
spring boot sharding-jdbc实现分佈式读写分离和分库分表的实现
分布式读写分离和分库分表采用sharding-jdbc实现。
sharding-jdbc是当当网推出的一款读写分离实现插件,其他的还有mycat,或者纯粹的Aop代码控制实现。
接下面用spring boot 2.1.4 release 版本实现读写分离。
1. 引入jar包
<!-- lombok -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<!-- druid -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.9</version>
</dependency>
<!-- sharding-jdbc -->
<dependency>
<groupId>com.dangdang</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>1.5.4</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
2. 添加配置文件
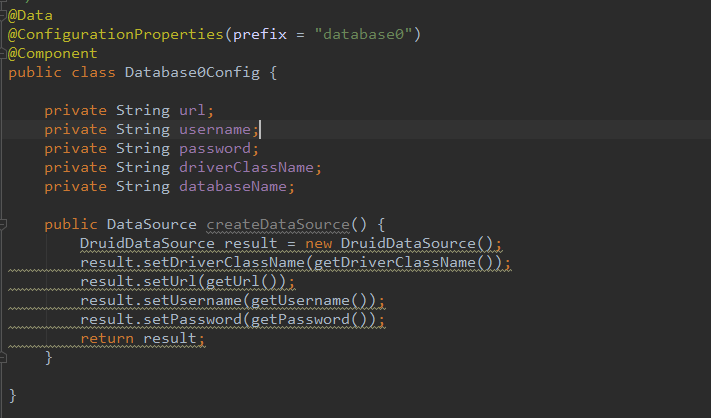
分别添加三份,配置为database0,database1,database2。
3. 添加DataSourceConfig
package com.fintecher.cn.elasticjobdemo.config;
import com.dangdang.ddframe.rdb.sharding.api.ShardingDataSourceFactory;
import com.dangdang.ddframe.rdb.sharding.api.rule.DataSourceRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.ShardingRule;
import com.dangdang.ddframe.rdb.sharding.api.rule.TableRule;
import com.dangdang.ddframe.rdb.sharding.api.strategy.database.DatabaseShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.api.strategy.table.TableShardingStrategy;
import com.dangdang.ddframe.rdb.sharding.keygen.DefaultKeyGenerator;
import com.dangdang.ddframe.rdb.sharding.keygen.KeyGenerator;
import com.fintecher.cn.elasticjobdemo.service.DatabaseShardingAlgorithm;
import com.fintecher.cn.elasticjobdemo.service.TableShardingAlgorithm;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.Arrays;
import java.util.HashMap;
import java.util.Map;
@Configuration
public class DataSourceConfig {
@Autowired
private Database1Config database1Config;
@Autowired
private Database2Config database2Config;
@Autowired
private DatabaseShardingAlgorithm databaseShardingAlgorithm;
@Autowired
private TableShardingAlgorithm tableShardingAlgorithm;
@Bean
public DataSource getDataSource() throws SQLException {
return buildDataSource();
}
private DataSource buildDataSource() throws SQLException {
//设置从库数据源集合
Map<String, DataSource> slaveDataSourceMap = new HashMap<>();
slaveDataSourceMap.put(database1Config.getDatabaseName(), database1Config.createDataSource());
