mysql数据库基础操作
本篇文章记录学习mysql的操作过程,不会涉及过多的理论,更多的是直接操作。
环境:win10
工具:mysql命令行
0x01 连接与退出mysql
1.1 连接mysql数据库
连接mysql有很多的途径,可以通过客户端软件(又叫数据库管理系统)连接,比如:Navicat 、MySQL-Front等。web端的有phpMyAdmin。这些都是图像化界面的。也可以通过命令行来操作,接下来就用命令行进行操作。
进入mysql的bin目录,里面有一个mysql.exe,在这个目录下开启cmd。
--连接数据库,其中,-h == host 是mysql部署的ip地址,-P == Port:mysql服务端口,-u == username:登录用户名,-p == password:登录密码
mysql -hlocalhost -P3306 -uroot -proot
-- 如果连接本地数据库 -h可以省略 如果服务器端口是3306,-P端口号也可以省略
mysql -uroot -proot
--以安全的形式登录
mysql -uroot -p
Enter password: ****(这里输入密码)
1.2退出mysql命令行
mysql> exit -- 方法一
mysql> quit -- 方法二
mysql> \q -- 方法三
0x02 数据库操作
2.1 查看数据库
--查看有哪些数据库
show databases;
2.2 创建数据库
语法:
create database [if not exists] 数据名 [选项]
代码:
-- 创建数据库
create database student;
-- 创建数据库时,如果数据库已经存在就要报错
# ERROR 1007 (HY000): Can't create database 'stu'; database exists
-- 在创建数据库时候,判断数据库是否存在,不存在就创建
create database if not exists stu;
-- 特殊字符、关键字做数据库名,使用反引号将数据库名括起来
create database `create`; --create是关键字
create database `%$`;
-- 创建数据库时指定存储的字符编码,如果不指定编码,数据库默认使用安装数据库时指定的编码:latin
create database emp charset=gbk;
create database SC charset=utf8;
-- 查看所有字符集语句:
show character set;
2.3 数据库的目录
数据库文件的保存路径在安装mysql的时候就已经默认配置好了.我们也可以在my.ini配置文件中更改数据库文件的保存地址。(datadir = "xxx/MySQL/data/")

一个数据库就对应一个文件夹,在文件夹中有一个db.opt文件。再此文件中设置数据库的字符集和校对集。了解字符集和校对集请参考:mysql之字符集与校对集

2.4 删除数据库
语法:drop database [if exists] 数据库名
代码:
drop database `create`;
drop database stu;
-- 判断数据库是否存在,如果存在就删除
drop database if exists student;
2.5 显示创建数据库语句
语法:
show create database 数据库名
代码:
show create database test;

