
从知识图谱到认知图谱: 历史、发展与展望
从知识图谱到认知图谱: 历史、发展与展望
知识图谱的研究热点逐渐出现重数量轻结构化的倾向,这与深度学习和联结主义思想的盛行密不可分。认知图谱依据人类认知的双加工理论,动态构建带有上下文信息的知识图谱并进行推理。本文回顾了知识图谱的发展历史指出认知图谱提出的动机并展望其发展前景。
知识图谱是由谷歌(Google)公司在2012年提出来的一个新的概念。本质上是语义网的知识库。知识图谱由节点和边组成,节点表示实体,边表示实体与实体之间的关系,这是最直观、最易于理解的知识表示和实现知识推理的框架,也奠定了现代问答系统的基础。从20世纪80年代的知识库与推理机,到21世纪初的语义网络和本体论,其核心是早期版本的知识图谱,要么侧重知识表示,要么侧重知识推理,但一直苦于规模小、应用场景不清楚而发展缓慢。2012年,谷歌发布的570亿实体的大规模知识图谱彻底改变了这一现状1;同时,深度学习技术的发展也推波助澜,掀起了知识图谱领域研究的新热潮,特别是以Trans为代表的知识图谱嵌入,以及使用大型知识图谱增强其他应用,如推荐系统、情感分析等。然而,当知识图谱在诸多应用中取得成功的同时,其方法论始终笼罩着几朵“乌云”,如歧义问题、链接困难、关系的冗余与组合爆炸等。虽然针对这些问题的一些修补工作取得了不错的效果,但是想要真正解决这些问题,或许需要在深度学习时代重新考虑知识表示的框架与方法论,因此,认知图谱应运而生。认知图谱可以被解释为“基于原始文本数据,针对特定问题情境,使用强大的机器学习模型动态构建的,节点带有上下文语义信息的知识图谱”。认知图谱的应用框架遵循认知心理学中的“双过程理论”(dual process theory),系统1(system 1)负责经验性的直觉判断,这一黑盒过程提取重要信息,并动态构建认知图谱;系统2(system 2)则在图上进行关系推理,由于认知图谱保留了实体节点上语义信息的隐表示,所以在符号逻辑之外,比如图神经网络等深度学习模型也可以大显身手。
知识图谱
1、早期知识图谱与逻辑推理
知识图谱的理论发源于20世纪下半叶的人工智能热潮中,多组研究者独立地提出相似的理论。它脱胎于众多著名认知心理学家提出的语义网络(semantic networks)理论,最为著名的有Sowa等人在1984年提出的ConceptNet。在符号主义的思潮中,许多早期知识图谱将关系局限为几种特殊的基本关系,如“拥有属性”“导致”“属于”等,并定义一系列在图谱上推理的规则,期望通过逻辑推理实现智能。
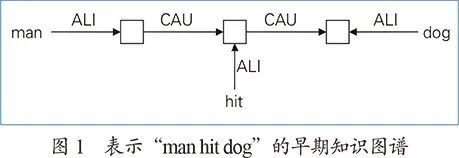
图1为早期知识图谱中的例子,这里的“ALI”表示“相似性”(alikeness),CAU表示“导致”(cause);□为节点,其内容通过EQU“等价”(equal)来标注或者通过ALI来说明其性质或类别。
2、语义网和本体论
