字符编码介绍
字符编码
1 什么是字符编码?
人类在与计算机交互时,用的都是人类能读懂的字符,如中文字符、英文字符、日文字符等毫无疑问,由人类的字符到计算机中的数字,必须经历一个过程,如下
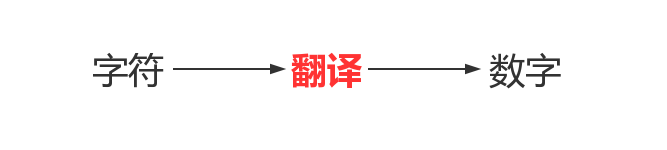
翻译的过程必须参照一个特定的标准,该标准称之为字符编码表,该表上存放的就是字符与数字一一对应的关系。
字符编码中的编码指的是翻译或者转换的意思,即将人能理解的字符翻译成计算机能识别的二进制数字
ASCII表(美国)
1、只有英文字符、数字与表的一一对应关系
2、一个英文字符对应1Bytes,1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
0000 0000
1111 1111
GBK表(中国)
GBK表的特点:
1、只有中文字符、英文字符、数字与表的 一一对应关系
2、一个英文字符对应1Bytes
一个中文字符对应2Bytes
补充说明:
1Bytes=8bit,8bit最多包含256个数字,可以对应256个字符,足够表示所有英文字符
2Bytes=16bit,16bit最多包含65536个数字,可以对应65536个字符,足够表示所有中文字符
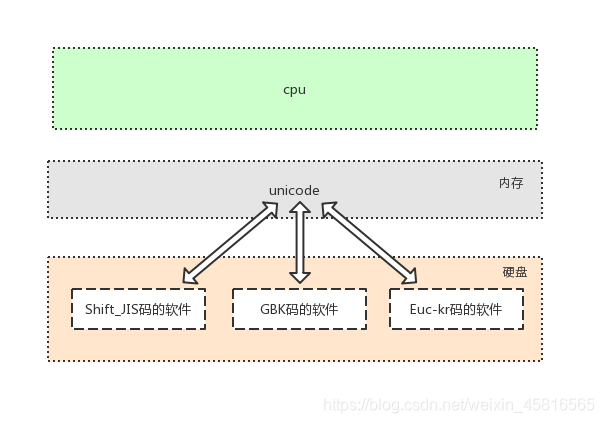
unicode (万国码)
1、所有的字符都用2bytes
2、占用存储空间
3、IO次数增加,程序运行速度缓慢
很多地方或老的系统、应用软件仍会采用各种各样传统的编码,这是历史遗留问题。此处需要强调:软件是存放于硬盘的,而运行软件是要将软件加载到内存的,面对硬盘中存放的各种传统编码的软件,想让我们的计算机能够将它们全都正常运行而不出现乱码,内存中必须有一种兼容万国的编码,并且该编码需要与其他编码有相对应的映射/转换关系,这就是unicode的第二大特点产生的缘由。
utf-8
1、utf-8只与unicode有对应关系
2、所有的英文字符用1个bytes表示,所有的中文字符用3个bytes表示
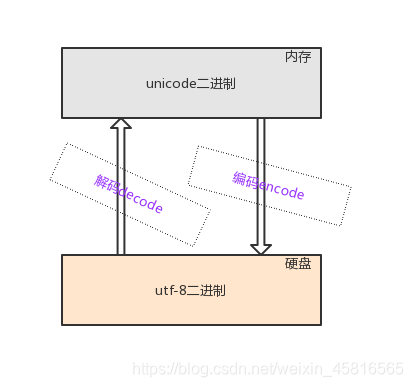
(内存)unicode二进制字符>>>编码>>>(硬盘)utf-8二进制字符
(硬盘)utf-8二进制字符>>>解码>>>(内存)unicode二进制字符
保证不乱码的核心:用什么编码存,就用什么编码取
强调:我们能控制的只是存到硬盘上的编码
- python3解释器用默认utf-8编码
- python2解释器用默认ascii编码
文件头的作用:
#coding:utf-8:是告诉python解释器用我指定的字符编码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号