互联网上各个网页之间的链接关系我们都可以看成是一个有向图,一个网页的重要性由链接到该网页的其他网页来投票,一个较多链入的页面会有比较高等级,反之如果一个页面没有链入或链入较少等级则低,网页的PR值越高,代表网页越重要
假设一个有A、B、C、D四个网页组成的集合,B、C、D三个页面都链入到A,则A的PR值将是B、C、D三个页面PR值的总和:
PR(A)=PR(B)+PR(C)+PR(D)
继续上面的假设,B除了链接到A,还链接到C和D,C除了链接到A,还链接到B,而D只链接到A,所以在计算A的PR值时,B的PR值只能投出1/3的票,C的PR值只能投出1/2的票,而D只链接到A,所以能投出全票,所以A的PR值总和应为:
PR(A)=PR(B)/3+PR(C)/2+PR(D)
所以可以得出一个网页的PR值计算公式应为:
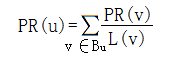
其中,Bu是所有链接到网页u的网页集合,网页v是属于集合Bu的一个网页,L(v)则是网页v的对外链接数(即出度)
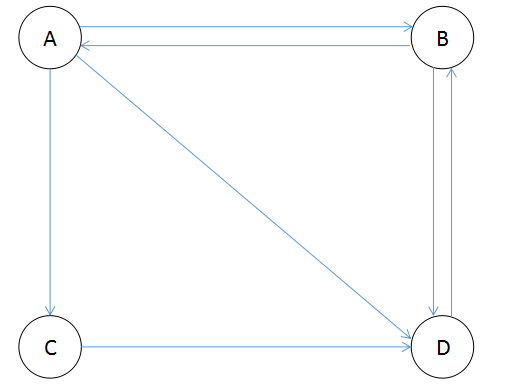
图1-1
表1-2 根据图1-1计算的PR值
|
PA(A) |
P(B) |
PR(C) | PR(D) | |
| 初始值 | 0.25 | 0.25 | 0.25 |
0.25 |
| 一次迭代 | 0.125 | 0.333 | 0.083 |
0.458 |
| 二次迭代 | 0.1665 | 0.4997 | 0.0417 |
0.2912 |
| …… | …… | …… | …… |
…… |
| n次迭代 | 0.1999 | 0.3999 | 0.0666 |
0.3333 |
表1-2,经过几次迭代后,PR值逐渐收敛稳定
然而在实际的网络环境中,超链接并没有那么理想化,比如PageRank模型会遇到如下两个问题:
1.排名泄露
如图1-3所示,如果存在网页没有出度链接,如A节点所示,则会产生排名泄露问题,经过多次迭代后,所有网页的PR只都趋向于0
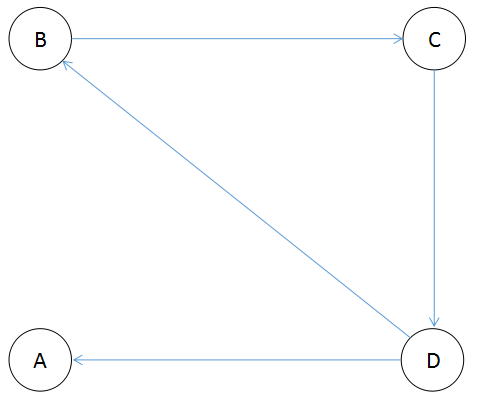
图1-3
|
PR(A) |
PR(B) | PR(C) | PR(D) | |
| 初始值 |
0.25 |
0.25 | 0.25 | 0.25 |
| 一次迭代 |
0.125 |
0.125 | 0.25 | 0.25 |
| 二次迭代 |
0.125 |
0.125 | 0.125 | 0.25 |
| 三次迭代 |
0.125 |
0.125 | 0.125 | 0.125 |
| …… |
…… |
…… | …… | …… |
| n次迭代 |
0 |
0 | 0 | 0 |
表1-4为图1-3多次迭代后结果
2.排名下沉
如图1-5所示,若网页没有入度链接,如节点A所示,经过多次迭代后,A的PR值会趋向于0

图1-5
|
PR(A) |
PR(B) | PR(C) | PR(D) | |
| 初始值 |
0.25 |
0.25 | 0.25 | 0.25 |
| 一次迭代 |
0 |
0.375 | 0.25 | 0.375 |
| 二次迭代 |
0 |
0.375 | 0.375 | 0.25 |
| 三次迭代 |
0 |
0.25 | 0.375 | 0.375 |
| …… |
…… |
…… | …… | …… |
| n次迭代 |
0 |
…… | …… | …… |
表1-5为图1-4多次迭代后结果
我们假定上王者随机从一个网页开始浏览,并不断点击当前页面的链接进行浏览,直到链接到一个没有任何出度链接的网页,或者上王者感到厌倦,随机转到另外的网页开始新一轮的浏览,这种模型显然更贴近用户的习惯。为了处理那些没有任何出度链接的页面,引入阻尼系数d来表示用户到达缪戈页面后继续向后浏览的概率,一般将其设为0.85,而1-d就是用户停止点击,随机转到另外的网页开始新一轮浏览的概率,所以引入随机浏览模型的PageRank公式如下:
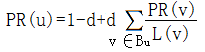
图1-6
代码1-7为根据图1-6建立数据集
root@lejian:/data# cat links A B,C,D B A,D C D D B
GraphBuilder步骤的主要目的是建立网页之间的链接关系图,以及为每一个网页分配初始的PR值,由于我们的数据集已经建立好网页之间的链接关系图,所以在代码1-8中只要为每个网页分配相等的PR值即可
代码1-8
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class GraphBuilder {
public static class GraphBuilderMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text url = new Text();
private Text linkUrl = new Text();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException {
String[] tuple = value.toString().split("\t");
url.set(tuple[0]);
if (tuple.length == 2) {
// 网页有出度
linkUrl.set(tuple[1] + "\t1.0");
} else {
// 网页无出度
linkUrl.set("\t1.0");
}
context.write(url, linkUrl);
};
}
protected static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("Graph Builder");
job.setJarByClass(GraphBuilder.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(GraphBuilderMapper.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
PageRankIter步骤的主要目的是迭代计算PageRank数值,直到满足运算结束条件,比如收敛或达到预定的迭代次数,这里采用预设迭代次数的方式,多次运行该步骤
代码1-9
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRankIter {
private static final double DAMPING = 0.85;
public static class PRIterMapper extends Mapper<LongWritable, Text, Text, Text> {
private Text prKey = new Text();
private Text prValue = new Text();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException {
String[] tuple = value.toString().split("\t");
if (tuple.length <= 2) {
return;
}
String[] linkPages = tuple[1].split(",");
double pr = Double.parseDouble(tuple[2]);
for (String page : linkPages) {
if (page.isEmpty()) {
continue;
}
prKey.set(page);
prValue.set(tuple[0] + "\t" + pr / linkPages.length);
context.write(prKey, prValue);
}
prKey.set(tuple[0]);
prValue.set("|" + tuple[1]);
context.write(prKey, prValue);
};
}
public static class PRIterReducer extends Reducer<Text, Text, Text, Text> {
private Text prValue = new Text();
