Python 常用模块
一、time 时间模块
在python的三种时间表现形式:
1.时间戳: 给电脑看的。
- 自格林威治时间 1970-01-01 00:00:00 到当前时间,按秒计算,计算到当前时间总共用了多少秒。
2.格式化时间(Format String): 给人看的
- 返回的是时间的字符串 2015-12-12
3.格式化时间对象(struct_time):
- 返回的是一个元组, 元组中有9个值:
9个值分别代表: 年、月、日、时、分、秒、一周中第几天,一年中的第几天,夏令时(了解)
import time
1、获取时间戳 (计算时间时使用)
print(time.time())
2、获取格式化时间(拼接用户时间格式并保存时使用)
print(time.strftime('%Y-%m-%d')) #获取年月日
print(time.strftime('%Y-%m-%d %H:%M:%S')) #获取年月日时分秒
3、获取时间对象
print(time.localtime()) #返回的时一个元组
print(type(time.localtime())) #<class 'time.struct_time'>
time_obj = time.localtime()
print(time_obj.tm_year) #2019
print(time_obj.tm_mon)
3.1、获取当前时间的格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
# res = time.localtime()
# time.sleep(5)
3.2、获取当前时间的格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S', time.localtime()))
3.3、将时间对象转为格式化时间
print(time.strftime('%Y-%m-%d %H:%M:%S', res))
3.4、将字符串格式的时间转为时间对象
res = time.strptime('2019-01-01', '%Y-%m-%d')
print(res)
二、datetime 时间模块
import datetime
获取当前年月日
print(datetime.date.today()) #2019-11-16
获取当前年月日时分秒
print(datetime.datetime.today()) #2019-11-16 14:48:18.744359
#time_obj = datetime.datetime.today()
#print(type(time_obj)) #<class 'datetime.datetime'>
#print(time_obj.year)
#print(time_obj.month)
#print(time_obj.day)
'''
日期/时间的计算
新日期时间 = 旧日期时间 “+” or “-” 时间对象
时间对象 = 新日期时间 “+” or “-” 旧日期时间
'''
旧日期时间:
current_time = datetime.datetime.now()
print(current_time)
时间对象
time_obj = datetime.timedelta(days=7) #获取7天时间
print(time_obj)
新日期时间 = 旧日期时间 “+” or “-” 时间对象
later_time = current_time + time_obj
print(later_time)
时间对象 = 新日期时间 “+” or “-” 旧日期时间
time_new_obj = later_time - current_time
print(time_new_obj)
三、random模块
import random
1.随机获取x—n中任意的整数
res = random.randint(x, n)
print(res)
2.默认获取0——1之间任意小数
res2 = random.random()
print(res2)
# 洗牌
3.将可迭代中的值乱序排列
-list
list1 = ['红桃A', '梅花A', '红桃Q', '方块K']
random.shuffle(list1)
print(list1)
4.随机获取可迭代对象中的某一个值 注意:有索引的可迭代对象
list1 = ['红桃A', '梅花A', '红桃Q', '方块K']
res3 = random.choice(list1)
print(res3)
5.从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。
list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
slice = random.sample(list1, 5) #从list中随机获取5个元素,作为一个片断返回
print(slice)
>>>[3, 8, 5, 10, 4]
6、随机获取1-9的浮点数
random.uniform(1,9)
案例:随机验证码的生成
