spark (三) hadoop上传文件并运行spark
目录
1. 上传文件到hdfs
# 前提挂载了 -v ~/bilibili/input_files:/input_files
# hdfs创建input文件夹
docker exec namenode hdfs dfs -mkdir /input
# 将容器内input_files文件夹下的1.txt上传到 hdfs的 /input下
docker exec namenode hdfs dfs -put /input_files/1.txt /input
查看浏览器中是否有指定文件
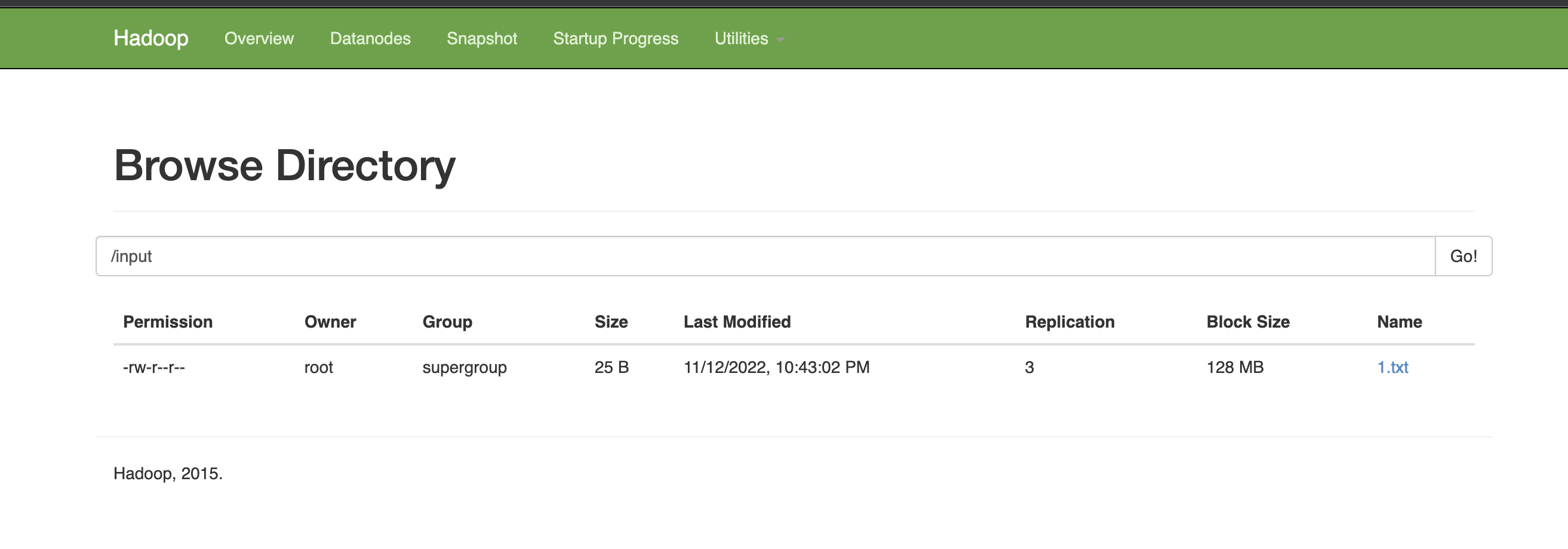
2. 运行wordCount
2.1 spark-shell运行
# 进入spark master容器内的spark-shell
docker exec -ti master spark-shell --executor-memory 1024M --total-executor-cores 2
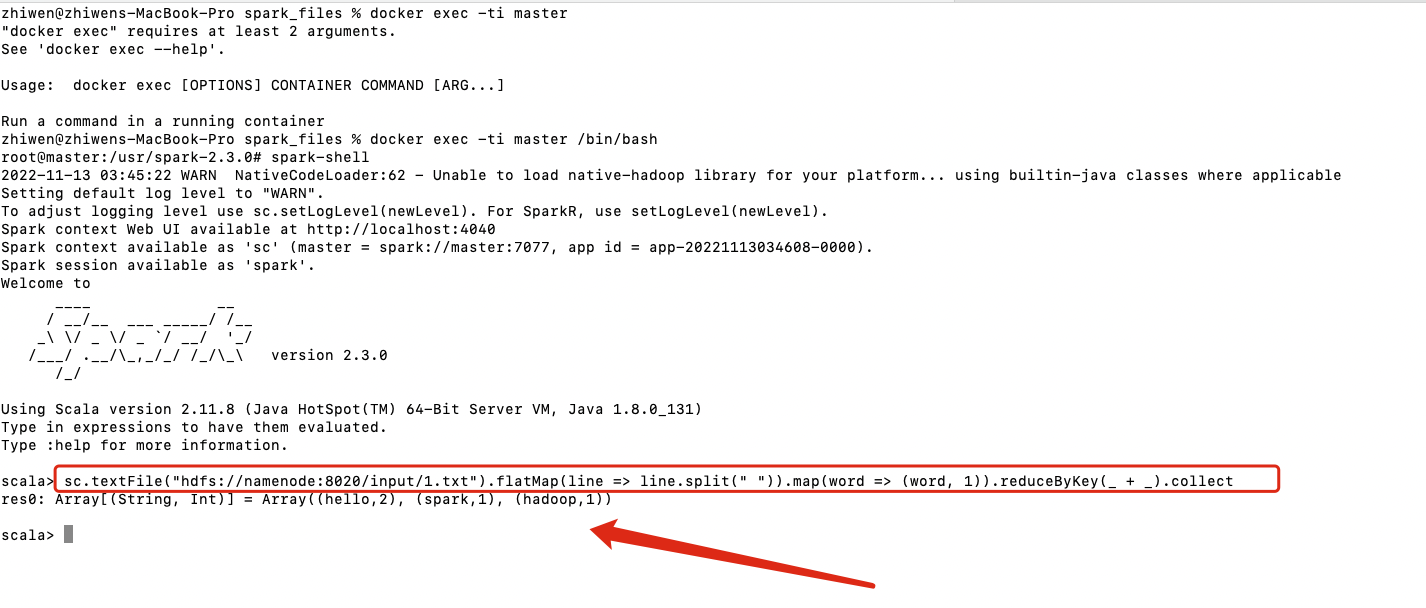
# 执行wordCount
sc.textFile("hdfs://namenode:8020/input/1.txt").flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey(_ + _).collect
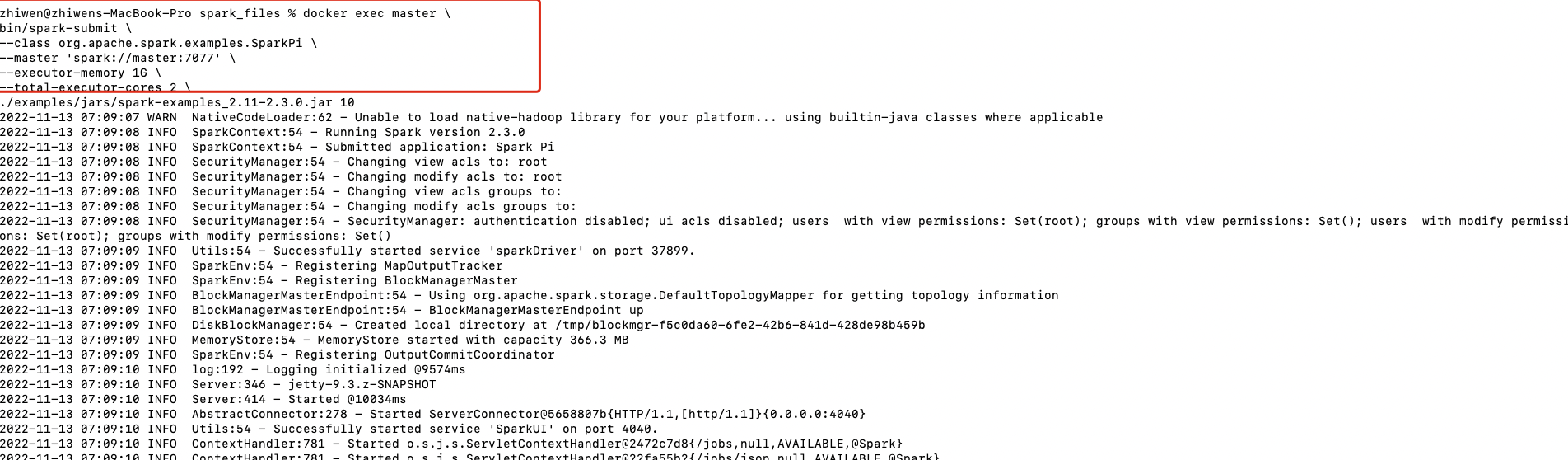
2.2 spark-submit运行example(stand-alone)
这里使用官方默认的example jar运行
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
| 参数 | 解释 | 可选值 |
|---|---|---|
| --class | Spark程序中包含主函数的类 | |
| --master | Spark程序运行的模式(环境) | local[*] spark://master:7077 yarn |
| --executor-memory | 每个executor可用内存为1G | |
| --total-executor-cores | 所有executor使用的cpu核数 | |
| application-jar | 打包好的应用jar, 包含依赖。这个URL在集群中全局可见 | 本地路径的jar包或者hdfs://路径 |
| application-arguements | 传给程序的参数 |
2.3 spark-submit运行example(yarn)
docker exec master \
bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--deploy-mode cluster \
./examples/jars/spark-examples_2.12-3.2.1.jar \
10