protected void reduce(Text key, Iterable<Text> values, Context context) throws java.io.IOException, InterruptedException {
String links = "";
double pageRank = 0;
for (Text val : values) {
String tmp = val.toString();
if (tmp.startsWith("|")) {
links = tmp.substring(tmp.indexOf("|") + 1);
continue;
}
String[] tuple = tmp.split("\t");
if (tuple.length > 1) {
pageRank += Double.parseDouble(tuple[1]);
}
}
pageRank = (1 - DAMPING) + DAMPING * pageRank;
prValue.set(links + "\t" + pageRank);
context.write(key, prValue);
};
}
protected static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("PageRankIter");
job.setJarByClass(PageRankIter.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PRIterMapper.class);
job.setReducerClass(PRIterReducer.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
PageRankViewer步骤将迭代计算得到的最终排名结果按照PageRank值从大到小的顺序进行输出,并不需要reduce,输出的键值对为<PageRank,URL>
代码1-10
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.io.WritableComparable;
import org.apache.hadoop.io.WritableComparator;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRankViewer {
public static class PageRankViewerMapper extends Mapper<LongWritable, Text, FloatWritable, Text> {
private Text outPage = new Text();
private FloatWritable outPr = new FloatWritable();
protected void map(LongWritable key, Text value, Context context) throws java.io.IOException, InterruptedException {
String[] line = value.toString().split("\t");
outPage.set(line[0]);
outPr.set(Float.parseFloat(line[2]));
context.write(outPr, outPage);
};
}
public static class DescFloatComparator extends FloatWritable.Comparator {
public float compare(WritableComparator a, WritableComparable<FloatWritable> b) {
return -super.compare(a, b);
}
public int compare(byte[] b1, int s1, int l1, byte[] b2, int s2, int l2) {
return -super.compare(b1, s1, l1, b2, s2, l2);
}
}
protected static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
job.setJobName("PageRankViewer");
job.setJarByClass(PageRankViewer.class);
job.setOutputKeyClass(FloatWritable.class);
job.setSortComparatorClass(DescFloatComparator.class);
job.setOutputValueClass(Text.class);
job.setMapperClass(PageRankViewerMapper.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
job.waitForCompletion(true);
}
}
代码1-11
package com.hadoop.mapreduce;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
public class PageRankDriver {
public static void main(String[] args) throws Exception {
if (args == null || args.length != 3) {
throw new RuntimeException("请输入输入路径、输出路径和迭代次数");
}
int times = Integer.parseInt(args[2]);
if (times <= 0) {
throw new RuntimeException("迭代次数必须大于零");
}
String UUID = "/" + java.util.UUID.randomUUID().toString();
String[] forGB = { args[0], UUID + "/Data0" };
GraphBuilder.main(forGB);
String[] forItr = { "", "" };
for (int i = 0; i < times; i++) {
forItr[0] = UUID + "/Data" + i;
forItr[1] = UUID + "/Data" + (i + 1);
PageRankIter.main(forItr);
}
String[] forRV = { UUID + "/Data" + times, args[1] };
PageRankViewer.main(forRV);
Configuration conf = new Configuration();
FileSystem fs = FileSystem.get(conf);
Path path = new Path(UUID);
fs.deleteOnExit(path);
}
}
运行代码1-11,结果如代码1-12所示
代码1-12
root@lejian:/data# hadoop jar pageRank.jar com.hadoop.mapreduce.PageRankDriver /data /output 10
…… root@lejian:/data# hadoop fs -ls -R /output
-rw-r--r-- 1 root supergroup 0 2017-02-10 17:55 /output/_SUCCESS
-rw-r--r-- 1 root supergroup 50 2017-02-10 17:55 /output/part-r-00000
root@lejian:/data# hadoop fs -cat /output/part-r-00000
1.5149547 B
1.3249696 D
0.78404236 A
0.37603337 C

 浙公网安备 33010602011771号
浙公网安备 33010602011771号