
基于统计语言模型的文本纠错方法研究
基于统计语言模型的文本纠错方法研究
【摘要】利用文本纠错技术来查找数据中的错误信息并纠正,提高信息准确度与质量,如今已成为自然语言处理技术中面临的重要课题。本文中,我们通过抓取大量高质量语料数据并通过基于统计训练生成N-Gram语言模型作为纠错主要方法,同时设计相似匹配算法来辅助提高混淆词纠错效果。在随机选择的数据集上,我们可得出本文设计文本纠错方法的有效性和准确性,并且其中Tri-Gram语言模型的纠错效果更好。
【关键字】 文本纠错;语料数据;语言模型;N-Gram
1. 引言
文本数据中错误信息的纠正属于自然语言处理研究的一个领域。随着信息量的不断增加,纠正错别信息以及筛除冗余信息也愈显得重要,文本纠错技术的研究以及应用也得到了越来越多的关注。人们在进行语音识别后处理技术,检索技术,正常的网络交流等。文本数据中出现的错误信息,很大程度上会导致资源的浪费,或是无法收到理想的信息反馈。利用文本纠错技术来查找数据中的错误信息并纠正,提高信息准确度与质量,如今已成为自然语言处理技术中面临的重要(Bassil, Y. , & Alwani, M,2012)。
由于汉语本身特点,中文文本的纠错并不能像英语文本纠错工具那样得到较大的应用。原因在于中文的使用十分灵活,目前没有完整的语言学知识能用于计算机中;中文的错误类型较英文更为复杂,错误类型涵盖中文字词拼音音调错误、平翘舌音错误、前后鼻音混淆等错误,在纠错实现上也较为复杂与困难;中文词语间没有明显的分割标记,在处理中文文本前需进行分词等处理。针对以上问题,本文设计了文本相似匹配技术和基于N-Gram语言模型的纠错方法。可实现在文本纠错过程中迅速定位错误词位置并将其纠正,确保文本数据的正确性。
此外,本设计考虑通过用户信息反馈来扩充语料数据同时更新优化语言模型,既减少了开发成本又实现了工具开发的可扩展性。
2. 相关研究
在本文所设计的文本纠错方法中使用的是N-Gram统计语言模型,N-Gram模型存在没有使用语义深层的约束规则和因数据稀疏而导致的数据平滑等问题(Che, J., Chen, H., Zeng, J., & Zhang, L. J,2018)。该模型的建立根据相互之间没有任何遗传属性的离散单词而构建,因此其不具备连续词向量在语义上的优势。但是它包含了前面N-1个词所提供的全部信息,这些词对已知关键词的出现具有约束作用,即在已知词权重很大的情况下,使用N-Gram语言模型效果会相对较好。除N-Gram模型外还有很多其他模型,例如2007年Peter Norvig在设计和实现“Spelling Corrector”时只简单的应用了朴素贝叶斯概率以及计算关键词的先验概率,这实际上就是N-Gram统计语言模型的概率基础;2014年的英文文本纠错比赛中斯坦福大学所应用的NLC模型就是基于RNN+Attention模型的基础;还有2016年阿里巴巴参赛中文语法纠错比赛中所应用的RNN+CRF模型,也获得不错的纠错效果。也有一些研究是从文本中提取特征信息并结合语言模型来进行查错纠错,同时也得到了不错的效果(Coustaty, Mickaël, Antoine Doucet, Adam Jatowt, and Nhu-Van Nguyen,2018)。
本文在设计文本纠错方法前分析了中文文本常见错误如:输入法拼写错误、知识性错误、混淆词错误等错误类型,建立包含常见拼音错误词语和字形错误词语的混淆词词集进行辅助纠错,提高了词粒度级的纠错率;同时抓取数据,建立语料库并将语料数据进行清洗得到高质量语料库,利用KenLM训练语料库得到N-Gram语言模型。结合以上两种方法作为本文的纠错方法,与现有的文本纠错工具进行比对,得出纠错率最高时的N的取值,即为最佳文本纠错方法。
3. 研究内容
通过对国内外已有的纠错技术进行深入研究和分析,本文设计了相应的中文文本纠错方法,最后通过数据测试对比得出本文研究方法的正确性以及分析不足。其中主要研究内容为文本纠错方法的设计与实现,以及纠错工具的测试及优化(Hoeijmakers, M. , Debree, E. , & Keijzer, M.,2013)。