然而,早期知识图谱的思路遇到了许多实际的困难。比如不完美的文本数据导致结构解析困难,归约为基本关系的过程需要大量人工参与,语意中的细微差别丢失,完美的推理规则无法穷举等。实际上,这些问题并非来自知识图谱,而是符号主义本身的特性,在之后的实践中,胜利的天平会逐渐向联结主义的方法倾斜。
语义网[7](Semantic Web)是万维网发明者、ACM图灵奖获得者蒂姆·伯纳斯-李(Tim Berners-Lee)提出的一个愿景,在自然语言理解远不及今日发达的20世纪初,通过自然语言进行细粒度的网络自动查询是一种奢望。即使是今天,先进的语音助手(例如Siri等),依旧只能处理相当有限的操作,但是自然语言理解技术的飞速进步也带来了曙光。当时的Tim则另辟蹊径,如果网页能将自己本身的信息用三元组标签的形式记录下来,方便机器理解,那么语义搜索就很容易实现。
为了实现这一目标,人们设计了资源描述框架(RDF)描述语言和描述本体的RDFS/OWL,但是由于互联网创作者们并不积极,语义网时至今日仍然未能得到很好的实现,相关话题的研究也逐渐被知识图谱所代替。然而,三元组的结构化信息和本体研究中积累的技术却成为了宝贵的知识财富。
3、大规模知识图谱
2012年发布的谷歌知识图谱再次将这个领域带入聚光灯下,然而,构建庞大而高质量的知识图谱并不容易。Freebase是谷歌知识图谱的前身,它整合了包括许多私人维基在内的大量网络资源。另一个常用的知识图谱是DBpedia,它从维基百科中抽取结构化的知识再进行本体的构建。通过结构化,用户可以使用SPARQL语言进行查询。YAGO也是开源知识图谱,被应用于IBM Waston问答系统。
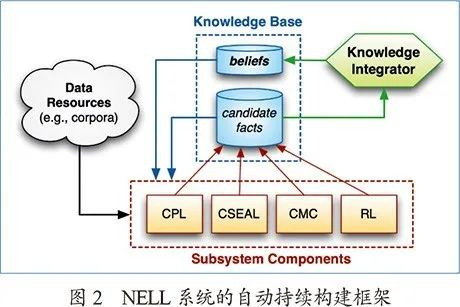
NELL是卡耐基梅隆大学教授汤姆·米切尔(Tom Mitchell)带领开展的知识自动学习。NELL项目开启了一个机器学习实现知识图谱构建的浪潮,目标是持续不断地从网络上获取资源并进行事实发现、规则总结等,里面涉及到命名实体识别、同名消歧、规则归纳等关键技术。图2是NELL系统的自动持续构建框架。ArnetMiner是清华大学知识工程实验室构建的面向科技领域的知识图谱,项目实现了高精度学者画像、同名消歧、智能推荐、趋势分析等关键技术。该工作获得了ACM SIGKDD的时间检验论文奖(Test-of-Time Award)
4、深度学习时代的知识图谱
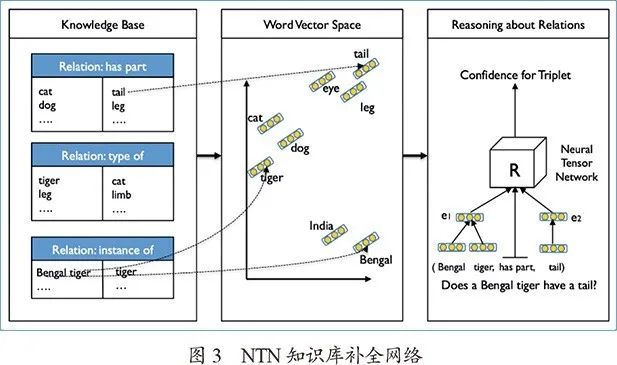
深度学习时代的知识图谱拥有大量的实体和关系,然而大量不同的关系上很难定义逻辑规则,在知识图谱上“推理”也转入黑盒模型预测的范式。Bordes等人的知识库结构嵌入和Socher等人的Neural Tensor Network(NTN)率先将神经网络引入知识图谱的研究,特别是NTN将知识图谱中实体和关系的单词嵌入的平均值作为该节点的表示,训练神经网络判断(头实体,关系,尾实体)的三元组是否为真,在知识图谱补全(推理)任务中取得了很好的效果,图3为NTN知识库补全网络。然而,简单地用词向量表示实体本身,会忽略它们独特的符号特征:例如美国网红“James Charles”和20世纪著名时尚设计师“Charles James”的词向量平均结果相同,可是其知识图谱上的相关属性有很大差别。
