
【论文笔记】Information Extraction over Structured Data:Question Answering with Freebase
- 摘要:
- 本文通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个结点或边都可以作为候选答案。通过观察问题,依据某些规则或模板进行信息抽取,得到表征问题和候选答案特征的特征向量,建立分类器,通过输入特征向量对候选答案进行筛选,从而得出最终答案。
- 方法:
- 作者将知识库视为 ‘topic’ 互相连接的集合。一个自然语言问题可能包括一个或几个 topic ,那么我们就可以在知识库中找相关的topic,然后在与topic节点距离几跳的相关节点中提取答案。作者将这样的视图称为 topic graph,假设答案可以在图中找到。作者的目标是通过大量组合问题和主题图的判别特征来最大程度地自动化答案提取过程。
-
- 自然语言查询KB的一个挑战是与KB的语法相比,查询的相对非正式性。比如问题:who cheated on celebrity A?答案可以通过知识库关系 celebrity.infidelity.participant 检索得到,但是短语 cheated on 和正式知识库关系的连接是不明确的。为了解决这个问题,目前最好的尝试是从Reverb 谓词参数三元组映射到Freebase关系三元组。
- 背景:
- 问答知识库面临两个重大挑战:模型和数据。
- 模型的挑战在于发现问题的最好意义表示,将它转化为查询并在知识库中执行。大多数工作通过各种中间表示的桥梁来解决这个问题,包括组合分类语法,同步上下文无关语法,依赖树,字符串内核,树传感器。这些工作在QA中很有效,虽然需要手标的逻辑注释。
- 从IE的视角解决问答知识库的问题:我们直接学习QA对的模式,由问题的依赖性解析和答案候选者的Freebase结构表示,而不使用中间的通用意义表示。
- 数据的挑战可以视为文本或 (文本) 模式匹配:两个本体/数据库的匹配结构或(在扩展中)KB关系和NL文本之间的映射。
- 问答知识库面临两个重大挑战:模型和数据。
- 图特征:
- 依赖解析
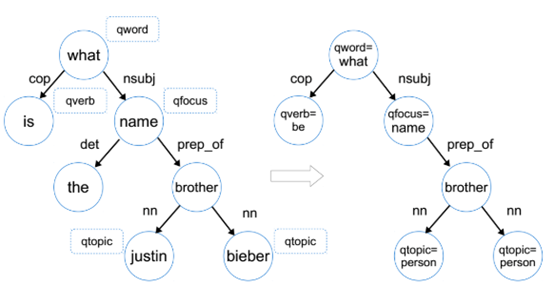
- 首先是问题词 (question word, qword),比如what、who、how等等,作者举例了常用的9个问题词;然后是问题焦点(question foucs,qfocus),期待的答案类型,比如name、money、time等,作者 在这里并没有训练分类器,而只是简单地提取依赖于qword的名词作为qfocus;然后是问题动词(question verb,qverb),比如is、play、take等,从问题的主要动词中提取,问题动词也可以暗示答案的类型,比如play动词,后面可能接instrument、movie、team等。最后是问题的主题(question topic,qtopic),问题的主题有助于我们找到相关的Freebase页面,可以简单的实现一个命名实体识别器发现问题的主题。注意问题可能不止一个主题。
- 依赖解析
-
- 问题图
- 如果一个节点标记有问题特征,那么就用问题特征代替该节点,比如what→qword=what
- 如果一个qtopic节点标记为命名实体,那么就用该节点的命名实体形式代替,比如bieber→qtopic=person
- 丢掉任何是限定词、介词或标点符号的叶节点
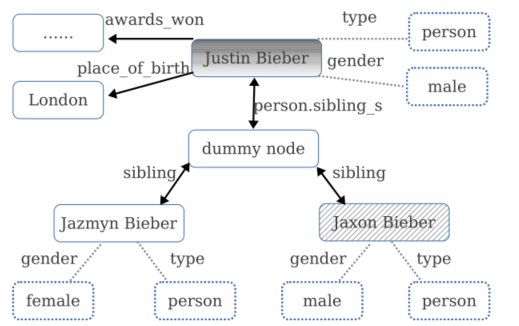
- 关系和属性的一个主要区别就是关系的参数都是节点,而属性的参数一个是节点,一个是字符串,比如place_of_birth是Justin bieber和London的关系Justin bieber的属性gender是male。
- 问题图
- 关系映射
- 我们要建立一张表描述Freebase知识库关系与自然语言单词之间的映射,目标是发现问题的最可能关系。给定一个问题Q的词向量w,我们要找到关系R,使得概率P(R | Q)最大。由于数据源的噪声和不完整性,我们用 P~ 代替真实概率 P。为了方便计算,假设单词之间条件独立,采用朴素贝叶斯得到:
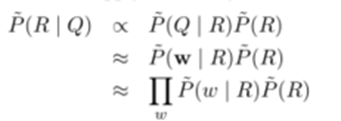
一个关系可能是由一系列的子关系组成,比如people.person.parents的子关系为people、person、
parents。假设子关系之间条件独立:

-
- 特征提取
- 问题特征:在问题特征图中的每一条边 e(s, t),提取s,t,s | t,s | e | t 作为特征。比如,边prep_of(qfocus=name, brother),提取以下特征:qfocus=name,brother, qfocus=name|brother,qfocus=name|prep_of|brother。
- 候选答案特征:一个节点的关系和属性对区分答案是很重要的。对于一个问题对应的主题图,我们提取每个节点的所有关系和属性作为特征。我们将问题的一个特征和候选答案的一个特征组合在一起,这样可以捕捉问题模式和答案节点之间的关系。比如问题-答案组合特征:qfocus=money | node_type=currency。
- 特征提取
-
- 模型训练
- 我们将在Freebase的问答视为二分类任务,对主题图的每一个节点,我们提取特征并判断是否为答案节点。每个问题都由Stanford CoreNLP套件和无壳模型处理。然后对每一个节点,组合(combine)问题特征和节点特征。对于训练集的3000个问题,有3百万个节点(每一个主题图1000个节点),7百万个特征类型。在不同模型上训练,发现L1正则化的逻辑回归表现最好。
- 模型训练
-
- 实验
- 首先对于给定的问题,我们需要定位该问题正确的主题节点。通过Freebase Search API对全部命名实体排WEBQUESTIONS不仅有标注答案,并且知道答案来自哪一个主题节点。因此,我们 可以利用训练集评估Freebase Search API的检索排名。
- 实验
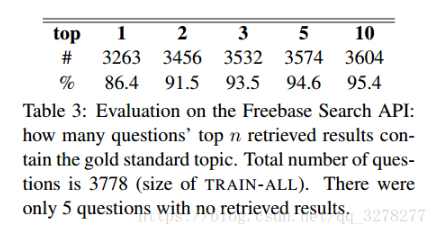
主题词一旦确定,通过查询Freebase Topic API就可以检索到主题图。然后就是特征提取过
程和模型训练了。
-
- 总结
- 作者提出了一种从结构化数据源(Freebase)中自动提问的方法。 将问题特征与Freebase描述的答案模式相关联,并在平衡和现实的QA语料库上实现了最先进的结果。整个流程是先将问题解析依 赖解析得到问题图,然后命名实体识别提取主题,在FreeBase知识库中查询主题图,提取问题-候选答案组合特征,训练分类器。由此可见,如果主题在知识库中是不存在的,那么问题是解决不了的。同时一些推理性的问题也是无法解决的,比如小明比小红高多少。
- 总结