所设计的法包含的基于相似匹配的纠错技术,即根据中文常见混淆类错误进行混淆词集的建立,通过文本分词比照,对文本中混淆类错误进行快速纠正。
基于统计的语言模型实现的文本纠错技术,是通过N-Gram语言模型并利用字词的N元接续关系来实现的。对于字粒度出现的错误检测,利用语言模型困惑度(PPL)检测某字词的似然估计值是否低于句子文本平均值,若是则判定该字疑似错误。通过定位所有疑似错误后,取所有疑似错误字的音似字、形似字并结合N-Gram语言模型得到排序,取得最优结果。对于词粒度级出现的错误,查错及纠错过程亦是如此。基于统计的研究方法会依赖大规模的语料数据,在具体实现阶段,我们也需要抓取大量的语料并进行清洗,以此来保障语料库的质量以及研究方法的鲁棒性(Fu, K., Huang, J., & Duan, Y.,2018)。
结合以上两种主要技术实现的文本纠错方法理想情况下可以快速纠正常见中文错误,尤其是上文所提及的混淆词类错误。在测试及优化阶段考虑数据传输反馈,可以实时更新语言模型,并通过测试验证构想。
4. 研究方法
4.1.N-Gram语言模型
我们已经构想好设计与实现方案为基于统计的语言模型纠错与建立混淆词词集的拟定方法来实现目标工具的实现。语言模型是自然语言处理中的最为重要的一部分,占有很高的地位,尤其是在基于统计的语音识别、机器翻译、语法分析及语义分析等相关研究中得到了广泛应用,其中N-Gram语言模型有时也称为N元模型,随着语料库的不断建立与添加完善,人们开始通过基于统计和概率的N-gram语言模型,来进行对文本数据的预测以及判断其正确性;另一方面,N-Gram的另外一个作用是用来评估两个字符串之间的差异程度。这是模糊匹配中常用的一种手段。其本身也指一个有N个单词的集合,单词是有先后顺序的,并排成序列,且单词之间不要求互异。如果当前关键词的出现依赖于其前面的一个词,即为Bi-Gram(N=2);若当前关键词的出现依赖于前面两个词,即为Tri-Gram(N=3),以此类推(Hsieh, Y. M., Bai, M. H., Huang, S. L., & Chen, K. J.,2015)。
Bi-Gram计算公式:
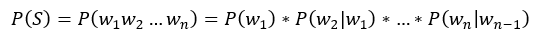
Tri-Gram计算公式:
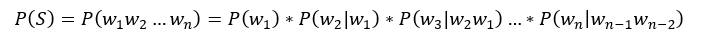
因为n可以取任意整数,但是通常我们取到Bi-Gram,Tri-Gram即可。其中每一项的条件概率的计算就要用到极大似然估计。
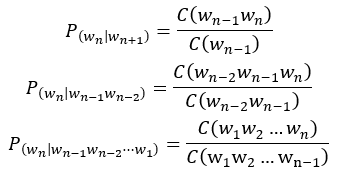
具体应用可以用Bi-Gram来举例。存在简单文本数据如下

其中“我”出现了三次,“我想”出现了两次,因此可计算出概率:
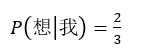
当然如果一句话很长,那么概率的乘积很有可能会无限接近于0,遇到这种情况便可以用log以10为底的对数计算来解决。
4.2.语料库设计
N-Gram语言模型需要基于大规模的语料数据来进行训练,我们通过抓取人民日报语料数据并进行去标签及分词处理,获得高质量的语料数据。并根据纠错需要还需建立混淆词词集,汉语字典词典,近似音字典以及形近字字典。其中汉语字典为汉语语料库获取,其中包含通用规范汉字8105个,一级字3500个,二级字3000个,三级字1605个;汉语词典为汉语语料库获取,其中包含常用词五十五万左右,并标明词性词频。同时我们采用开源统计语言模型训练工具KenLM来对已有语料数据进行训练,生成语言模型中包含数据有关键字词的回退权重以及N-Gram的条件概率。我们根据参数调控生成词数依赖不同的语言模型,用于测试比对。由于使用训练语言模型时需要将语料进行分词处理,已有语料数据带有词性标注并且未分词,所以需将其进行处理得到的理想语料库。
4.3.纠错功能设计
