=re.split(r'导演: |主演: ',text)[1]
item['actors']=re.split(r'导演: |主演: ',text)[2]
#简介
item['quote']=movie.xpath('./div/div[@class="info"]/div[@class="bd"]
/p[@class="quote"]/span/text()').extract_first()
#评分
item['score'] = movie.xpath('./div/div[@class="info"]/div[@class="bd"]/
div[@class="star"]/span[@class="rating_num"]/text()').extract_first()
#电影封面
item['dyfm']=movie.xpath('./div/div[@class="pic"]/a[@href]/img/@src').extract_first()
yield item
3.2.4 pipelines-pipelines
首先设计设计库操作类,用于创建数据库,写入数据,关闭数据库
class MovieDB:
def openDB(self):
self.con = sqlite3.connect("movies.db") #建立数据库链接,若没有对应数据库则创建
self.cursor = self.con.cursor() #建立游标
try:
self.cursor.execute("create table movies "
"(mSeq int(4),mName varchar(16),"
"mDirector varchar(32),mActors varchar(64),"
"mQuote varchar(32),mScore varchar(8),mDyfm varchar(64))")
except:
self.cursor.execute("delete from movies")
def closeDB(self):
self.con.commit()
self.con.close()
def insert(self, mSeq, mName, mDirector, mActors, mQuote, mScore, mDyfm):
try:
self.cursor.execute("insert into movies (mSeq,mName,mDirector,mActors,mQuote,mScore,mDyfm) values (?,?,?,?,?,?,?)",
(mSeq, mName, mDirector, mActors, mQuote, mScore, mDyfm))
except Exception as err:
print(err)
接着编写Demo2Pipeline类,其中open_spider函数在开始执行项目时会执行一次,创建数据库并把计数器置为1。close_spide类在结束项目时会执行一次,断开数据库链接
class Demo2Pipeline:
def open_spider(self,spider):
print("开始爬取")
self.count=1
self.db=MovieDB()
self.db.openDB()
def process_item(self, item, spider):
#下载图片
path=r"C:\Users\qq203\Desktop\数据采集与融合技术\第三次实验\demo2\imgs"
url = item['dyfm']
resp = requests.get(url) # 获取指定图片的二进制文本
img = resp.content
fm_path='imgs\image%d_' % self.count + '.jpg'
with open(path + '\\image%d_' % self.count + '.jpg', 'wb') as f:
f.write(img)
print("第%d张图片下载成功" % self.count)
self.count += 1
#保存到数据库
self.db.insert(item['seq'],item['name'],item['director'],item['actors'],item['quote'],item['score'],fm_path)
return item
def close_spider(self, spider):
self.db.closeDB()
print("结束爬取")
3.3 运行结果
数据库存储如下,其中在【简介】字段存在NULL,经过调查发现这部电影本身就没有简介



3.4 心得体会
● 爬取出现问题时,不一定是自己的代码出现问题,也可能是网页源码本身具有问题
● 我爬取了十页的内容,十页的url也可以正常输出,因此本应该有250部电影的信息,但最后只有92部电影信息,不知道为什么
● Scrapy的pipelines本质上也是多线程,所以使用全局计数器时可能会出现重复计数的问题

