11.12作业
一、词频统计
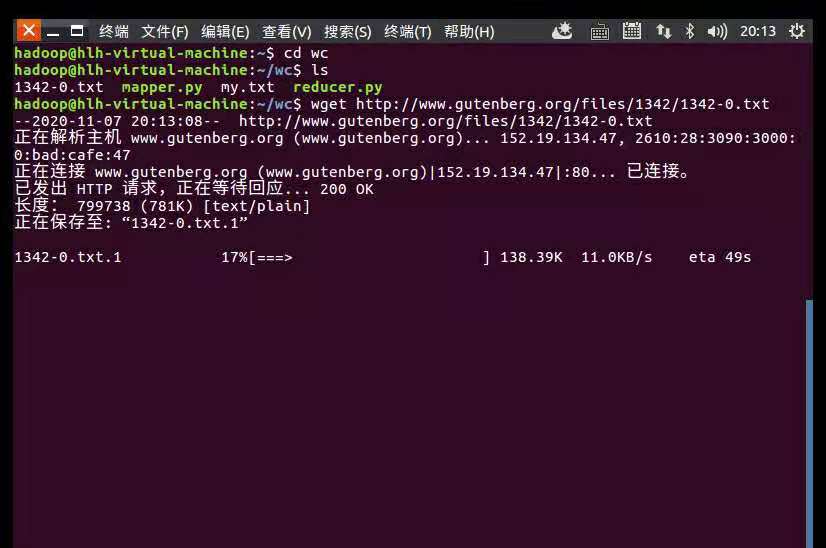
1.下载电子书
wget http://www.gutenberg.org/files/1342/1342-0.txt
下载电子书
2.编写mapper与reducer函数
mapper.py
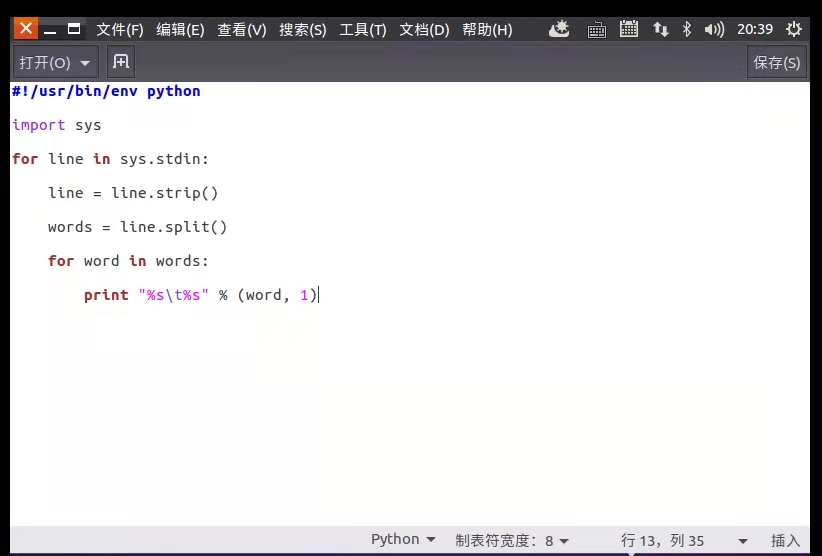
#!/usr/bin/env python
import sys
for line in sys.stdin:
line = line.strip()
words = line.split()
for word in words:
print "%s\t%s" % (word, 1)
mapper.py
reducer.py
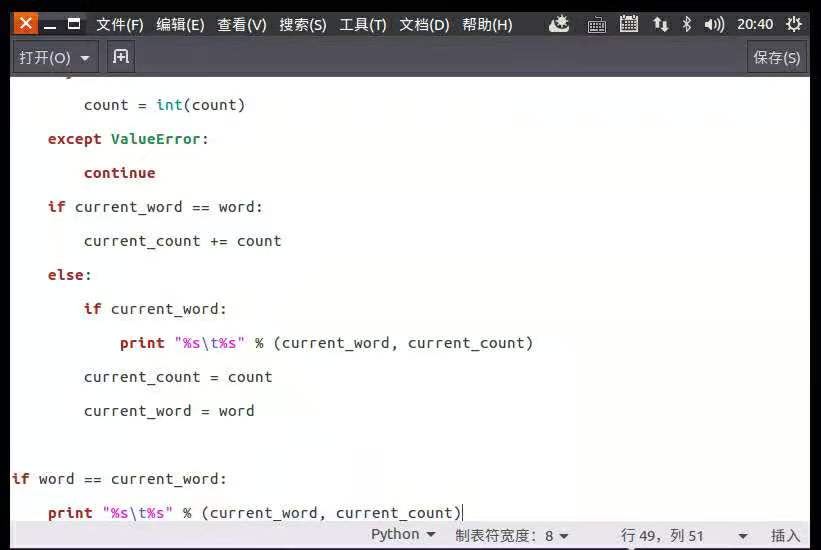
