Elasticsearch之-映射管理,ik分词器
在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个映射类型(只能有一个表)。
一 映射介绍
在创建索引的时候,可以预先定义字段的类型及相关属性(表类型,表结构)
Es会根据Json数据源的基础类型,猜测你想要映射的字段,将输入的数据转变成可以搜索的索引项。
Mapping是我们自己定义的字段数据类型,同时告诉es如何索引数据及是否可以被搜索
作用:会让索引建立的更加细致和完善
1.1 字段数据类型
string类型:text,keyword
数字类型:long,integer,short,byte,double,float
日期类型:data
布尔类型:boolean
binary类型:binary
复杂类型:object(实体,对象),nested(列表)
geo类型:geo-point,geo-shape(地理位置)
专业类型:ip,competion(搜索建议)
1.2 映射参数
| 属性 | 描述 | 适合类型 |
|---|---|---|
| store | 值为yes表示存储,no表示不存储,默认为no | all |
| index | yes表示分析,no表示不分析,默认为true | text |
| null_value | 如果字段为空,可以设置一个默认值,比如"NA"(传过来为空,不能搜索,na可以搜索) | all |
| analyzer | 可以设置索引和搜索时用的分析器,默认使用的是standard分析器,还可以使用whitespace,simple。都是英文分析器 | all |
| include_in_all | 默认es为每个文档定义一个特殊域_all,它的作用是让每个字段都被搜索到,如果想让某个字段不被搜索到,可以设置为false | all |
| format | 时间格式字符串模式 | date |
二 创建索引
text类型会取出词做倒排索引,keyword不会被分词,原样存储,原样匹配
mapping类型一旦确定,以后就不能修改了
#6.x的版本没问题 PUT books { "mappings": { "book":{ "properties":{ "title":{ "type":"text", "analyzer": "ik_max_word" }, "price":{ "type":"integer" }, "addr":{ "type":"keyword" }, "company":{ "properties":{ "name":{"type":"text"}, "company_addr":{"type":"text"}, "employee_count":{"type":"integer"} } }, "publish_date":{"type":"date","format":"yyy-MM-dd"} } } } }
7.x版本以后
PUT books { "mappings": { "properties":{ "title":{ "type":"text", "analyzer": "ik_max_word" }, "price":{ "type":"integer" }, "addr":{ "type":"keyword" }, "company":{ "properties":{ "name":{"type":"text"}, "company_addr":{"type":"text"}, "employee_count":{"type":"integer"} } }, "publish_date":{"type":"date","format":"yyy-MM-dd"} } } }
插入数据测试:
PUT books/_doc/1 { "title":"大头儿子小偷爸爸", "price":100, "addr":"北京天安门", "company":{ "name":"我爱北京天安门", "company_addr":"我的家在东北松花江傻姑娘", "employee_count":10 }, "publish_date":"2019-08-19" } #测试数据2 PUT books/_doc/2 { "title":"白雪公主和十个小矮人", "price":"99", #写字符串会自动转换 "addr":"黑暗森里", "company":{ "name":"我的家乡在上海", "company_addr":"朋友一生一起走", "employee_count":10 }, "publish_date":"2018-05-19" }
三 查看索引
#查看books索引的mapping GET books/_mapping #获取所有的mapping GET _all/_mapping # 映射是什么?映射有什么用? 规定了表结构(不是强制的),规定了哪个字段是可以用来全文检索,是否是数字类型,布尔类型 # mapping类型一旦确定,以后就不能修改了,但是可以插入字段
# 全文检索,有了映射,就可以对某个字段做全文检索 # es默认分词对英文友好,使用中文分词器ik(es的插件), # ik是es的一个插件(es如何安装插件) -第一种:命令行(内置插件) bin/elasticsearch-plugin install analysis-smartcn 安装中文分词器 -第二种:url安装(第三方插件) bin/elasticsearch-plugin install https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.5.0/elasticsearch-analysis-ik-7.5.0.zip -第三种:手动安装(推荐用) -下载,解压到ElasticSearch 安装目录下的plugins路径下,重启es即可 -注意:ik分词器跟es版本一定要对应
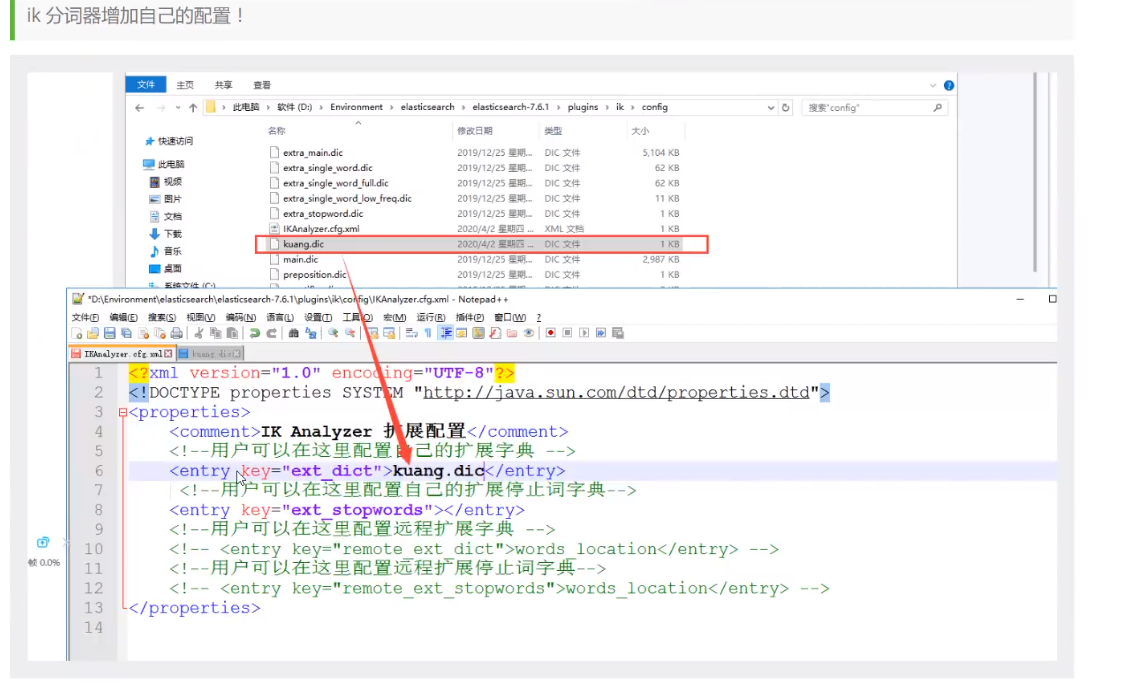
一些自己需要的词,需要我们自己加到分词器的字典中
ik目录简介
我们简要的介绍一下ik分词配置文件:
-
IKAnalyzer.cfg.xml,用来配置自定义的词库
-
main.dic,ik原生内置的中文词库,大约有27万多条,只要是这些单词,都会被分在一起。
-
surname.dic,中国的姓氏。
-
suffix.dic,特殊(后缀)名词,例如
乡、江、所、省等等。 -
preposition.dic,中文介词,例如
不、也、了、仍等等。 -
stopword.dic,英文停用词库,例如
a、an、and、the等。 -
quantifier.dic,单位名词,如
厘米、件、倍、像素等。
两种分词方式
# 两种分词方式 # ik_smart:分词分的少 # ik_max_word :分词分的多 GET _analyze { "analyzer": "ik_smart", "text": "上海自来水来自海上" } GET _analyze { "analyzer": "ik_max_word", "text": "上海自来水来自海上" } # 在创建映射的时候配置 -文章标题:ik_max_word -文章内容:ik_smart -摘要 -作者 -创建时间
term和match查询的区别
# match:我们今天出去玩 ----》分词---》按分词去搜 # term:我们今天出去玩---》直接拿着[我们今天出去玩]--->去索引中查询 # 查不到内容,它会直接拿着 Python爬虫 去查,因为没有索引,所以查不到 GET books/_search { "query":{ "term":{ "title":"Python爬虫" } } } # 能查到,而且带python的都查出来了 # 把Python、爬虫分了词,分别拿着这两个词去查,带python关键字,带爬虫关键字都能查到 GET books/_search { "query":{ "match":{ "title":"Python爬虫" } } }

 浙公网安备 33010602011771号
浙公网安备 33010602011771号