'''
需求:
大小写字母、数字组合而成
组合5位数的随机验证码
前置技术:
- chr(97) # 可以将ASCII表中值转换成对应的字符
# print(chr(101))
- random.choice
'''
#获取任意长度的随机验证码
def get_code(n):
code = ''
#每次循环只从大小写字母,数字中取出一个字符
#for line in range(5):
for line in range(n):
#随机获取一个小写字母
res1 = random.randint(97,122)
lower_str = chr(res1)
#随机获取一个大写字母
res2 = random.randint(65,90)
upper_str = chr(res2)
#随机获取一个数字
number = str(random.randint(0,9))
#获取每一个字符的三种形式放入一个列表
code_list = [lower_str,upper_str,number] #['g', 'S', '4']
#随机取出每一个字符
random_code = random.choice(code_list)
#字符串拼接
code = code + random_code
return code
code = get_code(n)
print(code)
四、os模块
os模块是与操作系统交互的模块
import os
需求:
1.获取当前文件中的上一级目录
DAY15_PATH = os.path.dirname(__file__)
print(DAY15_PATH)
2.项目的根目录,路径相关的值都用 “常量”
BASE_PATH = os.path.dirname(DAY15_PATH)
print(BASE_PATH)
3.路径的拼接: 拼接文件 “绝对路径”
TEST_PATH = os.path.join(DAY15_PATH,'模拟1.txt')
print(TEST_PATH)
4.判断文件/文件夹”是否存在:若文件存在返回True,若不存在返回False
print(os.path.exists(TEST_PATH))
print(os.path.exists(DAY15_PATH))
5.判断文件是否存在
os.path.isfile()
6.判断“文件夹”是否存在
print(os.path.isdir(TEST_PATH))
print(os.path.isdir(DAY15_PATH))
7.创建文件夹
os.mkdir(DIR_PATH) #只传文件夹名字,会保存在当前执行文件的目录内
8.删除文件夹: 只能删除 “空的文件夹”
os.rmdir(DIR_PATH)
9.获取某个文件夹中所有文件的名字
list1 =os.listdir(r'F:\python正式课\day15')
print(list1)
需求:打印用户选择的文件内容
list1 =os.listdir(r'F:\python正式课\day15\模拟文件夹')
print(list1)
# enumerate(可迭代对象) #返回一个enumerate对象,对象里是一个个的元组(索引, 元素) #注意:可迭代对象中若是字典,则取字典中所有的key
res = enumerate(list1)
print(list(res))
#让用户选择文件
while True:
#打印所有文件的名字
for index,name in enumerate(list1):
print(f'编号:{index} 文件名:{name}')
choice = input('请选择想看的老师作品 编号:').strip()
#限制用户必须输入数字,数字的范围必须在编号内
#若不是数字,则重新选择
if not choice.isdigit():
print('必须输入数字')
continue
#若是数字,往下走判断是否在编号范围内
#若不在列表范围内,则重新选择
choice = int(choice)
if choice not in range(len(list1)):
print('编号范围错误')
continue
file_name = list1[choice]
list1_path = os.path.join(r'F:\python正式课\day15\模拟文件夹',file_name)
print(list1_path)
with open(list1_path, 'r', encoding='utf-8') as f:
print(f.read())
五、sys模块
1、sys.argv:获取操作系统中cmd(终端)的命令行 python3 py文件 用户名 密码
import sys
print(sys.argv) 返回的是列表['py文件', '用户名', '密码']
cmd_list = sys.argv
#执行文件权限认证
if cmd_list[1] == 'bob' and cmd_list[2] == '123':
print('通过验证')
print('开始执行逻辑代码')
else:
print('用户名或密码错误,权限不足!')