#!/usr/bin/env python
from operator import itemgetter
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
line = line.strip()
word, count = line.split('\t', 1)
try:
count = int(count)
except ValueError:
continue
if current_word == word:
current_count += count
else:
if current_word:
print "%s\t%s" % (current_word, current_count)
current_count = count
current_word = word
if word == current_word:
print "%s\t%s" % (current_word, current_count)
reduce.py
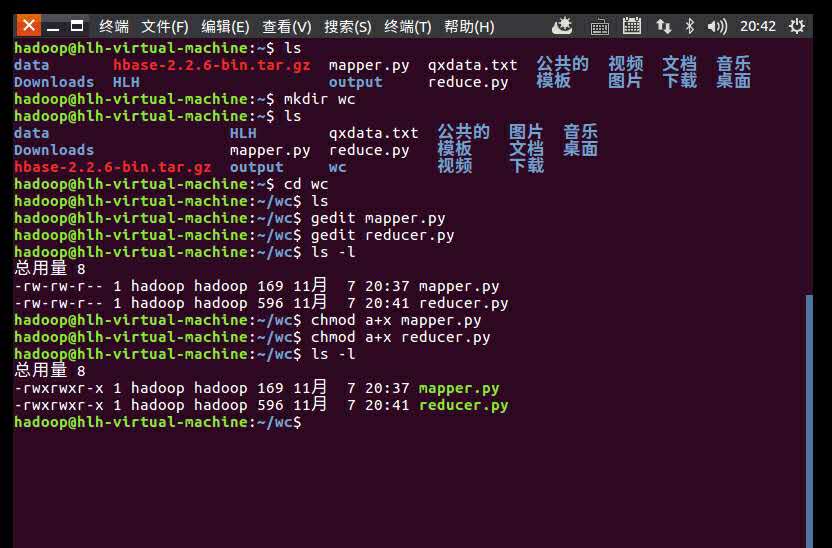
授权
ls -l
chmod a+x mapper.py
chmod a+x reducer.py
ls -l
授权
3.本地测试mapper与reducer
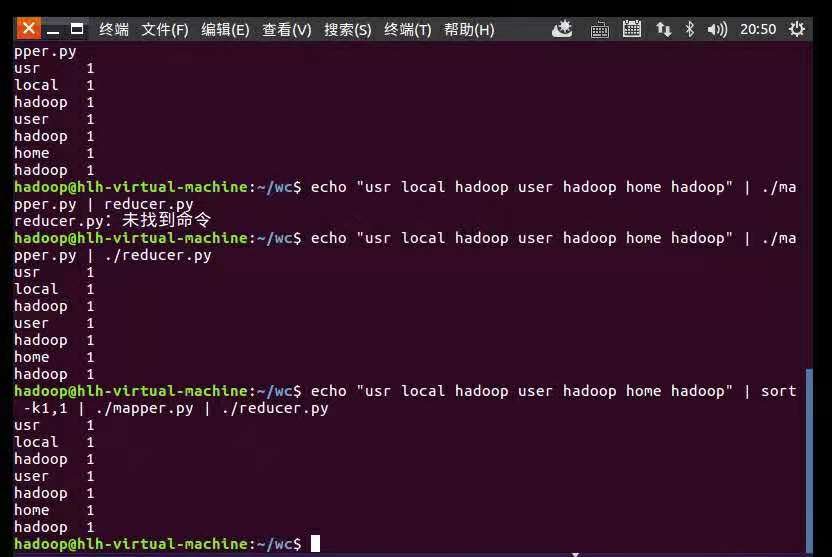
echo “usr local hadoop user hadoop home hadoop" | ./mapper.py
echo “usr local hadoop user hadoop home hadoop" | ./mapper.py | ./reducer.py
