

0进程和线程之间的关系:
进程是负责资源分配的,线程是实际上帮你执行代码的,线程不能独立存在,必须给他分配资源
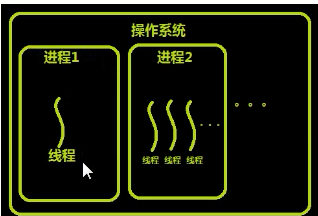
线程和进程的区别:
进程
计算机中最小的资源分配单位
数据隔离
进程可以独立独立存在
创建与销毁 还有切换 都慢 给操作系统压力大
线程
计算机中能被CPU调度的最小单位
同一个进程中的多个线程资源共享
线程必须依赖进程存在
创建与销毁 还有切换 都比进程快很多
为什么要有线程
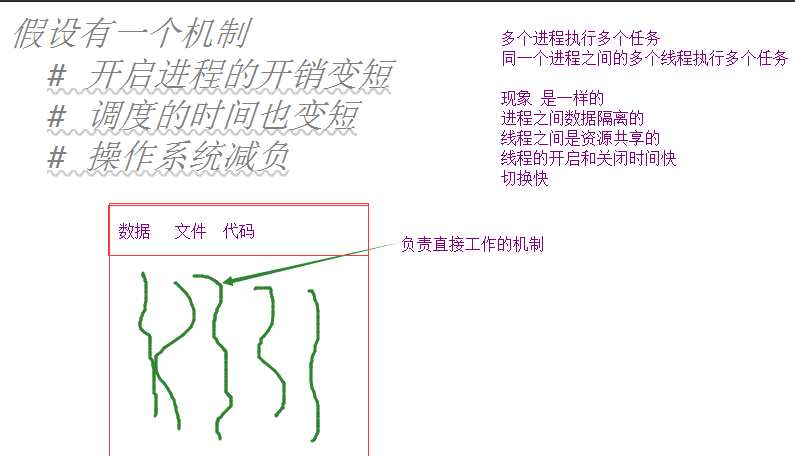
线程本身创建出来就是为了解决并发问题的,并且它的整体效率比进程要高,但是线程实际上也有一些性能上的限制\管理调度开销
在整个程序界:
如果你的程序需要数据隔离 : 多进程
如果你的程序对并发的要求非常高 : 多线程
socketserver 多线程的
web的框架 django flask tornado 多线程来接收用户并发的请求
在整个编程界:
同一个进程中的多个线程可以同时使用多个cpu

线程锁这件事儿是有Cpython解释器完成
对于python来说 同一时刻只能有一个线程被cpu访问
彻底的解决了多核环境下的安全问题
线程锁 : 全局解释器锁 GIL:
1.这个锁是锁线程的
2.这个锁是解释器提供的
threading模块
1.初识线程模块
from threading import Thread
process 进程类
Thread 线程类
2.开启多线程代码
import time from threading import Thread def func(): print('start') time.sleep(1) print('end') if __name__ == '__main__': t = Thread(target=func) t.start() for i in range(5): print('主线程') time.sleep(0.3)
说明线程和进程完全异步 说明线程开启速度更快一些
3.开启线程的另一种方式
from threading import Thread
class Mythread(Thread): def __init__(self,arg): #如果想要传参数 super().__init__() self.arg = arg
def run(self): print('in son',self.arg) t = Mythread(123) t.start()
4.进程与线程的效率对比
#线程
import time from threading import Thread def func(): n = 1 + 2 + 3 n ** 2 if __name__ == '__main__': start = time.time() lst = [] for i in range(100): #启多个线程 t = Thread(target=func) t.start() lst.append(t) for t in lst: t.join() print(time.time() - start)
#进程
import time
from multiprocessing import Process as Thread
def func():
n = 1 + 2 + 3
n**2
if __name__ == '__main__':
start = time.time()
lst = []
for i in range(100):
t = Thread(target=func)
t.start()
lst.append(t)
for t in lst:
t.join()
print(time.time() - start)
线程效率要比进程快的多
5.线程的数据共享
from threading import Thread n = 100 def func(): #子线程 global n n -= 1 t = Thread(target=func) #主线程 t.start() t.join() print(n)
在子线程减1,在主线程打印结果,仍然是减完之后的结果,意思我的全局变量对于我的子线程和主线程数据是共享的
6.threading模块中的其他功能
第一种方法
from threading import Thread,currentThread class Mythread(Thread): def __init__(self,arg): super().__init__() self.arg = arg def run(self): print('in son',self.arg,currentThread()) t = Mythread(123) t.start()
print("主:",currentThread())
我的ID不同就说明是在不同的线程里面
第二种方法
import time from threading import Thread,currentThread,activeCount,enumerate
class Mythread(Thread): def __init__(self,arg): super().__init__() self.arg = arg
def run(self): time.sleep(1) print('in son',self.arg,currentThread())
for i in range(10): t = Mythread(123) t.start() print(t.ident) print(activeCount()) print(enumerate())
7.多线程实现socket_server
server端
import socket
from threading import Thread
def talk(conn):
while True:
msg = conn.recv(1024).decode()
conn.send(msg.upper().encode())
sk = socket.socket()
sk.bind(('127.0.0.1',9000))
sk.listen()
while True:
conn,addr = sk.accept()
Thread(target=talk,args = (conn,)).start()
client端
import socket
sk = socket.socket()
sk.connect(('127.0.0.1',9000))
while True:
sk.send(b'hello')
print(sk.recv(1024))
守护线程
守护线程:
进程 terminate 强制结束一个进程的
线程 没有强制结束的方法
线程结束 : 线程内部的代码执行完毕 那么就自动结束了
import time
from threading import Thread def func(): while True: print('in func') time.sleep(0.5) def func2(): print('start func2') time.sleep(10) print('end func2') Thread(target=func2).start() t = Thread(target=func) t.setDaemon(True) t.start() print('主线程') time.sleep(2) print('主线程结束')
锁
锁是用来做什么的?
保证数据的安全的
GIL是干什么的?
锁线程
有了GIL还要锁干啥?
有了GIL还是会出现数据不安全的现象,所以还是要用锁
线程也会出现数据不安全的现象:
import time
from threading import Thread,Lock
n = 100
def func(lock):
global n
tmp = n-1 # n-=1
time.sleep(0.1)
n = tmp
if __name__ == '__main__':
l = []
for i in range(100):
t = Thread(target=func)
t.start()
l.append(t)
for t in l:t.join()
print(n)
dis模块使用
import dis
n = 1
def func():
n = 100
n -= 1
dis.dis(func)
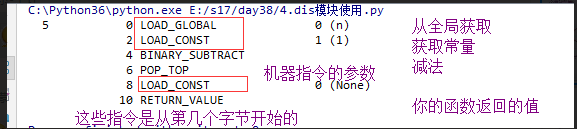
会出现线程不安全的俩种条件:
1.是全局变量
2.出现+= -= 这样的操作 l[0] +=1 d[k] +=1
列表 字典的方法 l.append l.pop l.insert dic.update 都是线程安全的
线程加锁:
import time
from threading import Thread,Lock
n = 100
def func(lock):
global n
with lock:
tmp = n-1 # n-=1
time.sleep(0.1)
n = tmp
if __name__ == '__main__':
l = []
lock = Lock()
for i in range(100):
t = Thread(target=func,args=(lock,))
t.start()
l.append(t)
for t in l:t.join()
print(n)
死锁现象
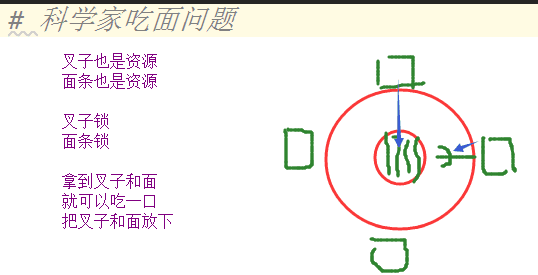
死锁问题是怎么出现的:
import time
from threading import Thread,Lock
noodle_lock = Lock()
fork_lock = Lock()
def eat1(name):
noodle_lock.acquire()
print('%s拿到面条了'%name)
fork_lock.acquire()
print('%s拿到叉子了'%name)
print('%s开始吃面'%name)
time.sleep(0.2)
fork_lock.release()
print('%s放下叉子了' % name)
noodle_lock.release()
print('%s放下面了' % name)
def eat2(name):
fork_lock.acquire()
print('%s拿到叉子了' % name)
noodle_lock.acquire()
print('%s拿到面条了' % name)
print('%s开始吃面' % name)
time.sleep(0.2)
noodle_lock.release()
print('%s放下面了' % name)
fork_lock.release()
print('%s放下叉子了' % name)
Thread(target=eat1,args=('alex',)).start()
Thread(target=eat2,args=('wusir',)).start()
Thread(target=eat1,args=('太白',)).start()
Thread(target=eat2,args=('宝元',)).start()

死锁不是时刻发生的,有偶然的情况整个程序崩溃了
每一个线程之中不止一把锁,并且套着使用容易出现死锁现象
如果某一件事情需要两个资源同时出现,那么不应该将这两个资源通过两把锁控制而应看做一个资源
解决死锁问题:
import time
from threading import Thread,Lock
lock = Lock()
def eat1(name):
lock.acquire()
print('%s拿到面条了'%name)
print('%s拿到叉子了'%name)
print('%s开始吃面'%name)
time.sleep(0.2)
lock.release()
print('%s放下叉子了' % name)
print('%s放下面了' % name)
def eat2(name):
lock.acquire()
print('%s拿到叉子了' % name)
print('%s拿到面条了' % name)
print('%s开始吃面' % name)
time.sleep(0.2)
lock.release()
print('%s放下面了' % name)
print('%s放下叉子了' % name)
Thread(target=eat1,args=('alex',)).start()
Thread(target=eat2,args=('wusir',)).start()
Thread(target=eat1,args=('太白',)).start()
Thread(target=eat2,args=('宝元',)).start()
递归锁
互斥锁
无论在相同的线程还是不同的线程,都只能连续acquire一次,要想再acquire,必须先release
递归锁
在同一个线程中,可以无限次的acquire
但是要想在其他线程中也acquire,
必须现在自己的线程中添加和acquire次数相同的release
from threading import RLock,Lock
1.递归锁
rlock = RLock() # RLock在线程中永远不会被锁住的
rlock.acquire()
rlock.acquire()
rlock.acquire()
rlock.acquire()
print('锁不住')
2.互斥锁
lock = Lock()
lock.acquire()
print('1')
lock.acquire()
print('2') #永远打印不出来
递归锁在多个线程中是怎么回事
from threading import RLock,Lock,Thread
rlock = RLock()
def func(num):
rlock.acquire()
print('aaaa',num)
rlock.acquire()
print('bbbb',num)
rlock.release() #俩次release
rlock.release()
Thread(target=func,args=(1,)).start()
Thread(target=func,args=(2,)).start() #阻塞 只有上面执行完代码后经历俩次release把钥匙还回来,才可以执行
用递归锁解决死锁问题:
import time
noodle_lock = fork_lock = RLock()
def eat1(name):
noodle_lock.acquire()
print('%s拿到面条了'%name)
fork_lock.acquire()
print('%s拿到叉子了'%name)
print('%s开始吃面'%name)
time.sleep(0.2)
fork_lock.release()
print('%s放下叉子了' % name)
noodle_lock.release()
print('%s放下面了' % name)
def eat2(name):
fork_lock.acquire()
print('%s拿到叉子了' % name)
noodle_lock.acquire()
print('%s拿到面条了' % name)
print('%s开始吃面' % name)
time.sleep(0.2)
noodle_lock.release()
print('%s放下面了' % name)
fork_lock.release()
print('%s放下叉子了' % name)
Thread(target=eat1,args=('alex',)).start()
Thread(target=eat2,args=('wusir',)).start()
Thread(target=eat1,args=('太白',)).start()
Thread(target=eat2,args=('宝元',)).start()
信号量
信号量= 锁+计数器 实现的功能
import time
from threading import Semaphore,Thread
def func(name,sem):
sem.acquire()
print(name,'start')
time.sleep(1)
print(name,'stop')
sem.release()
sem = Semaphore(5) #信号量给了你五把钥匙,五个线程可以来执行
for i in range(20):
Thread(target=func,args=(i,sem)).start()
信号量和池
进程池
有1000个任务
一个进程池中有5个进程
所有的1000个任务会多次利用这五个进程来完成任务
信号量
有1000个任务
有1000个进程/线程
所有的1000个任务由于信号量的控制,只能5个5个的执行
事件
连接数据库:
from threading import Event #Event 事件 wait() 阻塞 到事件内部标识为True就停止阻塞 import time #控制标识 set clear is_set import random from threading import Thread,Event
def connect_sql(e): count = 0 while count < 3: e.wait(0.5) if e.is_set(): print('连接数据库成功') break else: print('数据库未连接成功') count += 1 def test(e): time.sleep(random.randint(0,3)) e.set() e = Event() Thread(target=test,args=(e,)).start() Thread(target=connect_sql,args=(e,)).start()

定时器
定时器,指定n秒后执行某个操作
from threading import Timer
def func():
print('执行我啦')
t = Timer(3,func)
# 现在这个时间点我不想让它执行,而是预估一下大概多久之后它执行比较合适
t.start()
print('主线程的逻辑')
条件
wait 阻塞
notify(n) 给信号
假如现在有20个线程
所有的线程都在wait这里阻塞
notify(n) n传了多少
那么wait这边就能获得多少个解除阻塞的通知
import threading
def run(n):
con.acquire()
con.wait() #阻塞
print("run the thread: %s" % n)
con.release()
if __name__ == '__main__':
con = threading.Condition()
for i in range(10):
t = threading.Thread(target=run, args=(i,))
t.start()
while True:
inp = input('>>>')
if inp == 'q':
break
con.acquire() 输入几就有几个线程往下执行
con.notify(int(inp))
con.release()
print('****')
线程队列
queue : 线程队列,线程之间数据安全
q = queue . Queue()
#普通队列
q.get()
q.put()
q.get()
q.get_nowait() 如果有数据我就取,如果没数据不阻塞而是报错
q.put_nowait()
class queue.Queue(maxsize=0) #先进先出
import queue
q=queue.Queue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(先进先出):
first
second
third
'''
class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue
q=queue.LifoQueue()
q.put('first')
q.put('second')
q.put('third')
print(q.get())
print(q.get())
print(q.get())
'''
结果(后进先出):
third
second
first
'''
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
q=queue.PriorityQueue()
#put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高
q.put((20,'a'))
q.put((10,'b'))
q.put((30,'c'))
print(q.get())
print(q.get())
print(q.get())
'''
结果(数字越小优先级越高,优先级高的优先出队):
(10, 'b')
(20, 'a')
(30, 'c')
'''
线程池
1.介绍
concurrent.futures模块提供了高度封装的异步调用接口
ThreadPoolExecutor:线程池,提供异步调用
ProcessPoolExecutor: 进程池,提供异步调用
Both implement the same interface, which is defined by the abstract Executor class.