2.4 spark-submit运行自定义的jar包(stand-alone)
2.4.1 自定义spark任务
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
println("---------------start word_count----------------")
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
// .setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
println("----------------new SparkContext done---------------")
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val inputPath: String = args(0)
val lines: RDD[String] = ctx.textFile(inputPath)
// val lines: RDD[String] = ctx.textFile("hdfs://namenode:9000/input")
println("----------------ctx.textFile done---------------")
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// 相同的key会对value做reduce
val tuple: RDD[(String, Int)] = wordToOne.reduceByKey((t1, t2) => t1 + t2)
val coll: Array[(String, Int)] = tuple.collect()
coll.foreach(println)
println(s"""----------------tuple.foreach(println) done len ${coll.length}---------------""")
// 3. 关闭连接
ctx.stop()
println("----------------ctx.stop() done---------------")
}
}
2.4.2 生成jar包
2.4.3 复制到挂载的jars文件夹内
2.4.4 运行spark-submit
docker exec master \
bin/spark-submit \
--class com.lzw.bigdata.spark.core.wordcount.Spark03_WordCount \
--master 'spark://master:7077' \
--executor-memory 1G \
--total-executor-cores 2 \
/jars/spark_core.jar \
'hdfs://namenode:9000/input'

 浙公网安备 33010602011771号
浙公网安备 33010602011771号