spark (二) spark wordCount示例
实现思路
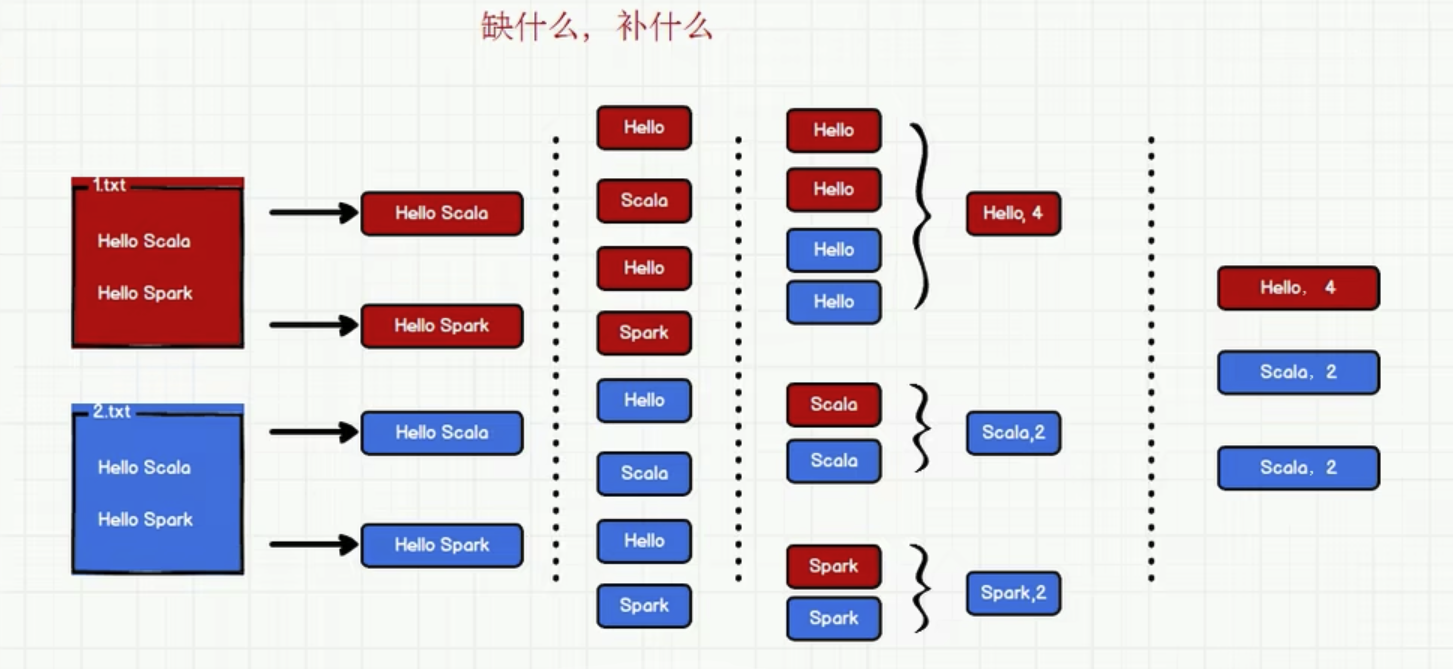
实现1: scala 基本集合操作方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
words.foreach(println)
val wordGroup: RDD[(String, Iterable[String])] = words.groupBy(word => word)
val x = 1
// 2.3 将数据根据单词进行分组,便于统计
val wordToCount: RDD[(String, Int)] = wordGroup.map({
case (word, list) => (word, list.size)
})
val tuples: Array[(String, Int)] = wordToCount.collect()
// 2.4 打印结果
tuples.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
实现2: scala map reduce方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
// lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// 分组
val wordGroup: RDD[(String, Iterable[(String, Int)])] = wordToOne.groupBy(t => t._1)
// 聚合
val tuple: RDD[(String, Int)] = wordGroup.map({
case (word, list) => list.reduce((t1, t2) => (t1._1, t1._2 + t2._2))
})
tuple.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