2、sys.path:获取当前的Python解释器的环境变量路径
print(sys.path)
将当前项目添加到环境变量中
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
#print(BASE_PATH)
sys.path.append(BASE_PATH)
print(sys.path)
六、hasblib:加密模块
hashlib是一个加密模块:内置了很多算法
- MD5: 不可解密的算法(2018年以前)
摘要算法:
- 摘要是从某个内容中获取的加密字符串
- 摘要一样,内容就一定一样: 保证唯一性
- 密文密码就是一个摘要
import hashlib
md5_obj = hashlib.md5()
# print(type(md5_obj)) #<class '_hashlib.HASH'>
str1 = '1234'
bytes1 = str1.encode('utf-8') #把字符串转成bytes类型
# print(bytes1) # b'1234'
md5_obj.update(bytes1) # update中一定要传入bytes类型数据
res = md5_obj.hexdigest() #得到一个加密后的字符串
print(res) # 81dc9bdb52d04dc20036dbd8313ed055
以上操作有一个问题,就是撞库。撞库有可能会破解真实密码
防止撞库问题:加盐:
import hashlib
def pwd_md5(pwd):
md5_obj = hashlib.md5()
str1 = pwd #pwd ='1234'
md5_obj.update(str1.encode('utf-8'))
#创造盐
sal ='我好帅'
#加盐
md5_obj.update(sal.encode('utf-8'))
res = md5_obj.hexdigest() #得到一个加密后的字符串 4ccef78b05804b0890e47bc0d045c236
return res
#模拟用户登录操作
#获取文件中的用户名与密码
with open('user.txt', 'r', encoding='utf-8') as f:
user_str = f.read()
file_user, file_pwd = user_str.split(':')
# 用户输入用户名与密码
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
# 校验用户名与密码是否一致
if username == file_user and file_pwd == pwd_md5(password): # pwd_md5('1234')
print('登陆成功')
else:
print('登陆失败')
七、序列化模块
序列化: 将Python或其他语言的数据类型转换成字符串类型。
- int, float, str, list, tuple, dict, bool, set
list1 = [1, 2, 3] -----> "[1, 2, 3]"
序列: 指的是字符串。
序列化: serializable
其他数据类型 ----> 字符串 ----> 文件中
反序列化:
文件中 ---> 字符串 ---> 其他数据类型
- json
第三方的
- pickle
属于python的
json模块:
1、什么是json模块
json模块:是一个序列化模块
json:
是一个“第三方"的特殊数据格式。
可以将python数据类型 ----》 json数据格式 ----》 字符串 ----》 文件中
其他语言要想使用python的数据:
文件中的 ----》 字符串 ----》 json数据格式 ----》 其他语言的数据类型。
注意:
-在json中,所有的字符串都是双引号
-元组比较特殊: python中的元组,若将其转换成json数据,内部会将元组转化成列表
-set不能转换成json数据
2、为什么要使用json:
-为了让不同的语言之间数据可以共享。
由于各种语言的数据类型不一,但长相可以一样,比如python不能直接使用其他语言的数据类型,
必须将其他语言的数据类型转换成json数据格式, python获取到json数据后可以将其转换成python的数据类型。
3、如何使用json
import json
json模块的内置方法:
- json.dumps:
f = open() --> f.write()
# 序列化: python数据类型 ---》 json ---》 字符串 ---》 json文件中
- json.loads:
f = open(), str = f.read(), json.loads(str)
# 反序列化: json文件中 --》 字符串 ---》 json ---》 python或其他语言数据类型
- json.dump(): # 序列化: python数据类型 ---》 json ---》 字符串 ---》 json文件中
- 内部实现 f.write()
- json.load(): # 反序列化: json文件中 --》 字符串 ---》 json ---》 python或其他语言数据类型
- 内部实现 f.read()
- dump, load: 使用更方便
注意: 保存json数据时,用.json作为文件的后缀名
import json
dumps,loads的用法:
#列表
list1 = ['张全蛋','李小花']
#ensure_ascii 将默认的ascii取消设置为False,可以在控制台看到中文,否则看到的是bytes类型数据
json_str = json.dumps(list1,ensure_ascii = False)
print(json_str)
print(type(json_str)) #<class 'str'>
python_date = json.loads(json_str)
print(python_date)
print(type(python_date)) #<class 'list'>
#元组
tuple1 =('张全蛋','李大花')
json_str = json.dumps(tuple1,ensure_ascii = False)
print(json_str)
print(type(json_str))
python_date = json.loads(json_str)
print(python_date)
print(type(python_date)) #<class 'list'>
#字典
dic = {
'name': 'tank',