2.6 修改数据库
只能修改数据库的选项,数据库的选项只有字符集
语法:alter database 数据库名 charset=字符编码
代码:
alter database emp charset=utf8; -- 在mysql里utf编码是utf8而不是 utf-8
2.7 选择数据库
语法:use database_name
例如:
use test;
0x03 表操作
首先选中某一数据库,然后在这个数据库中执行表的相关操作。
显示数据库中的所有表:show tables;
3.1 创建表
语法:
create table [if not exists] `表名`(
`字段名` 数据类型 [null|not null] [default] [auto_increment] [primary key] [comment],
`字段名 数据类型 …
)[engine=存储引擎] [charset=字符编码]
-- 说明:
/*
null|not null 是否为空
default: 默认值
auto_increment 自动增长,默认从1开始,每次递增1
primary key 主键,主键的值不能重复,不能为空,每个表必须只能有一个主键
comment: 备注
engine 引擎决定了数据的存储和查找 myisam、innodb
注意:表名和字段名如果用了关键字,要用反引号引起来。
*/
例如:创建一个学生表:
create table student(
sno int auto_increment primary key comment '主键',
name varchar(10) not null comment '姓名',
age int comment'年龄',
sex varchar(2) comment '性别',
grade int comment '学生成绩'
)engine=innodb;
/*
说明:
1.如果不指定引擎,默认是innodb
2.如果不指定字符编码,默认和数据库编码一致
*/
3.2 数据表文件相关说明
一个数据库对应一个文件夹
一个表对应一个或多个文件
mysql里面引擎有两个:myisam和innodb
如果引擎是myisam,一个表对应三个文件
.frm:存储的是表结构
.myd:存储的是表数据
.myi:存储的表数据的索引
引擎是innodb,一个表对应一个表结构文件,innodb的都有表的数据都保存在ibdata1文件中.
如果数据量很大,会自动的创建ibdata2,ibdata3...
innodb和myisam的区别(推荐使用innodb)
| 引擎 | 特点 |
|---|---|
| myisam | 1、查询速度快 2、容易产生碎片 3、不能约束数据 |
| innodb | 1、以前没有myisam查询速度快,现在已经提速了 2、不产生碎片 3、可以约束数据 |
3.3 显示创建表的语句
语法:
show create table 表名; -- 结果横着排列
show create table 表名 \G --结果竖着排列(便于查看)注意没有分号
3.4 查看表结构
语法:desc[ribe] 表名
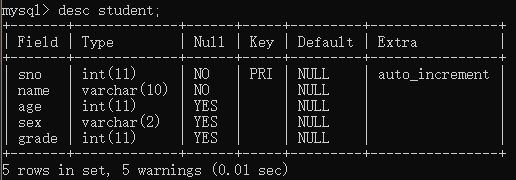
3.5 删除表
语法:drop table [if exists] table1,table2,...
eg.
-- 删除表
drop table t1;
-- 如果表存在就删除
drop table if exists t2;
-- 一次删除多个表
drop table t3,t4;
3.6 复制表
语法1:create table 新表 select 字段 from 旧表
特点:不能复制旧表的键,能够复制旧表的数据。
语法2:create table 新表 like 旧表
特点:只能复制表结构,不能复制表数据.
3.7 修改表
语法:alter table 表名
1.添加字段:alter table 表名 add [column] 字段名 数据类型 [位置]
eg.
--默认添加字段放在最后
alter table course add cno varchar(20);
-- 在cno之后添加cpo字段
alter table course add cpo varchar(20) after cno;
-- 添加Ccredit并将Ccredit放到表的最前面
alter table course add Ccredit int first;
2.删除字段:alter table 表名 drop [column] 字段名
eg.
alter table student drop age; -- 删除age字段
3.修改字段(改名):alter table 表名 change [column] 原字段名 新字段名 数据类型 …
-- 将name字段改为cname varchar(20)
alter table course change name cname varchar(20);
4.修改字段(不改名):alter table 表名 modify 字段名 字段属性…
--将sex字段的数据类型修改为varchar(1)
alter table student modify sex varchar(1);
5.修改引擎:alter table 表名 engine=引擎名
--将student表的引擎改为myisam
alter table student engine=myisam;
6.修改表名:alter table 表名 rename to 新表名
-- 将表名student改为stu
alter table student rename to stu;
7.将表移动到其他数据库
-- 将当前数据库中的stu表移到test数据库中,并且改名为student
alter table stu rename to test.student;
0x04 数据操作
4.1 插入数据
语法:insert into 表名 (字段名, 字段名,…) values (值1, 值1,…)
eg.
/*
说明:
1.插入数据的字段和表的字段可以顺序不一致。但是插入字段名和插入的值一定要一一对应
2.当省略字段列表时,等同于插入数据的顺序和个数与原表相同
3.可以插入指定的字段,其他的字段默认为null(或者设定default)
4.可以插入默认值和空值;
5.可以一次插入多条数据,数据之间用逗号隔开,最后一条数据用分号结尾;
*/
-- 在student表中插入数据,(插入所有字段)
insert into student (sno,name,age,sex,grade)
values
(1,'张三',18,'男',99);
-- 在student表中插入数据,(插入部分指定字段)
insert into student (sno,name)
values
(2,'李四');
-- 插入数据的字段和表的字段可以顺序不一致。但是插入字段名和插入的值一定要一一对应
insert into student (name,sno)
values
('王五',3);
--如果插入的值的顺序和个数与表字段的顺序和个数一致,插入字段可以省略。
insert into student
values
(4,'张伟',19,'男',98);
--可以插入默认值和空值,default用来指定默认值,null用来指定空值(空值就是不知道,不存在的值)
insert into student (sno,name,age,sex)
values
(5,'doby',default,null);
-- 一次插入多条数据,数据之间用逗号隔开,最后一条数据用分号结尾
insert into student (sno,sname,age)
values
(6,'李刚',19),
(7,'李伟',20),
(8,'张丽丽',18);
4.2 更新数据
语法:update 表名 set 字段=值 [where 条件]
eg.
--将1号学生的年龄改为20岁
update student
set age=20
where sno=1;
-- 将1号学生的姓名改为王丽丽,性别改为女 (中间用逗号隔开)
update student
set name='王丽丽',sex='女'
where sno = 1;
4.3 删除数据
语法:delete from 表名[where 条件]
eg.
-- 删除6号学生
delete from student
where sno = 6;
-- 删除名字是李四的学生
delete from student
where name='李四';
--删除所有数据
delete from student;
delete from 和truncate table 的区别?
1.delete from 表名:遍历表记录,一条一条的删除
2.truncate table 表名:将原表销毁,再创建一个同结构的新表。就清空表而言,这种方法效率高。
4.4 查询语句
语法:select 列明 [from 表名] [where条件]
eg.
-- 查询sno为1的学生的信息
select * from student where sno=1;
-- 查询所有学生的学号和姓名
select sno,name from student ;
-- 查询所有字段的值
select * from sutdent;
0x05 mysql字符集与校对集
5.1 mysql字符集
概念与操作:
1.character_set_client:服务器认为的客户端编码
2.character_set_connection:连接层用什么编码
3.character_set_results:查询的结果用什么编码显示
4.编码范围:ladin1<gb2312<gbk<utf8
查看所有字符集语句:show character set;
查看数据库编码情况:
更改编码:
set character_set_client=xxx;
set character_set_connection=xxx;
set character_set_results=xxx;
执行SQL语句时信息的路径是这样的一个
信息输入路径:client→connection→server;
信息输出路径:server→connection→results;
如图所示:

乱码解决方案与总结:
1.编码集的大小要遵循:client<connection<server,否则会出现编码部分丢失的情况。
e.g.
client:utf-8,connection:ladin1
在utf-8 => ladin1 转换过程中,中文会因为无法在latin1字符集中表示而被转换为“?”(0×3F)符号,以后查询时不管连接字符集设置如何都无法恢复其内容了。
2.明确客户端的编码,客户端编码最好和character_set_client一致。
3.数据库使用utf-8,范围很大,其他编码转为utf-8时,不会出现编码部分丢失的情况。
4.实际的客户端编码、character_set_result、character_set_client三者一致。
e.g
命令行的编码是gbk(客户端实际编码)。

数据库编码情况

问题:
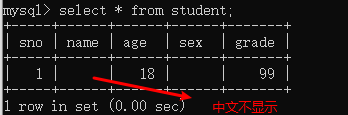
分析:
编码情况
客户端输入的数据:张三(gbk编码)
实际客户端:gbk
client:utf8
connection:utf8
database:utf8
result:utf8
处理过程如下:

那么如何解决呢?很简单,只需要将results的编码设置为gbk即可,如图:

5.1 mysql校对集(开发很少用,了解即可)
1、概念:在某种字符集下,字符之间的比较关系,比如a和B的大小关系,如果区分大小写a>B,如果不区分大小写则a<B。
2、校对集依赖与字符集,不同的字符集的的比较规则不一样,如果字符集更改,校对集也重新定义。
3、不同的校对集对同一字符序列比较的结果是不一致的。
4、 可以在定义字符集的同时定义校对集、 语法:collate=xxx
e.g.
--创建表stu1,并设置字符集为utf8、校对集为utf8_general_ci
create table stu1
(
name char(1)
)charset=utf8 collate=utf8_general_ci;
--创建表stu2,并设置字符集为utf8、校对集为utf8_bin
create table stu2
(
name char(1)
)charset=utf8 collate=utf8_bin;
-- 查询测试,不区分大小写
select * from stu1 order by name;
/*
+------+
| name |
+------+
| a |
| B |
+------+
*/
-- 查询测试,区分大小写
select * from stu2 order by name;
/*
+------+
| name |
+------+
| B |
| a |
+------+
*/
校对集规则:
_bin:按二进制编码比较,区别大小写
_ci:不区分大小写
本文到此结束!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号