slaveDataSourceMap.put(database2Config.getDatabaseName(), database2Config.createDataSource());
//设置默认数据库
DataSourceRule dataSourceRule = new DataSourceRule(slaveDataSourceMap, database1Config.getDatabaseName());
//分表设置
TableRule orderTableRules = TableRule.builder("user").actualTables(Arrays.asList("user_0", "user_1")).dataSourceRule(dataSourceRule).build();
//分库分表策略
ShardingRule shardingRule = ShardingRule.builder()
.dataSourceRule(dataSourceRule)
.tableRules(Arrays.asList(orderTableRules))
.databaseShardingStrategy(new DatabaseShardingStrategy("id", databaseShardingAlgorithm))
.tableShardingStrategy(new TableShardingStrategy("name", tableShardingAlgorithm))
.build();
//获取数据源对象
// DataSource dataSource = MasterSlaveDataSourceFactory.createDataSource("masterSlave", database0Config.getDatabaseName()
// , database0Config.createDataSource(), slaveDataSourceMap, MasterSlaveLoadBalanceStrategyType.getDefaultStrategyType());
DataSource dataSource = ShardingDataSourceFactory.createDataSource(shardingRule);
return dataSource;
}
@Bean
public KeyGenerator keyGenerator() {
return new DefaultKeyGenerator();
}
}
4. 分库实现方案
@Component
public class DatabaseShardingAlgorithm implements SingleKeyDatabaseShardingAlgorithm<Long> {
@Autowired
private Database2Config database2Config;
@Autowired
private Database1Config database1Config;
@Override
public String doEqualSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
Long value = shardingValue.getValue();
if (value <= 20L)
return database1Config.getDatabaseName();
else
return database2Config.getDatabaseName();
}
@Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
return null;
}
@Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<Long> shardingValue) {
return null;
}
}
5. 分表实现方案
@Component
public class TableShardingAlgorithm implements SingleKeyTableShardingAlgorithm<String> {
@Override
public String doEqualSharding(Collection<String> tableNames, ShardingValue<String> shardingValue) {
for (String each : tableNames) {
if (each.endsWith("0") && shardingValue.getValue().contains("军")) {
return "user_0";
} else
return "user_1";
}
return null;
}
@Override