'age': 17
}
json_str = json.dumps(dic,ensure_ascii = False)
print(json_str) #str
python_date = json.loads(json_str)
print(python_date)
print(type(python_date)) # dict
#注册功能
def register():
username = input('请输入用户名:').strip()
password = input('请输入密码:').strip()
re_password = input('请确认密码:').strip()
if password == re_password:
user_dic = {'name': username, 'pwd': password} # {'name': username, 'pwd': password}
json_str = json.dumps(user_dic, ensure_ascii=False)
#开始写入文件中
# 注意: 保存json数据时,用.json作为文件的后缀名
with open('user.json','w',encoding = 'utf-8') as f:
f.write(json_str)
register()
dump,load的用法:
user_dic = {'username': '张全蛋','password': 123}
with open('user3.json', 'w', encoding='utf-8') as f:
json.dump(user_dic, f)
with open('user3.json', 'r', encoding='utf-8') as f:
json.load(f)
pickle模块:
pickle是一个python自带的序列化模块
优点:
- 可以支持python中所有的数据类型
- 可以直接存 "bytes类型" 的数据,pickle存取速度更快
缺点: (致命的缺点)
- 只能支持python使用,不能跨平台
import pickle
set1 = {
'tank', 'sean', 'jason', '大脸'
}
# 存 dump
with open('teacher.pickle', 'wb') as f:
pickle.dump(set1, f)
# 取 load
with open('teacher.pickle', 'rb') as f:
#python_set = pickle.load(f)
#print(python_set)
#print(type(python_set))
八、collections模块:
提供一些python八大数据类型 “以外的数据类型” 。
python默认八大数据:
- 整型
- 浮点型
- 字符串
- 字典
- 元组
- 列表
- 集合
- 布尔
1、具名元组:
具名元组 只是一个名字。
应用场景:
- 坐标
from collections import namedtuple
2、 有序字典:
- python中字典默认是无序
- collections中提供了有序的字典
from collections import OrderedDict
1、具名元组
from collections import namedtuple
from collections import namedtuple
'''
传入可迭代对象是有序的
应用:坐标
将'坐标'变成 “对象” 的名字
'''
point = namedtuple('坐标', ['x', 'y']) # 第二个参数可以传可迭代对象
# point = namedtuple('坐标', ('x', 'y')) # 第二个参数可以传可迭代对象
# point = namedtuple('坐标', 'x y') # 第二个参数可以传可迭代对象
#传参的个数,要与namedtuple第二个参数的个数一一对应
p = point(1, 2) # 会将 1 ---> x, 2 ---> y
print(p) #坐标(x=1, y=2)
# print(type(p)) #<class '__main__.坐标'>
2、有序字典
python默认无序字典:
dic = dict({'x': 1, 'y': 2, 'z': 3})
print(dic) #{'x': 1, 'y': 2, 'z': 3}
print(type(dic)) #<class 'dict'>
有序字典:
from collections import OrderedDict
order_dict = OrderedDict({'x': 1, 'y': 2, 'z': 3})
print(order_dict, '打印有序的字典') #OrderedDict([('x', 1), ('y', 2), ('z', 3)])
print(type(order_dict)) #<class 'collections.OrderedDict'>
print(order_dict['y'])
for line in order_dict:
print(line)
九、openpyxl模块
它是一个第三方模块
- 可以对Excle表格进行操作的模块
- Excel版本:
2003之前:
excle名字.xls
2003以后:
excle名字.xlsx
- 清华源: https://pypi.tuna.tsinghua.edu.cn/simple
- 配置永久第三方源:
D:\Python36\Lib\site-packages\pip\_internal\models\index.py
写入数据:
from openpyxl import Workbook
# 获取Excel文件对象
wb_obj = Workbook()
wb1 = wb_obj.create_sheet('python工作表1', 1)
wb2 = wb_obj.create_sheet('python工作表2', 2)
# 修改工作表名字: 为 python工作表1 标题修改名字 ---》 大宝贝
print(wb1.title)
wb1.title = '大宝贝'
print(wb1.title)
# 为第一张工作表添加值
# 用法:wb1['工作簿中的表格位置']
wb1['A10'] = 200
wb1['B10'] = 1000
wb1['C10'] = '=SUM(A10:B10)'
#生成Excel表格
wb_obj.save('python.xlsx')
读取数据:
from openpyxl import load_workbook