在获得待纠错文本后,我们采用滑动窗口并结合语言模型进行N元打分计算。同时将窗口大小设置为N的位置的打分结果进行平均绝对离差计算,并通过设置阈值来衡量打分结果,不在阈值范围内的即为疑似错误。将疑似错误的字词通过已建立的词典、字典进行字音字形的替换,构成纠错候选集合。将候选纠错字词代入句子中,通过PPL困惑度计算句子通顺程度并进行计算得分。其中PPL困惑度是由语言模型分配给测试集的概率的乘法逆,由测试集中的字数标准化。如果语言模型可以预测来自测试集的看不见的单词,即𝑃最高;,那么这样的语言模型就更准确了。语言模型困惑度计算公式如下:
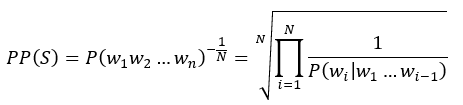
其中S代表句子,N代表句子长度,𝑃()代表第i个词的概率。这样由公式可得PPL越小,𝑃()则越大那么我们所期待的句子的概率也就越高即PPL计算得分越高,理解为句子的通顺程度越高,这样便获得纠错正确文本。
由于中文的复杂性,有些字词我们很难通过语言模型纠错的方法来实现,这便要应用我们设计好的相似匹配纠错方法。基于中文词语中常见的拼音音调错误、平翘舌音错误、前后鼻音错误等建立混淆词词集,将该词集配置到切词器中,对文本数据中出现在词集中的词进行第一优先级切分。由于混淆词词集中已经建立好混淆词与正确词的一一匹配,所以预测会很快实现相应纠错任务(Samanta, S., & Mehta, S.,2017)。
5. 研究结果
5.1.语言模型训练结果
查看语言模型Tri-Gram的训练结果,显示结果有以下几个特点:
(1)以<s></s>标记符来表示句子的开始和结束。
(2)引入<unk>字符来表示未登录的词。如上图所示,<unk>的计数为0,即文本数据中无未登录词。

(3)文档中第三列数据代表关键词的回退权重,即该词的后续接词能力。该数据的计算分析为:首先得到原始计数继而进行调整计数。调整计数会将搭配出现频率较小的词给予一个较低的计数。公式如下:
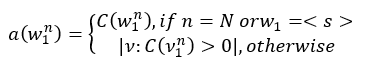
其中w代表N-gram,若n=2即表示Bi-Gram;c(w)则代表原始计数,n=2时,即代表Bi-Gram的原始计数;a(w)则表示调整计数,其中Bi-Gram的调整计数与原始计数相同。经过调整计数后引Discounting,其思想是将N-Gram的一部分概率分给出现频数较小的字、词。原理在于出现频数较高的词已经有了比较好的估计,那么从其计数数值上减去一个较小的数值,对其影响不是很大。而所减去的这个较小值D的计算公式如下:
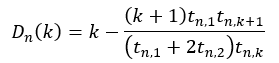
k=0时,D(0)=0;对于k大于3的情况,D(k)=D(3);n∈[1,N],即有N=2时,n=[1,2];t则表示出现k次的N-Gram的个数。
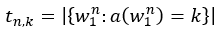
综上可以计算出N-Gram的概率,但是此概率并不是完整的N-Gram概率,因为分子被减去了D值,所以也称这样的N-Gram概率公式为pseudo probability。计算公式如下:
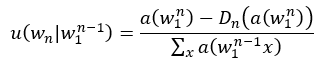
因为每个词后接其他词的能力不同,所以这种衡量权重称之为回退权重。其计算表达式为:
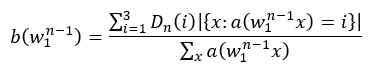
综上可以计算出每个字的回退权重,并加其进行以10为底的log计算,最后得出数据。
第一列数据代表N-Gram的条件概率,其数据的计算分析为:为解决个别词出现频率过小,可以采用interpolation的方法来实现Bi-Gram与Unigram的结合,计算公式如下:
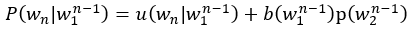
该过程会不断递归,直至Unigram的停止,其中Unigram的插值由uniform distribution来表示,表达式如下
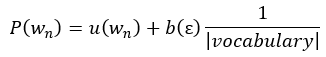
其中|vocabulary|代表词汇量的大小,ε代表空字符串。将计算所得概率进行以10为底的log计算,得出关键字N-Gram的条件概率。
5.2.文本纠错结果
我们输入测试句子:“少先队员因该为老年人让座”,可看出检测疑似错误。