public Collection<String> doInSharding(Collection<String> collection, ShardingValue<String> shardingValue) {
return null;
}
@Override
public Collection<String> doBetweenSharding(Collection<String> collection, ShardingValue<String> shardingValue) {
return null;
}
}
5. 环境参数配置
#jpa 配置
spring.jpa.database=mysql
spring.jpa.show-sql=true
spring.jpa.hibernate.ddl-auto=none
##数据库database0配置
database0.url=jdbc:mysql://192.168.3.32:3306/database0?characterEncoding=utf8&useSSL=false
database0.username=root
database0.password=123456
database0.driverClassName=com.mysql.jdbc.Driver
database0.databaseName=database0
##数据库database1地址
database1.url=jdbc:mysql://192.168.3.32:3306/database1?characterEncoding=utf8&useSSL=false
database1.username=root
database1.password=123456
database1.driverClassName=com.mysql.jdbc.Driver
database1.databaseName=database1
##数据库database2地址
database2.url=jdbc:mysql://192.168.3.32:3306/database2?characterEncoding=utf8&useSSL=false
database2.username=root
database2.password=123456
database2.driverClassName=com.mysql.jdbc.Driver
database2.databaseName=database2
6. 测试
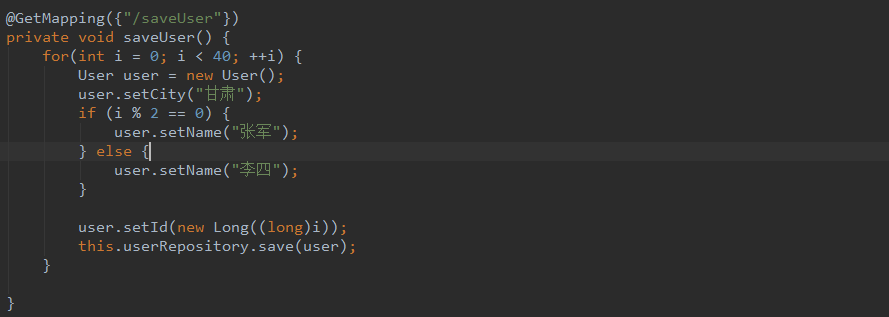
7. 达到的效果
插入40条数据,20条在base1,20条在base2,base1中张军的数据在user_0,李四的数据在user_1
8. 问题总结:
在写代码的过程中自己引包的时候很随便,引入了一些其他的包,如下:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>5.0.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.1-api</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
<version>1.11.18.RELEASE</version>
</dependency>
导致在起服务的时候报 :
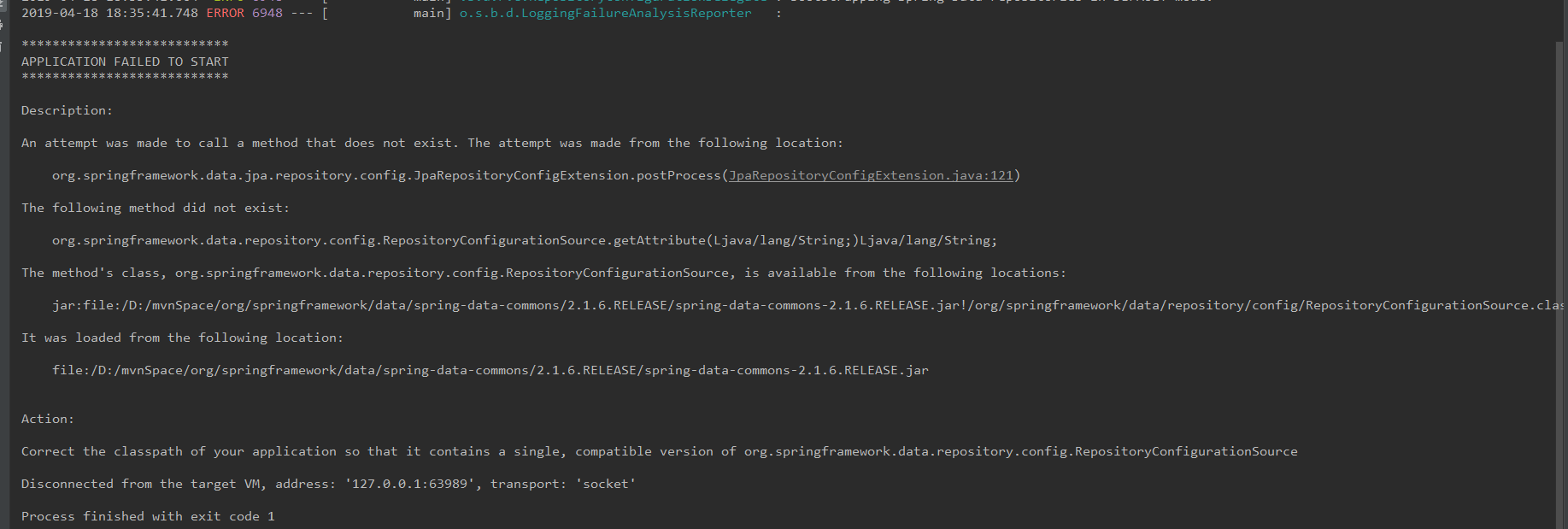
解决方案:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
将上面三个包换成这两个即可。
9. 总结
在使用sharding-jdbc过程中实现了
SingleKeyDatabaseShardingAlgorithm 这个接口,这个接口有三个方法 equal,in ,between ,这三个方法的作用是在比较传送过来的值的时候分别用这三种方案进行比较。
10. 遗留问题,当把数据库分库分表存后,查询怎么获取到所有的数据呢。
11. 参考文档:https://yq.aliyun.com/articles/690021
https://www.dalaoyang.cn/article/95?spm=a2c4e.11153940.blogcont690021.12.2057195fd9jYc3
12. 获取数据解决方案:
1. 广发复制法, 比如主表 Personal表,分别存在于多个数据库,关联表 persona_address, 只存在于主服务数据库,这种方式就是在修改了persona_address表之后将这张表再复制一份到从数据库,这样查询的时候从从数据库关联后再汇总查询。
2. 从数据库实时同步主数据库,从主数据库查询。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号