因此,研究者将更多的目光转向大型知识图谱自身的嵌入训练,其中最为优雅有效的开创性工作是Bordes等人的TransE。该算法的目的是为知识图谱中每个关系或实体学习一个d维向量表示,对于知识图谱中任意的三元组事实(h, r, t),算法要求它们的向量表示满足h+r ≈ t,这个想法是来自词向量的类似特性,为了训练得到这样的嵌入,算法定义目标函数:
其中d(h+r, t)是向量h+r与t之间的距离,通常使用欧几里得距离;h'和r'是负采样得到的样本,最终使用间隙损失函数(marginal loss)来进行比对学习。
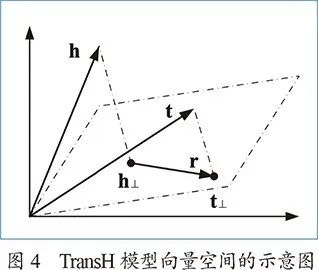
后来的一系列工作无论从命名上还是框架上,都延续了TransE的风格进行改进。例如为了解决一对多和多对多的复杂关系,TransH将关系建模为平面而不是向量,进而要求头尾实体的嵌入向量在该平面上的投影满足,图4为TransH模型向量空间的示意图。这个方向的众多改进工作,如TransR、TransG等在Wang等人的综述中得到了很好的概括。
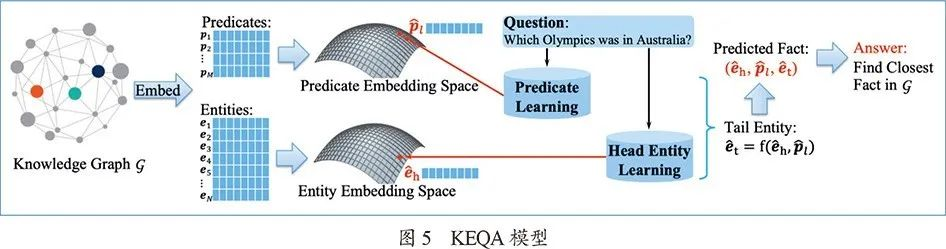
知识图谱的应用中,最主要的是基于知识图谱的问答系统(KBQA),如图5所示。由于知识图谱本身是对机器友好的结构,如果有了相应的SPARQL语句,即可很容易地在知识图谱中查询到最终的答案。因此,难度主要集中在如何将自然语言问题解析为知识图谱内存在的关系或者实体的合法查询。针对这个问题,Dai等人提出了CFO模型,Huang等人提出了KEQA,后者预测实体的嵌入并从知识图谱嵌入中寻找附近的结果,把自然语言处理中的预测模型与知识图谱嵌入的工作结合了起来。
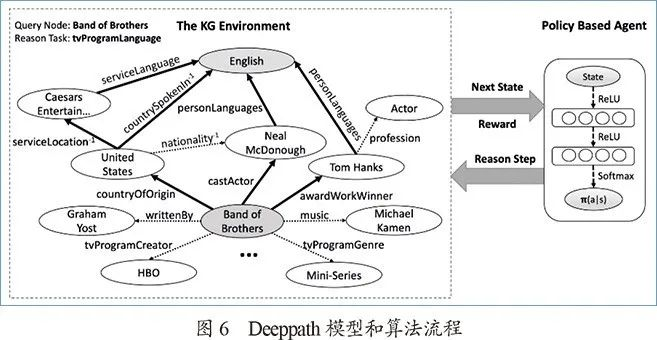
知识图谱另一个重要的方向是复杂问题推理。知识图谱往往是不完备的,复杂问题往往在图谱中没有明显答案,甚至没有对应的关系。但是,通过多步推理,我们仍有可能从图谱中获得对应的答案。这个方向较为著名的工作有Xiong等人的Deeppath(见图6),使用强化学习的方法探索知识图谱中的推理路径。这个思路也启发了后续的一些工作,例如使用策略梯度的MINERVA和Lin等人奖赏塑造等。
5、知识图谱的缺陷
知识图谱的缺点本质上都是“二元一阶谓词逻辑”作为知识表示本身的缺陷带来的。长久以来,知识表示是研究者孜孜不倦追寻探索的话题,完全依靠(头实体,关系,尾实体)这样的命题,尽管能表示大部分简单事件或实体属性,但对于复杂知识却束手无策。在对知识理解的细粒度要求越来越高的今天,这一缺点成为了知识图谱的阿喀琉斯之踵。
“李政道和杨振宁共同提出宇称不守恒的理论”,这个事实如果要计入知识图谱,通常不得不记作(杨振宁和李政道,提出,宇称不守恒理论)”,而这样头实体就无法与两位科学家的其他信息链接;如果将头实体拆开,则无法反映“共同提出”,与事实不符。归根结底,“……和……共同提出……”是一个三元关系,无法被知识图谱直接记录。如果说这个例子可以通过在知识图谱中引入超边(hyperedge)来改进,那么下面的二阶谓词逻辑的例子则完全超出了现有框架。“克隆羊的各项属性都与本体相同”,在知识图谱中,各项属性都由不同关系刻画,因此这句话无法被知识图谱所记录;在更宽泛的知识库理论中,这通常被列为“规则”,然后执行大量枚举操作,去“推理”出克隆羊的各项关系属性,而对于规则的理解和形式化往往带有浓厚的人工色彩,一条高阶逻辑也可能涉及到海量的实体,使得图谱十分冗余。我们最后关注的是知识图谱构建过程中的信息约减带来的实体链接困难。知识的最终来源是我们所处的世界,从原始的语音、图像等数据到文本再到知识图谱,信息量不断被约减,只有最核心的内容被保留下来。然而,忽略了原始文本中人物的具体经历等信息后,会导致同名人物难以消歧。上述问题表明知识图谱的革新迫在眉睫,由于自然语言处理的极大进步,BERT等模型带来的文本理解和检索能力使得我们完全可以在原始文本上进行理解和推理,例如Chen等人的DrQA就是使用神经网络直接从文本中抽取问题答案,掀起了开放领域问题的新热潮。另一方面,我们必须保持知识图谱的图结构带来的可解释性和精准稳定的推理能力。因此,认知图谱应运而生。
认知图谱
认知图谱主要有三方面创新,分别对应人类认知智能的三个方面:
1.(长期记忆)直接存储带索引的文本数据,使用信息检索算法代替知识图谱的显式边来访问相关知识。2.(系统1推理)图谱依据查询动态、多步构建,实体节点通过相关实体识别模型产生。3.(系统2推理)图中节点产生的同时拥有上下文信息的隐表示,可通过图神经网络等模型进行可解释的关系推理。本质上,认知图谱的改进思路是减少图谱构建时的信息损失,将信息处理压力转移给检索和自然语言理解算法,同时保留图结构进行可解释关系推理。事实上,认知图谱正是由人类认知过程所启发,“快速将注意力定位到相关实体”和“分析句子语意进行推断”是两种不同的思维过程。在认知学里,著名的“双过程理论”认为,人的认知分为两个系统,系统1是基于直觉的、无知觉的思考系统,其运作依赖于经验和关联;而系统2则是人类特有的逻辑推理能力,此系统利用工作记忆 (working memory)中的知识进行慢速但是可靠的逻辑推理,系统2是显式的,需要意识控制,是人类高级智能的体现。
1、多跳阅读理解的挑战
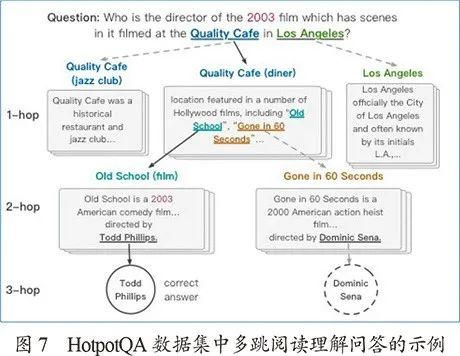
认知图谱首先被Ding等人提出并应用于多跳开领域阅读理解问答(见图7)中。在传统方法中,开领域问答往往依靠大规模的知识图谱,而阅读理解问答一般面向单段,此时阅读理解的自然语言处理(NLP)模型(例如BERT),可以直接处理。DrQA系统中开创性地使用一个简单的方法将阅读理解应用于开领域问答,即先根据问题在语料(维基百科)中检索出少量相关段落,再在这些段落中进行NLP的处理。