echo “usr local hadoop user hadoop home hadoop" | ./mapper.py | sort -k1,1 | ./reducer.py
本地测试
gedit my.txt
编写my.txt
cat my.txt | ./mapper.py
cat my.txt | ./mapper.py | ./reducer.py
cat my.txt | ./mapper.py | sort -k1,1 | ./reducer.py
测试my.txt
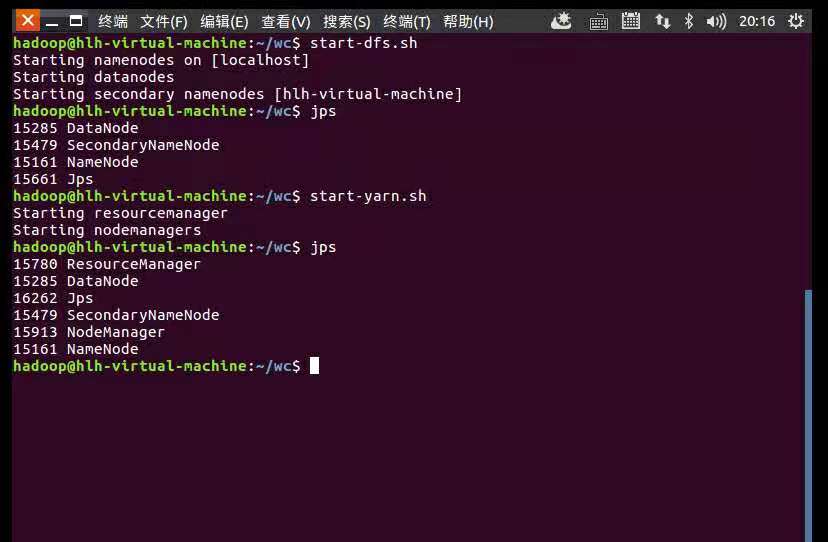
4.将文本数据上传到HDFS上
start-dfs.sh
start.yarn.sh
jps
启动Hadoop
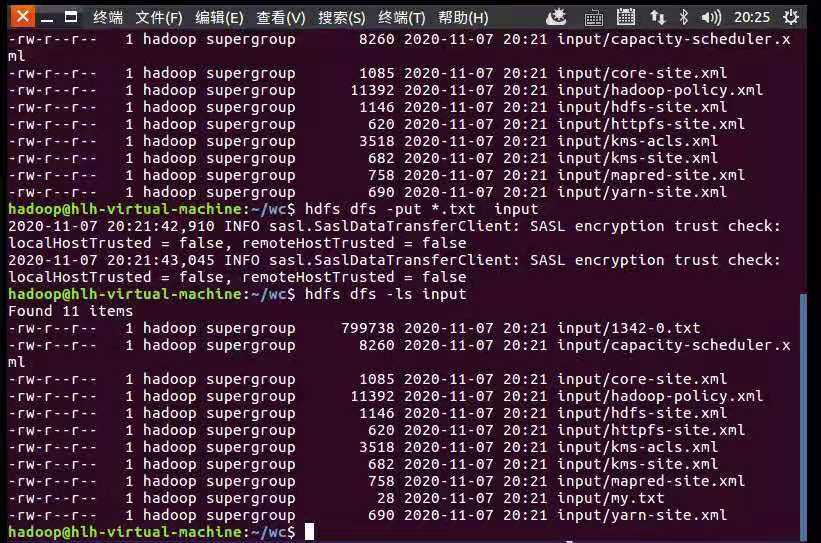
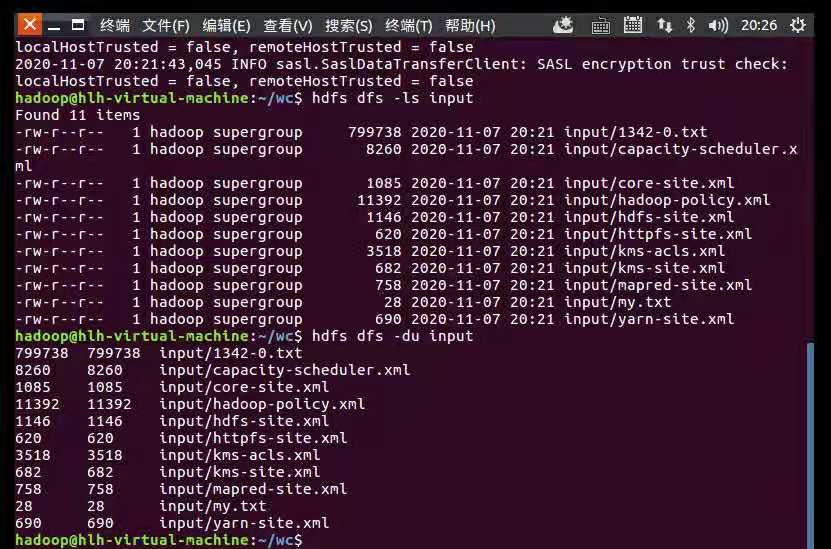