实现3: spark 提供的map reduce方式获取结果
package com.lzw.bigdata.spark.core.wordcount
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// Spark框架步骤
// 1. 建立和Spark框架的链接
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local")
.setAppName("WordCount")
val ctx = new SparkContext(sparkConfig)
// 2. 执行业务逻辑
// 2.1 读取文件,获取一行一行的数据
val lines: RDD[String] = ctx.textFile("data")
// lines.foreach(println)
// 2.2 分词,此处按照空格spilt
val words: RDD[String] = lines.flatMap(line => line.split(" "))
val wordToOne: RDD[(String, Int)] = words.map(word => (word, 1))
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// 相同的key会对value做reduce
val tuple: RDD[(String, Int)] = wordToOne.reduceByKey((t1, t2) => t1 + t2)
tuple.foreach(println)
// 3. 关闭连接
ctx.stop()
}
}
FAQ:
Q: 初步运行spark错误
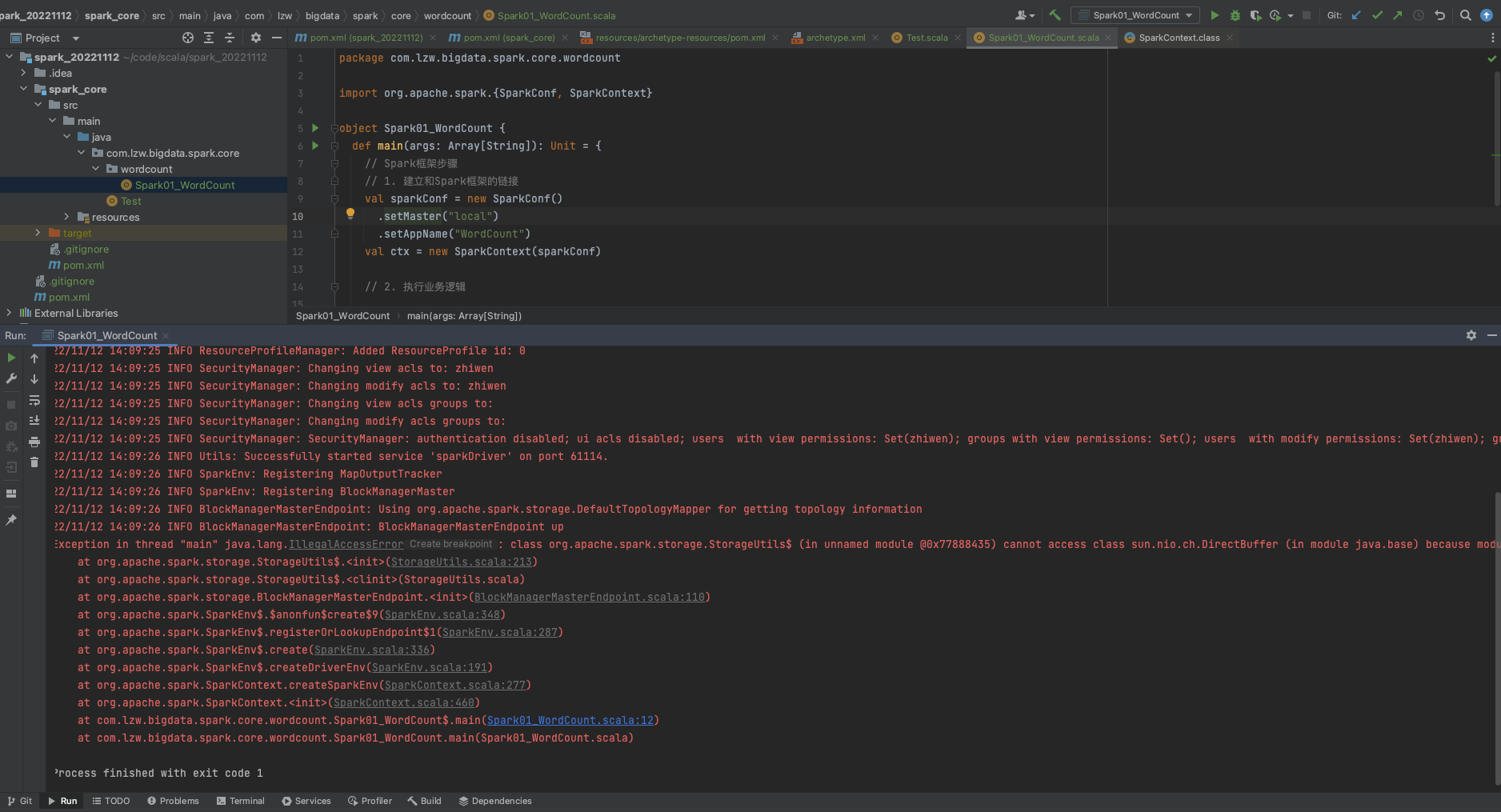
A: JDK版本问题, 切换jdk到1.8就可以了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号