wb_obj = load_workbook('python.xlsx')
wb1 = wb_obj['大宝贝'] # wb_obj['表名']
print(wb1['A10'].value)
wb1['A10'] = 20
print(wb1['A10'].value)
需求:批量写入100条数据
from openpyxl import Workbook
wb_obj = Workbook()
wb1 = wb_obj.create_sheet('工作表1')
#wb1['表格位置'] = 对应的值
n=1
for line in range(100):
wb1['A%s'% n] = line+1
n += 1
wb_obj.save('工作表.xlsx')
print('excel表格生成成功')
十、subprocess模块
用途:可以通过python代码给操作系统终端发送命令,并且可以返回结果。
import subprocess
while True:
cmd_str = input('请输入终端命令:').strip()
# Popen(cmd命令, shell=True,
# stdout=subprocess.PIPE, stderr=subprocess.PIPE)
# 调用Popen就会将用户的终端命令发送给本地操作系统的终端
# 得到一个对象,对象中包含着正确或错误的结果。
obj = subprocess.Popen(
cmd_str,
shell=True,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE
)
success = obj.stdout.read().decode('gbk')
if success:
print(success,'正确的结果')
error = obj.stderr.read().decode('gbk')
if error:
print(error,'错误的结果')
十一、logging 模块
logging 模块是用来记录日志的模块,一般记录用户在软件中的操作。
import os
import logging.config
#定义三种日志输出格式 开始
standard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \
'[%(levelname)s][%(message)s]' #其中name为getlogger指定的名字
simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s'
id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s'
#定义日志输出格式 结束
注意1:log文件的目录
BASE_PATH = os.path.dirname(os.path.dirname(__file__))
logfile_dir = os.path.join(BASE_PATH,'log_dir')
print(logfile_dir)
注意2:log文件名
logfile_name = 'use.log'
#如果不存在定义的日志目录就创建一个
if not os.path.isdir(logfile_dir):
os.mkdir(logfile_dir)
#log文件的全路径
logfile_path = os.path.join(logfile_dir,logfile_name)
# print(logfile_path)
注意3:log配置字典
LOGGING_DIC = {
'version': 1,
'disable_existing_loggers': False,
'formatters': {
'standard': {
'format': standard_format
},
'simple': {
'format': simple_format
},
},
'filters': {},
'handlers': {
#打印到终端的日志
'console': {
'level': 'DEBUG',
'class': 'logging.StreamHandler', # 打印到屏幕
'formatter': 'simple'
},
# 打印到文件的日志,收集info及以上的日志
'default': {
'level': 'DEBUG',
'class': 'logging.handlers.RotatingFileHandler', # 保存到文件
'formatter': 'standard',
'filename': logfile_path, # 日志文件
'maxBytes': 1024*1024*5, # 日志大小 5M
'backupCount': 5,
'encoding': 'utf-8', # 日志文件的编码,再也不用担心中文log乱码了
},
},
'loggers': {
#logging.getLogger(__name__)拿到的logger配置
'': {
'handlers': ['default', 'console'], # 这里把上面定义的两个handler都加上,即log数据既写入文件又打印到屏幕
'level': 'DEBUG',
'propagate': True, # 向上(更高level的logger)传递
},
},
}
注意4:
def get_logger(user_type):
# 1.加载log配置字典到logging模块的配置中
logging.config.dictConfig(LOGGING_DIC)
# 2.获取日志对象
logger = logging.getLogger(user_type)
return logger
#通过logger日志对象,调用内部的日志打印
logger = get_logger('user')
#记录日志信息
logger.info('只要思想不滑坡,方法总比问题多!')
十二、re模块
一、什么是正则表达式与re模块?
正则表达式:
正则表达式是一门独立的技术, 任何语言都可以使用正则表达式,
正则表达式是由一堆特殊的字符组合而来的。
- 字符组
- 元字符
- 组合使用
在python中,若想使用正则表达式,必须通过re模块来实现。
二、为什么要使用正则表达式?
比如要获取“一堆字符串”中的“某些字符”,正则表达式可以帮我们过滤,并提取出想要的字符数据。
比如过滤并获取 “tank”
'gstankyr9q
- 应用场景:
- 爬虫: re, BeautifulSoup4, Xpath, selector
- 数据分析过滤数据: re, pandas, numpy...
