算法概述
随机森林,顾名思义就是由很多决策树融合在一起的算法,它属于Bagging框架的一种算法。
随机森林的“森林”,它的弱模型是由决策树算法训练的(CART算法),CART算法即能做回归也能做分类,“随机”是指构造的模型有一定的随机性。

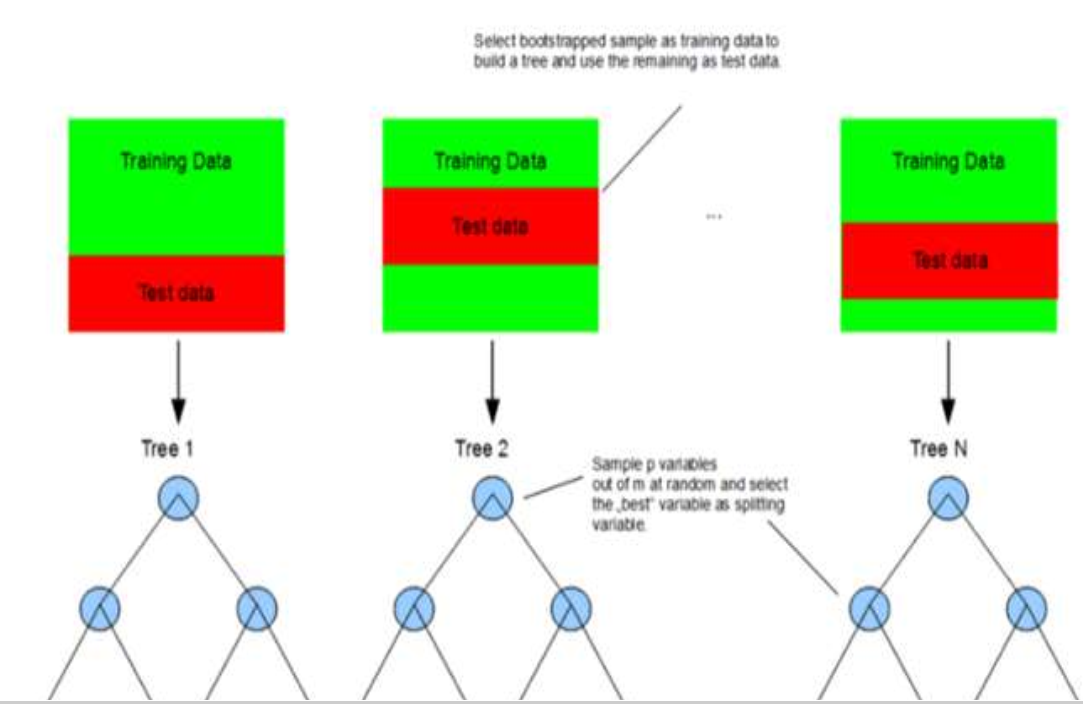
每一颗决策树模型的训练是通过自助采样法(Boostrap抽样)抽出来的,所以每一个子模型的训练样本并不是完全相同的,每一个子模型都存在一些样本不在该模型的训练集中,那些没有被该子模型抽中的样本可作为这个子模型的测试集。
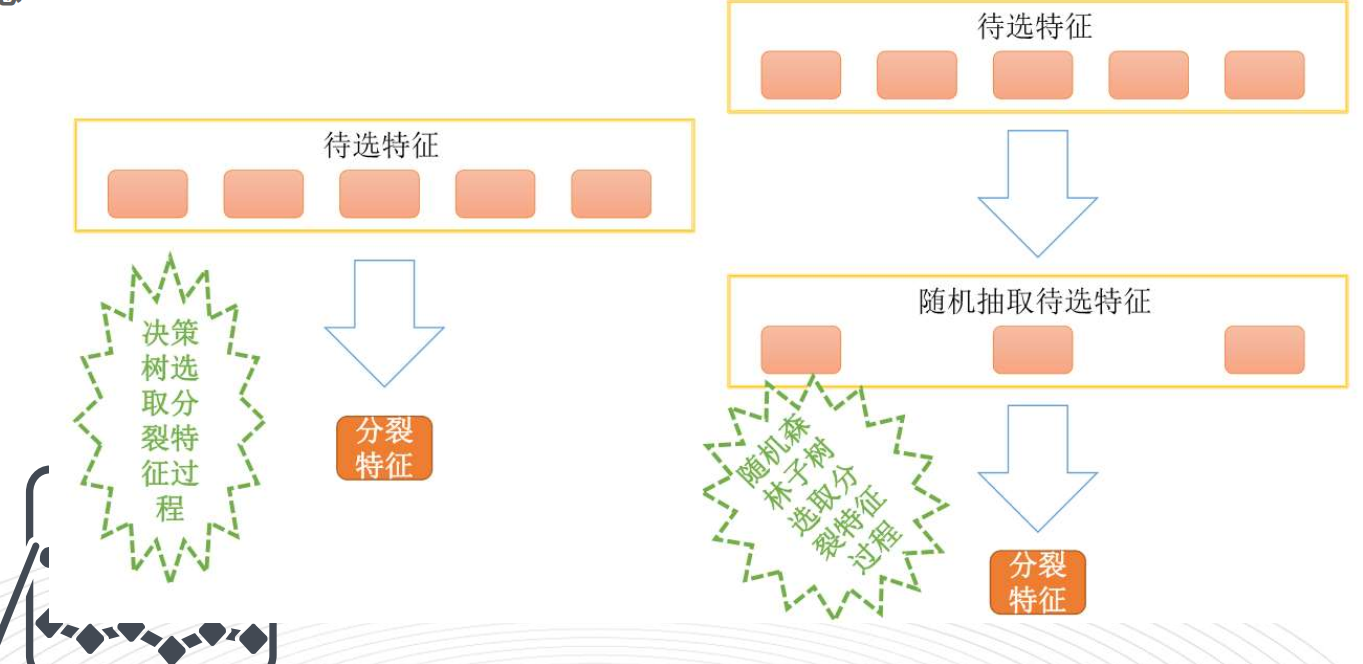
每一颗决策树模型在构建的时候并没有使用所有的特征变量,而是随机的从所有特征中抽取一个子集来训练模型,这样保证了子模型不但训练样本不完全一样,连特征变量也不完全一样,这样就很好的保证了多个子模型的随机性。
所以随机森林算法的随机性主要体现在以下两个方面:
1、子模型的训练样本是随机抽取的
2、子模型的特征变量也是随机抽取的
随机性的引入使得随机森林模型不容易陷入过拟合,具有很好的抗噪能力。而且随机性保证了各子模型间的多样性,子模型间差异越大,模型融合起来的效果会越好,如下图所示: