spark (四) RDD概念
1. RDD基本概念
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据处理模型。代码中是一个抽象类,它代表了一个弹性的、不可变的、可分区、里面的元素可并行计算的集合。
1.1 弹性
- 存储的弹性:内存和磁盘的自动切换
- 因为内存是有限制的,如果使用的内存超过了一定的阈值,会将部分数据切换到磁盘上
- 容错的弹性:数据丢失可以自动回复
- 计算的弹性:计算出错重试机制
- 分片的弹性:可以根据需求重新分片
1.2 分布式
- 数据存储在大数据集群的不同节点上
1.3 数据集
- RDD封装了计算逻辑,并不保存数据
1.4 数据抽象
- RDD是一个抽象类,具体需要子类来实现
1.5 不可变
- RDD封装了计算逻辑,是不可以改变的。想要改变只能产生新的RDD,在新的RDD里面封装计算逻辑(装饰器)
1.6 可分区、并行计算
RDD是一个逻辑上虚拟的集合,内部会拆分成多个partition 的 task,分配给executor
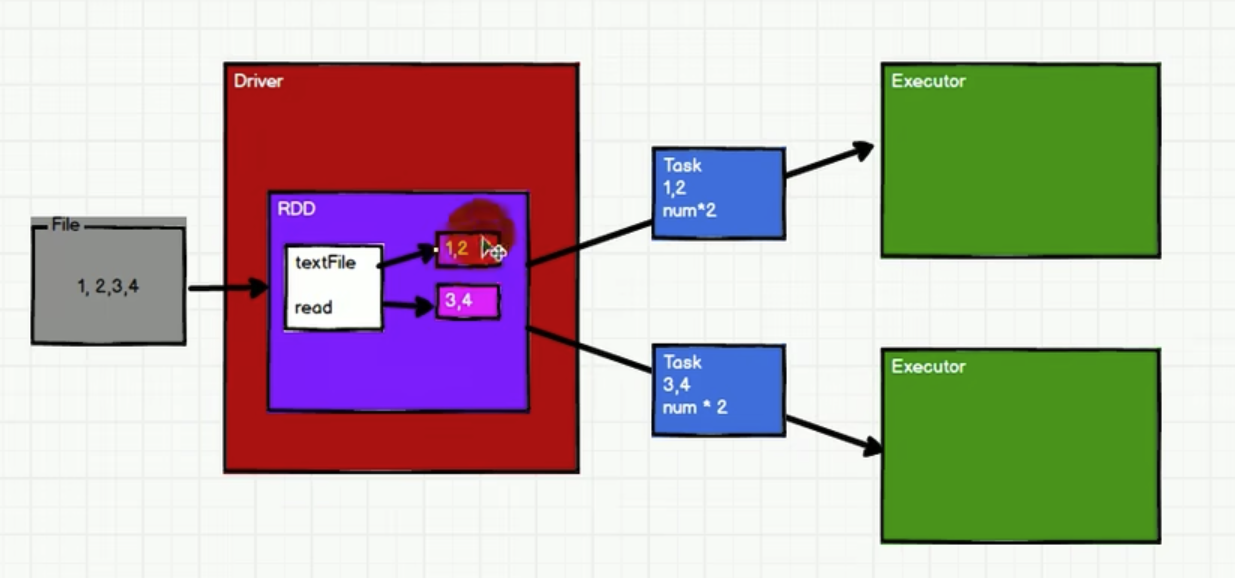
2. WordCount为例,看RDD特性
- RDD的数据处理方式类似于IO流,也有装饰者模式
- RDD的数据只有在调用
collect方法时,才会真正执行业务逻辑的计算操作,前面都是在叠buff - 与IO流能暂时缓存一部分数据(缓冲区)不同,RDD中间不缓存任何数据
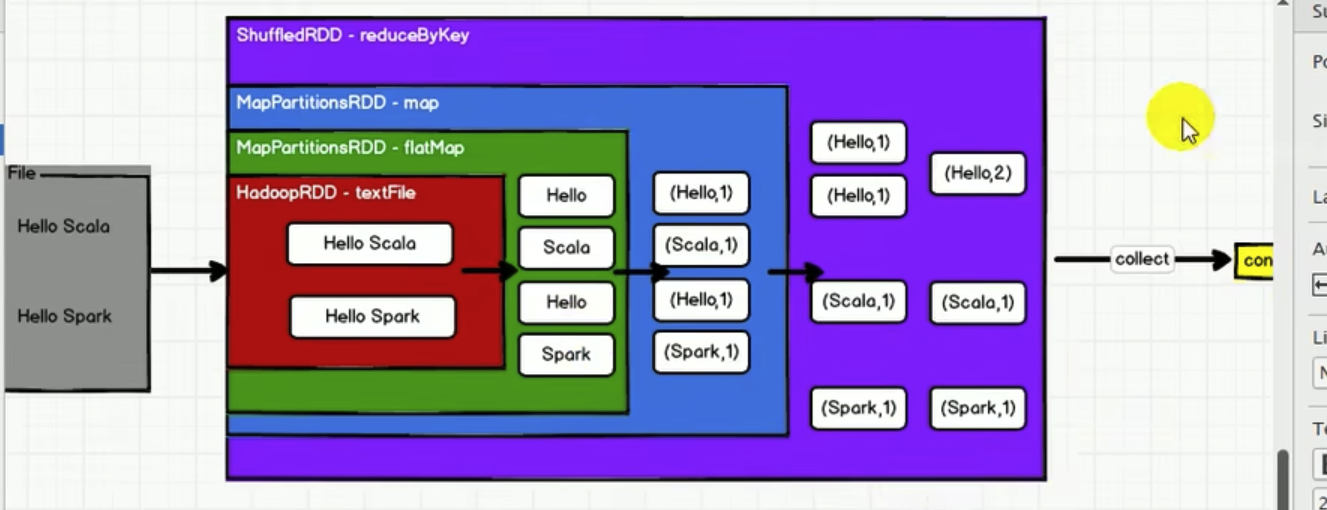
3. RDD的五大属性
Internally, each RDD is characterized by five main properties:
- A list of partitions
- A function for computing each split
- A list of dependencies on other RDDs
- Optionally, a Partitioner for key-value RDDs (e.g. to say that the RDD is hash-partitioned)
- Optionally, a list of preferred locations to compute each split on (e.g. block locations for an HDFS file)
3.1 分区列表
如上图,由于RDD内直接分区了,所以需要分区列表
3.2 计算逻辑 compute
针对该RDD下的所有分区,compute都是一样的
3.3 和其他RDD的依赖关系
3.4 (可选) 分区器
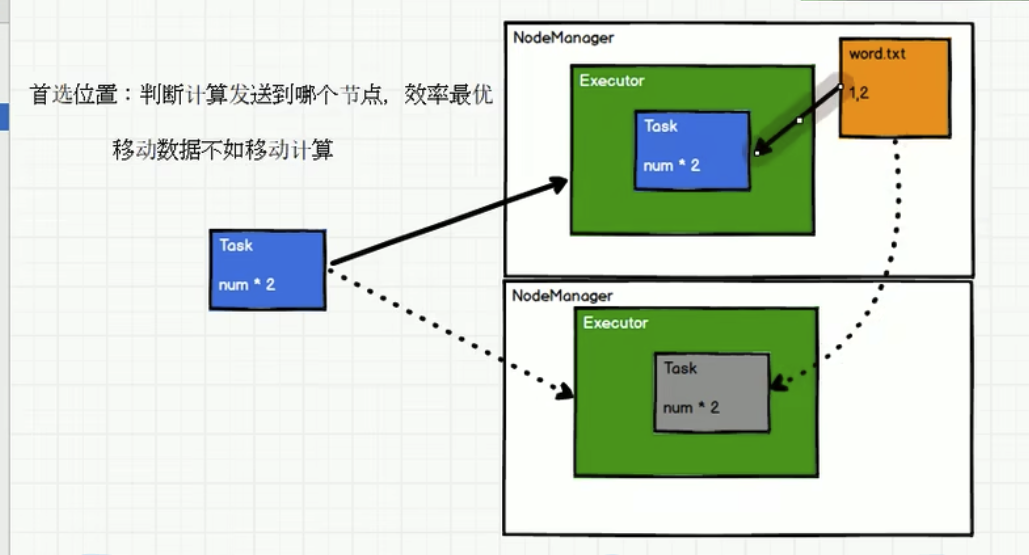
3.5 (可选) executor节点亲和
如下,其实任务发送给上面的
4. RDD执行原理(yarn环境)
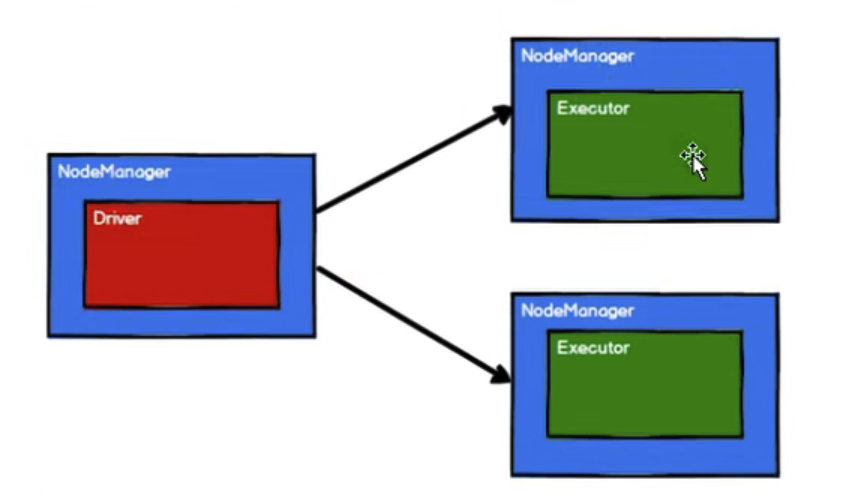
4.1 启动Yarn集群环境
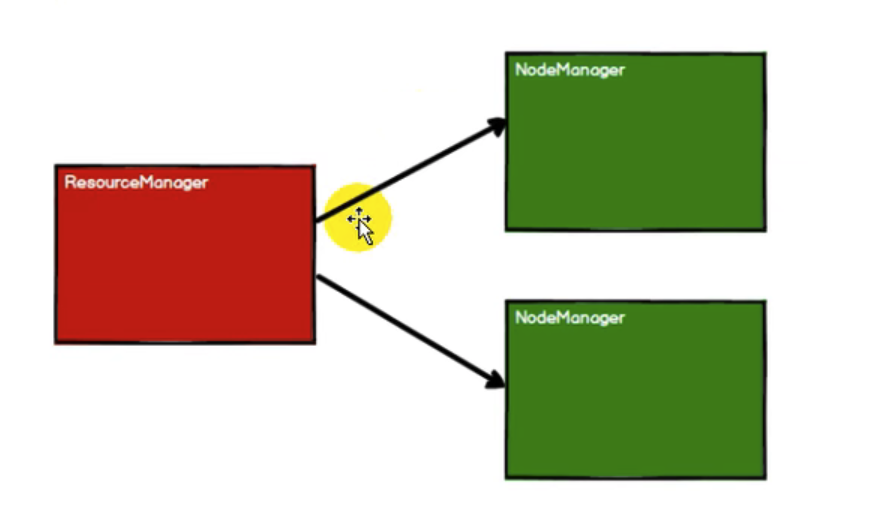
4.2 Spark通过申请资源创建调度节点和计算节点
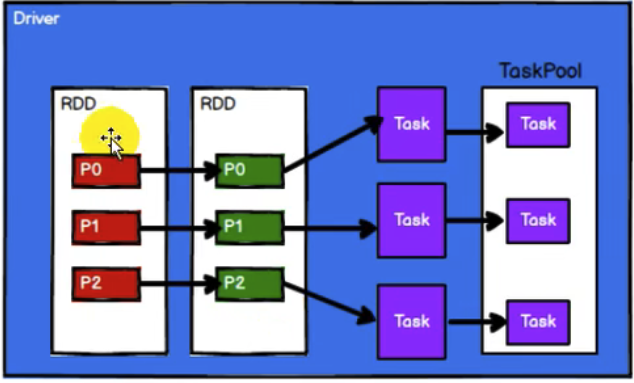
4.3 Spark框架根据需求将计算逻辑根据分区划分成不同的任务。此处会将task放置到 任务池中
4.4 调度节点将任务根据计算节点状态发送到对应的计算节点进行计算
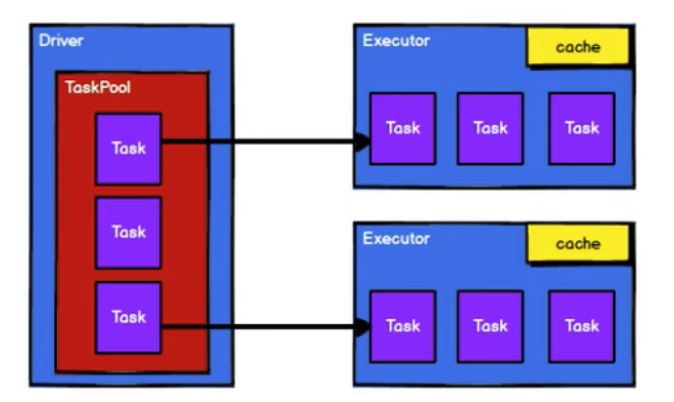
从以上流程可以看出RDD在整个流程中主要用于将逻辑进行封装,并生成Task发送给Executor节点执行计算。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号