2.基本方法
submit(fn, *args, **kwargs) 异步提交任务
map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作
shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作
wait=True,等待池内所有任务执行完毕回收完资源后才继续
wait=False,立即返回,并不会等待池内的任务执行完毕
但不管wait参数为何值,整个程序都会等到所有任务执行完毕
submit和map必须在shutdown之前
result(timeout=None) 取得结果
add_done_callback(fn) 回调函数
1.获取结果的例子
import time import random from threading import currentThread from concurrent.futures import ThreadPoolExecutor
def func(num): print('in %s func'%num,currentThread()) time.sleep(random.random()) return num**2 tp = ThreadPoolExecutor(5) 创建五个线程 分别去执行func里的任务 ret_l = [] for i in range(30): ret = tp.submit(func,i) ret_l.append(ret) for ret in ret_l: print(ret.result())
2.shutdown 的特点 相当于close + join
import time
import random
from threading import currentThread
from concurrent.futures import ThreadPoolExecutor
def func(num):
print('in %s func'%num,currentThread())
time.sleep(random.random())
return num**2
tp = ThreadPoolExecutor(5)
ret_l = []
for i in range(30):
ret = tp.submit(func,i)
ret_l.append(ret)
tp.shutdown() # close + join
for ret in ret_l:
print(ret.result())
3.进程池和线程池只需要修改一个地方 (线程池和进程池平滑的切换)
import time
import random
from threading import currentThread
from concurrent.futures import ThreadPoolExecutor,processPoolExecutor
def func(num):
print('in %s func'%num,currentThread())
time.sleep(random.random())
return num**2
if__nmae__=="__main__":
#tp = ThreadPoolExecutor(5) 注释掉改成processPoolExecutor
tp =processPoolExecutor (5) 就变成进程池了不是线程池了
ret_l = []
for i in range(30):
ret = tp.submit(func,i)
ret_l.append(ret)
tp.shutdown() # close + join
for ret in ret_l:
print(ret.result())
3.或者另一种引入模块
import time
import random
from threading import currentThread
from concurrent.futures import ThreadPoolExecutor as Pool
# from concurrent.futures import ProcessPoolExecutor as Pool
import os def func(num): # print('in %s func'%num,currentThread()) print('in %s func'%num,os.getpid()) time.sleep(random.random()) return num**2 if __name__ == '__main__': # tp = ThreadPoolExecutor(5) tp = Pool(5) 直接用pool ret_l = [] for i in range(30): ret = tp.submit(func,i) ret_l.append(ret) tp.shutdown() # close + join for ret in ret_l: print(ret.result())
# 创建一个池
# 提交任务 submit
# 阻塞直到任务完成(close + join) shutdown
# 获取结果 result
简便用法 map
import os
def func(num): print('in %s func'%num,os.getpid()) time.sleep(random.random()) return num**2
if __name__ == '__main__': tp = Pool(5) ret = tp.map(func,range(30)) for i in ret: print(i)
回调函数 add_done_callback
def func1(num): print('in func1 ',num,currentThread()) return num*'*' def func2(ret): print('--->',ret.result(),currentThread())
tp = Pool(5) 创建线程池 print('主 : ',currentThread()) for i in range(10): tp.submit(func1,i).add_done_callback(func2) 回调函数收到的参数是需要使用result()获取的 回调函数是由谁执行的? 主线程
线程爬虫的例子
from urllib.request import urlopen
def func(name,url): content = urlopen(url).read() 打开url获取网页内容 content是一个byts类型 return name,content def parserpage(ret): name,content = ret.result() with open(name,'wb') as f: f.write(content) urls = { 'baidu.html':'https://www.baidu.com', 'python.html':'https://www.python.org', 'openstack.html':'https://www.openstack.org', 'github.html':'https://help.github.com/', 'sina.html':'http://www.sina.com.cn/' } tp = Pool(2) for k in urls: tp.submit(func,k,urls[k]).add_done_callback(parserpage)