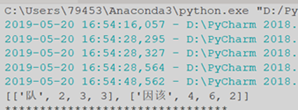
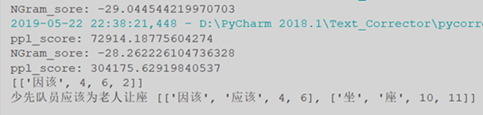
以上通过语言模型打分和平均绝对离差算法将低于阈值的字词找出,并将其作为疑似错误。然后通过字音字形查找以及随机汉字替换,建立纠错候选集。将纠错候选集替换原疑似错误字词的位置,应用PPL困惑度计算句子通顺程度,结合打分结果得出最优解。我们选出一处为例分析,其中带有“坐”的错误文本打分为-29分,而带有“座”正确文本的打分为-28分;带有“坐”的文本PPL为72914,带有“座”的文本PPL为304175,综上可得N-Gram打分模块结果较高的为最优解,并验证其PPL得分更高,语句更通顺。所以应将 “坐”纠正为“座”,得到正确文本。
5.3.数据集测试结果
选择测试样例包含700句随机文本,句子中含有错误处均在一个以上。采用Tri-Gram与Bi-Gram语言模型进行纠错.其中完全纠错率是指将句子中的错误完全纠正,纠错率是指可以改正句子中的错误,但未必修改正确。测试分析如表1所示。
表1 测试结果分析
|
语言模型 |
纠错率 |
完全纠错率 |
|
Tri-Gram |
85.7% |
77.1% |
|
Bi-Gram |
23.1% |
14.3% |
可以看出采用Ti-Gram语言模型的纠错率与完全纠错率比较高,分别达到85.7%和77.1%。与Bi-Gram对比较为明显,因此本工具在最后的模型选择,采用Tri-Gram模型进行纠错。
6. 讨论
通过对测试数据集的测试,我们可看出Tri-Gram语言模型的纠错效果较好,并选用其作为纠错工具的语言模型。由于本系统的语料库在开始建立时即为固定不变的,所以对于一些语料库中未曾出现的词,纠错效果便会大打折扣。因此本系统设计数据反馈机制,将用户使用时产生时候文本传输至后端并通过人工标注进行修正,最后通过服务器端训练并生成新的模型传输回客户端,这样便实现模型的实时优化与更新(Sun, Y., Zhang, Y., & Zhang, Y.,2016)。由于选择文本数据会存在差异性,所以也会产生不同结果,采用上述相同的文本数据进行测试我们可看出系统的优化效果,结果如下表2。
表2 优化后测试结果分析
|
语言模型 |
纠错率 |
完全纠错率 |
|
优化前 |
85.7% |
77.1% |
|
优化后 |
92.3% |
82.0% |
7. 结论
基于相似匹配计术与N-Gram语言模型的文本纠错系统,通过语料数据的预处理建立语料库,同时通过网络资源建立所需的混淆词词集等数据集供纠错使用。在纠错使用中可实现基于混淆词的文本错误完全纠错。并且在测试集中,基于Tri-Gram语言模型的纠错可达到完全纠错率77%左右,实时更新语料库并优化模型后的完全纠错率可达到82%左右,保证了纠错系统的质量。
纵观本文设计与实现的文本纠错系统,仍存在一些问题需要改进与研究:
(1) 开发所建立的混淆词词集有限,并不能涵盖生活中常见的口语错误及文本输入错误。在未来的研究中,除普通话的文本纠错,可以考虑建立方言转换的常见错误。
(2) 语言模型采用的为N-Gram模型,该模型较多应用于模糊查询,句子相似度比较以及文本纠错。本系统在更新添加用户数据至语料库时,随着数据的增加会导致数据稀疏,同时会导致数据平滑问题。另外本工具纠错具有一定局限性,大部分限制于近似音与字形错误。对于语序错误及语义错误并不能纠正,所以在未来的研究中会优化或采用其他语言模型来进行接续研究(Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin,2017)。
(3) 随着语料库的规模增大,模型训练时间也会变长,这样会导致前段因长时间收不到训练完成的反馈而未响应。在今后的研究中可优化数据传输方式和模型训练方法。
由于中文文本的复杂多样性,相应的文本纠错方法也是具有对应的多样性,在接下来的研究与算法设计上,我们也会考虑RNN+CRF,并尝试在文本中提取特征信息并结合语言模型来进行纠错功能的优化。
参考文献