hdfs dfs -put *.txt input
hdfs dfs -ls input
hdfs dfs -du input
上传文本
查看数据大小
5.准备Hadoop streaming
配置~/.bashrc
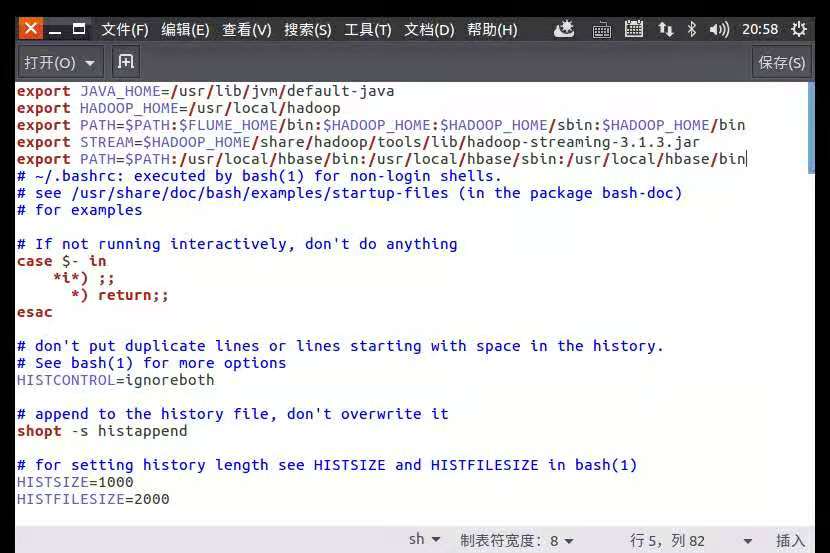
export STREAM=$HADOOP_HOME /share/hadoop/tools/lib/hadoop-streaming-3.1.3.jar
配置~/.bashrc
验证配置是否成功

验证成功
二、气象数据分析
1.下载气象数据
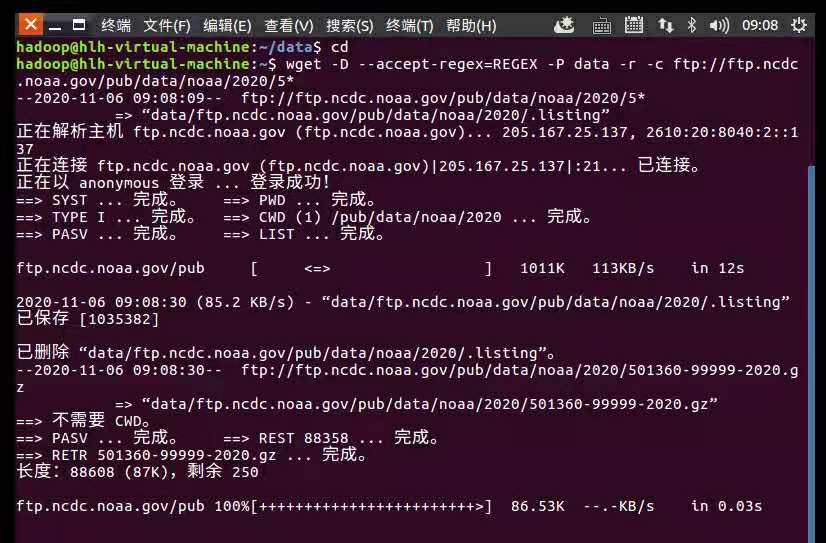
wget -D --accept-regex=REGEX -P data -r -c ftp://ftp.ncdc.noaa.gov/pub/data/noaa/2020/5*
下载气象数据