而认知图谱问答(CogQA)的文章中认为,这样的方法在多跳问答中存在“短视检索”的问题,即后几跳的文本和问题的相关性很低,很难被直接检索到,导致效果不佳。另一方面,自从BERT横空出世,单文本阅读理解问答的基准数据集SQuAD很快超过了人类水平,但是同时,大家也在反思这些模型是否真的能够做到阅读“理解”。在Jia等人的文章中,他们展现了一个有趣的例子:原文为:“In January 1880, two of Tesla's uncles put together enough money to help him leave Gospić for Prague where he was to study.”问题为:“What city did Tesla move to in 1880?”大多数模型都能轻松正确回答 “Prague”。然而,一旦我们在原文后面增加一句“Tadakatsu moved to the city of Chicago in 1881.”,这些模型将会以很高的置信度回答“Chicago”——这仅仅是由于这句话的形式与问题特别像,即使关键的信息都对不上。这暗示了基于深度学习的NLP模型,主要类似于认知中的系统1,我们如果要进一步进行稳健的推理,就必须考虑系统2。另外,可解释性不足也是之前多层黑盒模型饱受诟病的弊端之一。这些模型往往只需要输入问题和文本,然后输入答案在文本中的位置;在多跳阅读理解中,每一跳都是有原因的,如果不能给出合理的答案解释,则无法证明真的“理解”了文本。
2、认知图谱问答
认知图谱问答(见图8)提出了一种新颖的迭代框架:算法使用两个系统来维护一张认知图谱,系统1在文本中抽取与问题相关的实体名称并扩展节点和汇总语义向量,系统2利用图神经网络在认知图谱上进行推理计算。
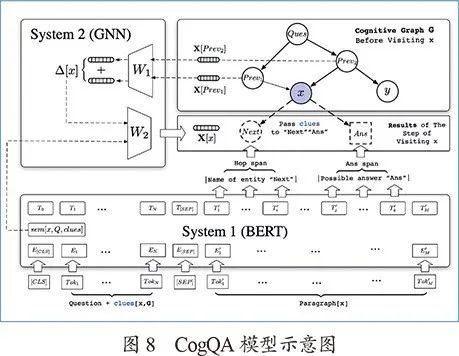
正如之前提到的,人类的系统1是“无知觉的”,CogQA中的系统1也是流行的NLP黑盒模型,例如BERT。在文章的实现中,系统1的输入分为三部分:问题本身、从前面段落中找到的“线索”、关于某个实体x(例如x =上文中的电影Old School)的维基百科文档。
系统1的目标是抽取文档中的“下一跳实体名称”和“答案候选”。比如图7例子中,从“Quality Café”的段落中抽取电影“Old School”和“Gone in 60 Seconds”作为下一跳的实体名称,在“Old School”的段落中抽取其导演“Todd Phillips”作为答案候选之一。这些抽取得到的实体和答案候选将被作为节点添加到认知图谱中。此外,系统1还将计算当前实体x的语义向量,这将在系统2中用作关系推理的初始值。接下来,每一个抽取出的“下一跳实体名称”或“答案候选”都将在认知图谱中建立一个新的节点,并进行下一步迭代。同时系统2在认知图谱上进行推理计算,文中使用图神经网络(GNN)实现隐式推理计算——每一步迭代都是前续节点将变换过的信息传递给下一跳节点,并更新目前的隐表示。最终所有的“答案候选”点的隐表示将通过一个带有softmax函数的全连接网络来判断哪个是最终答案。在认知图谱扩展过程中,如果某被访问节点出现新的父节点(环状结构或汇集状结构),表明此点获得新的线索信息,需要重新扩展计算。最终算法流程借助前沿点队列形式实现。CogQA除了在HotpotQA数据集上取得三个月的第一名效果,图9案例分析中的认知图谱也表明了其可解释性方面的优越性:
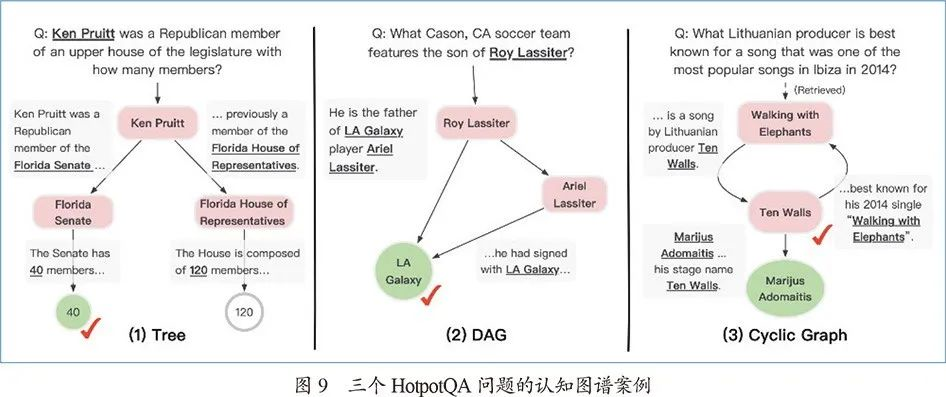
图9(1)的树形图中,回答问题的关键在于判断Ken Pruitt所在的组织是“Senate”(参议院)还是“House of Representatives”(众议院),模型通过判断“upper house”(上院,在美国是参议院的别称)和“Senate”的语意相似性做出回答;图9(2)是有向无环图,多条推理路径可以增强判断;图9(3)是模型得出“错误答案”的例子,数据集的标准答案是“Ten Walls”,而CogQA给出的是“Marijus Adomaitis”,但是如果检查认知图谱,会发现Ten Walls不过是Marijus Adomaitis的艺名,模型给出了一个更加准确的答案,这种可解释性带来的好处是传统黑盒模型所不具备的。
3、认知图谱发展展望
在自然语言理解工具迅速发展的今天,认知图谱方兴未艾,许多有价值的方向亟待探索:
1.系统2的推理如何实现?现在的方法(如图神经网络)虽然使用关系边
作为归纳偏置,却仍然无法执行可控、可解释、鲁棒的符号计算。系统1如何为现有的神经-符号计算方法提供可行前续工作?
2. 文本库应该如何预处理或预训练,才能有助于访问相关知识的检索?
3. 另辟蹊径?本文介绍的认知图谱是基于认知科学的双通道理论,是否还存在其他支撑理论?或者直接构建一个符号推理和深度学习相结合的新型学习架构?
4.如何与人类记忆机理相结合?人类记忆机理包括长期记忆和短期记忆,但其工作模式和工作机理并不清楚。长期记忆可能存储的是一个记忆模型,记忆模型不再是一个概念的网络,而是一个计算模型的网络。
5. 认知图谱如何与外界反馈相结合是一个全新的问题。当然这里可以考虑通过反馈强化学习来实现,但具体方法和实现模式还需要深入探讨。
总结
近年来随着深度学习的兴起,知识图谱的相关技术也蓬勃发展,同时一些缺点也暴露出来。本文回顾了知识图谱的发展历史,总结了发展现状并举例说明了现有知识图谱本身的缺陷。同时,我们深入探讨了前景广阔的认知图谱,讨论了认知图谱在问答系统中的应用。最后,我们展望了未来认知图谱可能的发展方向,探讨通过认知图谱促进人工智能从感知到认知跨越的途径。
作者简介
丁铭
CCF学生会员。清华大学博士生。主要研究方向为自然语言处理、图学习和认知智能。dm_thu@qq.com
唐杰
CCF杰出会员,CCCF前动态栏目主编,CCF学术工委主任。清华大学计算机系教授。主要研究方向为人工智能、知识图谱、数据挖掘、社交网络和机器学习。jietang@mail.tsinghua.edu.cn