- 用户名与密码、手机认证:检测输入内容的合法性
三、如何使用正则?
import re
需求:检测手机号码的合法性: 要求11位、以13/14/15/19开头的手机号码
# 纯python校验
while True:
phone_number = input('请输入手机号码:').strip()
# not > and > or
if len(phone_number) == 11 and (phone_number.startswith(
'13'
) or phone_number.startswith(
'14'
) or phone_number.startswith(
'15'
) or phone_number.startswith(
'19'
)):
print('手机号码合法!')
break
else:
print('手机号码不合法!')
#re校验
import re
'''
参数1: 正则表达式 ''
参数2: 需要过滤的字符串
# ^: 代表“开头”
# $: 代表“结束”
# |: 代表“或”
# (13|14): 可以获取一个值,判断是否是13或14.
# {1}: 需要获取1个值 限制数量
# []: 分组限制取值范围
# [0-9]: 限制只能获取0——9的某一个字符
'''
while True:
phone_number = input('请输入手机号码:').strip()
if re.match('^(13|14|15|19)[0-9]{9}$', phone_number):
print('合法')
break
else:
print('不合法')
字符组:
- [0-9] 可以匹配到一个0-9的字符
- [9-0]: 报错, 必须从小到大
- [a-z]: 从小写的a-z
- [A-Z]: 从大写A-Z
- [z-A]: 错误, 只能从小到大,根据ascii表来匹配大小。
- [A-z]: 总大写的A到小写的z。
注意: 顺序必须要按照ASCII码数值的顺序编写。
元字符:
https://images2015.cnblogs.com/blog/1036857/201705/1036857-20170529203214461-666088398.png
- 组合使用
- \w\W: 匹配字母数字下划线与非字母数字下划线,匹配所有。
- \d\D: 无论是数字或者非数字都可以匹配。
- \t: table
- \n: 换行
- \b: 匹配单词结尾,tank jasonk
- ^: startswith
- '^'在外面使用: 表示开头。
- [^]: 表示取反的意思。
- $: endswith
- ^$: 配合使用叫做精准匹配,如何限制一个字符串的长度或者内容。
- |: 或。ab|abc如果第一个条件成立,则abc不会执行,怎么解决,针对这种情况把长的写在前面就好了,一定要将长的放在前面。
- [^...]: 表示取反的意思。
- [^ab]: 代表只去ab以外的字符。
- [^a-z]: 取a-z以外的字符。

re模块三种比较重要的方法:
1、re.findall():可以匹配 "所有字符" ,拿到返回的结果,返回的结果是一个列表。
'afwaiahoaw' # a
['a', 'a', 'a', 'a']
2、re.search():在匹配一个字符成功后,拿到结果后结束,不往后匹配。
----> obj ----> obj.group()
'afwaiahoaw' # a
'a'
3、re.match():从匹配字符的 开头 匹配,若开头不是想要的内容,则返回None。
----> obj ----> obj.group()
'afwaiahoaw' # a
'a'
'wfaghoio' # a
None
'''
#findall
import re
str1 = 'sean tank json'
res = re.findall('[a-z]{3}',str1)
print(res)
>>>['sea', 'tan', 'jso']
#search
res = re.search('[a-z]{4}',str1)
#print(res)
print(res.group())
>>>sean
#march
res =re.match('wee',str1)
# print(res.group()) #报错
if res:
print(res.group())
贪婪匹配和非贪婪匹配
example = "abbbbbbc"
pattern = re.compile("ab+")
贪婪模式:正则表达式一般趋向于最大长度匹配,也就是所谓的贪婪匹配。
如上面使用模式pattern 匹配字符串example,匹配到的结果就是”abbbbbb”整个字符串。
非贪婪模式:在整个表达式匹配成功的前提下,尽可能少的匹配。
如上面使用模式pattern 匹配字符串example,匹配到的结果就只是”ab”整个字符串。
所以,我们可以将贪婪模式理解为:在整个表达式匹配成功的前提下,尽可能多的匹配。
将非贪婪模式理解为:在整个表达式匹配成功的前提下,尽可能少的匹配。

print(re.findall('^egon$','egon')) #^xxx$ 开头找,倒着找只能找egon,多一点少一点都不行
print(re.findall('a\nc','a\nc a\tc a1c')) # ['a\nc']
print(re.findall('a\tc','a\nc a\tc a1c')) # ['a\tc']
重复匹配:
. ? * + {m,n} .* .*?