Bassil, Y. , & Alwani, M. . (2012). Ocr post-processing error correction algorithm using google online spelling suggestion. journal of emerging trends in computing & information sciences, 3(1), 90-99.
Che, J., Chen, H., Zeng, J., & Zhang, L. J. (2018, June). A Chinese text correction and intention identification method for speech interactive context. In International Conference on Edge Computing (pp. 127-134). Springer, Cham.
Coustaty, Mickaël, Antoine Doucet, Adam Jatowt, and Nhu-Van Nguyen. "Adaptive Edit-Distance and Regression Approach for Post-OCR Text Correction." In International Conference on Asian Digital Libraries, pp. 278-289. Springer, Cham, 2018.
Fu, K., Huang, J., & Duan, Y. (2018, August). Youdao’s Winning solution to the NLPCC-2018 Task 2 challenge: a neural machine translation approach to Chinese grammatical error correction. In CCF International Conference on Natural Language Processing and Chinese Computing (pp. 341-350). Springer, Cham.
Hoeijmakers, M. , Debree, E. , & Keijzer, M. . (2013). English spelling performance of dutch grammar school students. Dutch Journal of Applied Linguistics, 2(2), 152-169.
Hsieh, Y. M., Bai, M. H., Huang, S. L., & Chen, K. J. (2015). Correcting Chinese spelling errors with word lattice decoding. ACM Transactions on Asian and Low-Resource Language Information Processing (TALLIP), 14(4), 1-23.
Samanta, S., & Mehta, S. (2017). Towards crafting text adversarial samples. arXiv preprint arXiv:1707.02812.
Sun, Y., Zhang, Y., & Zhang, Y. (2016, May). Chinese Text Proofreading Model of Integration of Error Detection and Error Correction. In Workshop on Chinese Lexical Semantics (pp. 376-386). Springer, Cham.
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. In Advances in neural information processing systems (pp. 5998-6008).

