spark (一) 入门 & 安装
目录
基本概念
spark主要是计算框架
spark 核心模块
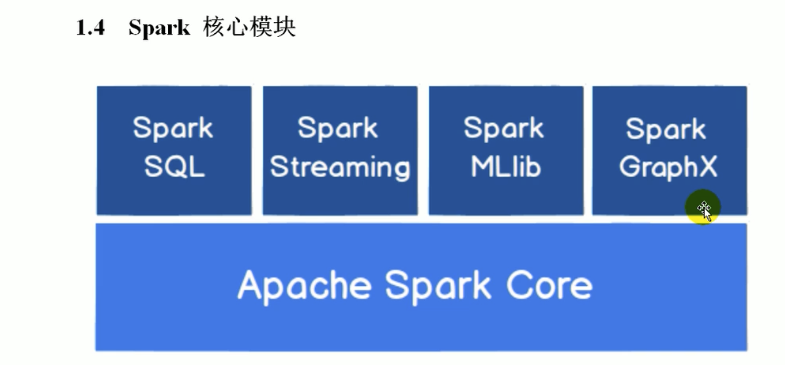
spark core (核心)
spark core 提供了最基础最核心的功能,其他的功能比如 spark sql, spark streaming, graphx, MLlib 都是在此基础上扩展的
spark sql (结构化数据操作)
spark sql是用来操作结构化数据的组件。通过spark sql可以使用 sql 或者hive版本的sql方言(hql) 来查询数据
spark streaming (流式数据操作)
spark streaming 是针对实时数据进行流式计算的组件,提供了丰富的处理数据流的API
部署模式
local(本地模式)
常用于本地开发测试,本地还分为local单线程和local-cluster多线程;
standalone(集群模式)
典型的Mater/slave模式,不过也能看出Master是有单点故障的;Spark支持ZooKeeper来实现 HA.
此处spark即负责计算也负责资源管理
on yarn(集群模式)
运行在 yarn 资源管理器框架之上,由 yarn 负责资源管理,Spark 负责任务调度和计算
on mesos(集群模式)
运行在 mesos 资源管理器框架之上,由 mesos 负责资源管理,Spark 负责任务调度和计算
on cloud(集群模式)
比如 AWS 的 EC2,使用这个模式能很方便的访问 Amazon的 S3;Spark 支持多种分布式存储系统:HDFS 和 S3
docker-compose安装spark集群
参考: https://blog.csdn.net/weixin_42688573/article/details/127130863
执行docker-compose安装
- docker-compose.yml
version: "3.3"
services:
namenode:
image: bde2020/hadoop-namenode:2.0.0-hadoop3.2.1-java8
container_name: namenode
ports:
- 9870:9870
- 9000:9000
volumes:
- ./hadoop_volumn/dfs/name:/hadoop/dfs/name
- ./input_files:/input_files
environment:
- CLUSTER_NAME=test
env_file:
- ./hadoop.env
datanode:
image: bde2020/hadoop-datanode:2.0.0-hadoop3.2.1-java8
container_name: datanode
ports:
- 9064:9064
depends_on:
- namenode
volumes:
- ./hadoop_volumn/dfs/data:/hadoop/dfs/data
environment:
SERVICE_PRECONDITION: "namenode:9870"
env_file:
- ./hadoop.env
resourcemanager:
image: bde2020/hadoop-resourcemanager:2.0.0-hadoop3.2.1-java8
container_name: resourcemanager
depends_on:
- namenode
- datanode
ports:
- 8088:8088
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864"
env_file:
- ./hadoop.env
nodemanager1:
image: bde2020/hadoop-nodemanager:2.0.0-hadoop3.2.1-java8
container_name: nodemanager
ports:
- 8042:8042
depends_on:
- namenode
- datanode
- resourcemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
env_file:
- ./hadoop.env
historyserver:
image: bde2020/hadoop-historyserver:2.0.0-hadoop3.2.1-java8
container_name: historyserver
ports:
- 8188:8188
depends_on:
- namenode
- datanode
- resourcemanager
environment:
SERVICE_PRECONDITION: "namenode:9000 namenode:9870 datanode:9864 resourcemanager:8088"
volumes:
- ./hadoop_volumn/yarn/timeline:/hadoop/yarn/timeline
env_file:
- ./hadoop.env
master:
image: bitnami/spark:3.2.1
container_name: master
hostname: master
user: root
environment:
- SPARK_MODE=master
- SPARK_MASTER_URL=spark://master:7077
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
ports:
- '8080:8080'
- '7077:7077'
- '4040:4040'
volumes:
- ./spark_volumn/python:/python
- ./spark_volumn/jars:/jars
worker1:
image: bitnami/spark:3.2.1
container_name: worker1
hostname: worker1
user: root
depends_on:
- master
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
worker2:
image: bitnami/spark:3.2.1
container_name: worker2
hostname: worker2
user: root
depends_on:
- master
environment:
- SPARK_MODE=worker
- SPARK_MASTER_URL=spark://master:7077