1、. :代表除了换行符之外的任意一个字符
print(re.findall('a.c','abc a1c aAc aaaaac')) #['abc', 'a1c', 'aAc', 'aac']
print(re.findall('a.c','abc a1c aAc aaaaa\nc')) #['abc', 'a1c', 'aAc']
print(re.findall('a.c','abc a1c aAc aaaaa\nc',re.DOTALL)) #['abc', 'a1c', 'aAc', 'a\nc']
print(re.findall('a[a-z]c', 'abc a1 c aac aAcaBc asd aaaaac)) #['abc', 'aac', 'aac']
2、? :代表左边那一个字符重复0次或1次
print(re.findall('ab?','a ab abb babbb')) #['a', 'ab', 'ab', 'ab']
3、* :代表左边那一个字符出现0次或无穷次
print(re.findall('ab*','a ab abb babbb')) #['a', 'ab', 'abb', 'abbb']
4、+: 必须与其他字符连用,代表左侧的字符出现1次或者无穷次
print(re.findall('ab+', 'a ab abbb abbbb a1bbbb a-123')) #['ab', 'abbb', 'abbbb']
5、[]中 + * 不是量词,中间选一个
print(re.findall('a[-+*/]c', 'abc a1 c aAc a-c a/c a *c a+c abasd')) #['a-c', 'a/c', 'a+c']
6、^在[]内代表非
print(re.findall('a[^a-z]c', 'abc aAc aaaaac a-c a/c a *c a+c abasd')) #['aAc', 'a-c', 'a/c', 'a+c']
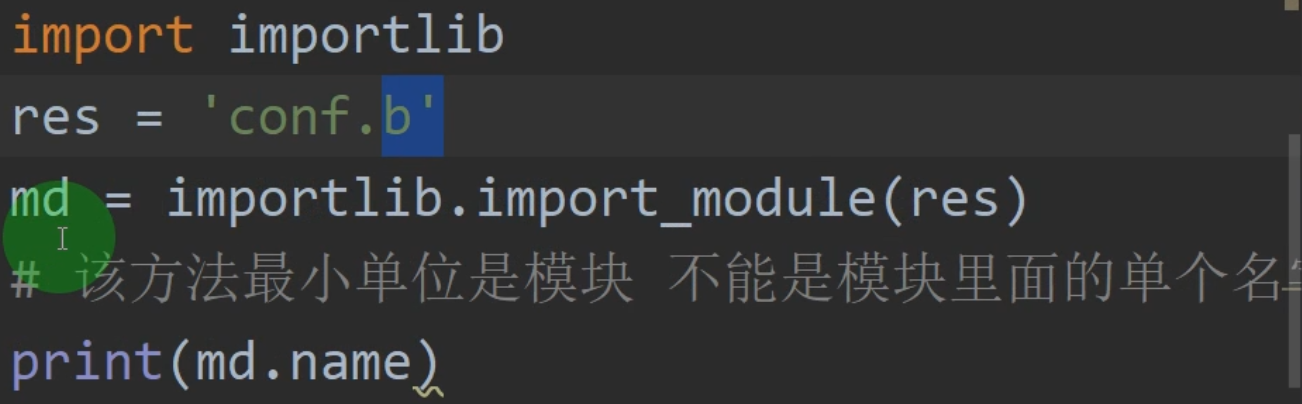
十三 importlib模块的使用
假设有一个conf包,里面放着b.py的模块
b.py
name = 'hank'
若a.py文件中想导入b模块
方法一:
from conf import b
print(b.name)
>>>hank
方法二:
import_module 把b模块变成了对象,md是一个对象,importlib模块可以通过字符串获取路径
十四 partial偏函数
from functools import partial
def func(a,b,c,d):
return a + b + c + d
tes = partial(func,1)
print(tes)
res = tes(2,3,4)
print(res)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号