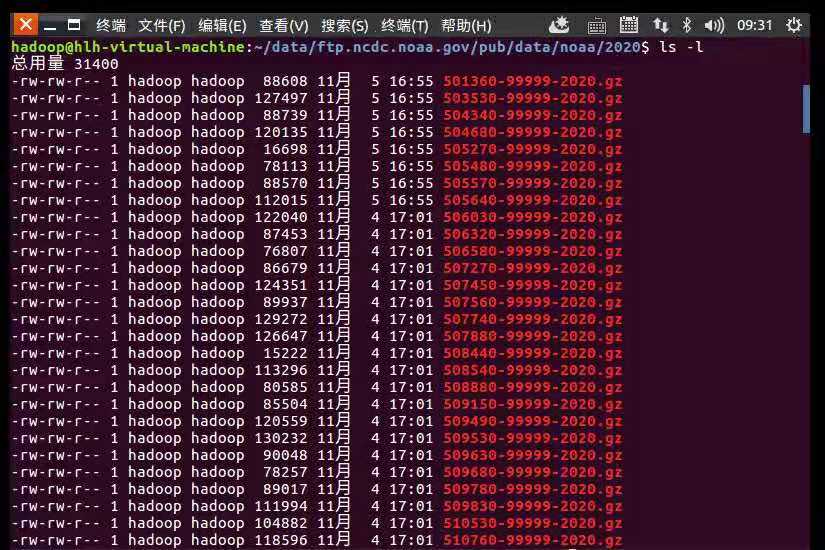
2.查看下载的气象数据文件
cd data/ftp.ncdc.noaa.gov/pub/data/noaa/2020
ls -l
查看气象数据文件
3.解压气象数据文件
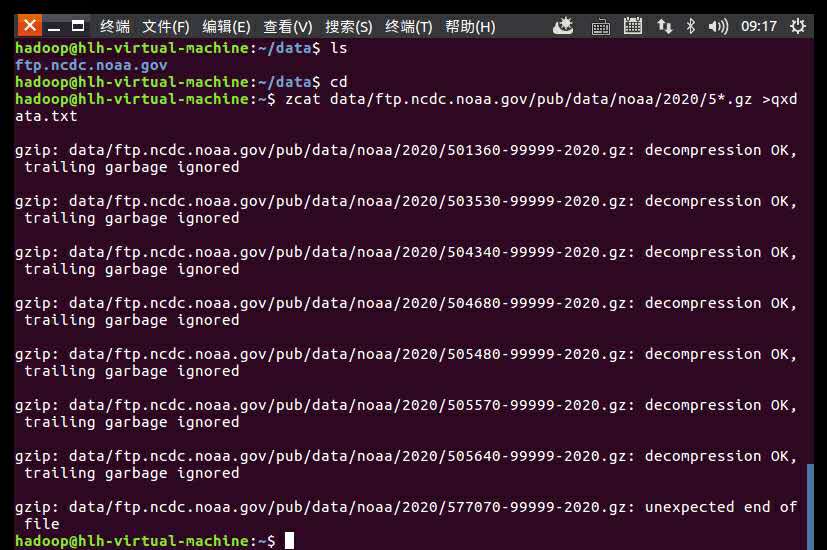
zcat data/ftp.ncdc.noaa.gov/pub/data/noaa/2020/5*.gz >qxdata.txt
解压气象数据文件
4.上传气象数据文件
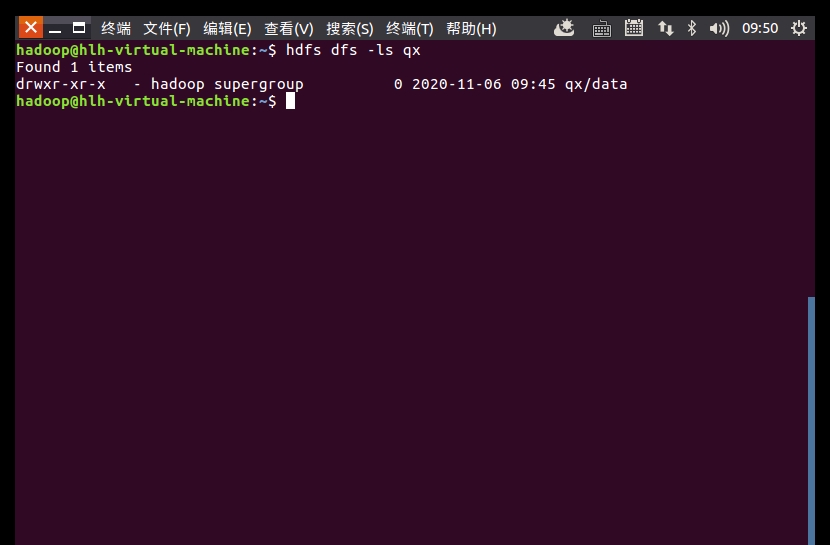
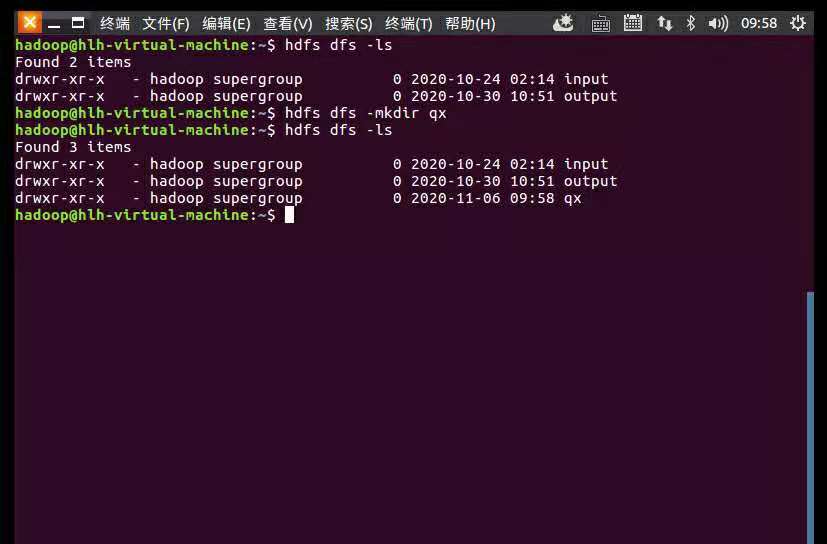
hdfs dfs -mkdir qx
hdfs dfs -put data qx
创建qx文件夹
上传气象数据文件
查看上传结果