- SPARK_WORKER_MEMORY=1G
- SPARK_WORKER_CORES=1
- SPARK_RPC_AUTHENTICATION_ENABLED=no
- SPARK_RPC_ENCRYPTION_ENABLED=no
- SPARK_LOCAL_STORAGE_ENCRYPTION_ENABLED=no
- SPARK_SSL_ENABLED=no
- hadoop.env
CORE_CONF_fs_defaultFS=hdfs://namenode:9000
CORE_CONF_hadoop_http_staticuser_user=root
CORE_CONF_hadoop_proxyuser_hue_hosts=*
CORE_CONF_hadoop_proxyuser_hue_groups=*
CORE_CONF_io_compression_codecs=org.apache.hadoop.io.compress.SnappyCodec
HDFS_CONF_dfs_webhdfs_enabled=true
HDFS_CONF_dfs_permissions_enabled=false
HDFS_CONF_dfs_namenode_datanode_registration_ip___hostname___check=false
YARN_CONF_yarn_log___aggregation___enable=true
YARN_CONF_yarn_log_server_url=http://historyserver:8188/applicationhistory/logs/
YARN_CONF_yarn_resourcemanager_recovery_enabled=true
YARN_CONF_yarn_resourcemanager_store_class=org.apache.hadoop.yarn.server.resourcemanager.recovery.FileSystemRMStateStore
YARN_CONF_yarn_resourcemanager_scheduler_class=org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___mb=8192
YARN_CONF_yarn_scheduler_capacity_root_default_maximum___allocation___vcores=4
YARN_CONF_yarn_resourcemanager_fs_state___store_uri=/rmstate
YARN_CONF_yarn_resourcemanager_system___metrics___publisher_enabled=true
YARN_CONF_yarn_resourcemanager_hostname=resourcemanager
YARN_CONF_yarn_resourcemanager_address=resourcemanager:8032
YARN_CONF_yarn_resourcemanager_scheduler_address=resourcemanager:8030
YARN_CONF_yarn_resourcemanager_resource__tracker_address=resourcemanager:8031
YARN_CONF_yarn_timeline___service_enabled=true
YARN_CONF_yarn_timeline___service_generic___application___history_enabled=true
YARN_CONF_yarn_timeline___service_hostname=historyserver
YARN_CONF_mapreduce_map_output_compress=true
YARN_CONF_mapred_map_output_compress_codec=org.apache.hadoop.io.compress.SnappyCodec
YARN_CONF_yarn_nodemanager_resource_memory___mb=16384
YARN_CONF_yarn_nodemanager_resource_cpu___vcores=8
YARN_CONF_yarn_nodemanager_disk___health___checker_max___disk___utilization___per___disk___percentage=98.5
YARN_CONF_yarn_nodemanager_remote___app___log___dir=/app-logs
YARN_CONF_yarn_nodemanager_aux___services=mapreduce_shuffle
MAPRED_CONF_mapreduce_framework_name=yarn
MAPRED_CONF_mapred_child_java_opts=-Xmx4096m
MAPRED_CONF_mapreduce_map_memory_mb=4096
MAPRED_CONF_mapreduce_reduce_memory_mb=8192
MAPRED_CONF_mapreduce_map_java_opts=-Xmx3072m
MAPRED_CONF_mapreduce_reduce_java_opts=-Xmx6144m
MAPRED_CONF_yarn_app_mapreduce_am_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
MAPRED_CONF_mapreduce_map_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
MAPRED_CONF_mapreduce_reduce_env=HADOOP_MAPRED_HOME=/data/docker-compose/hadoop-3.2.1/
等待安装完成
检验安装完成
常见问题:ResourceManager启动错误,日志看namenode处于safemode
# 退出安全模式
docker exec namenode hadoop dfsadmin -safemode leave
# 重新启动resourcemanager
docker start resourcemanager
- docker ps

一共起了如下几个容器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号