李宏毅 Keras手写数字集识别(优化篇)
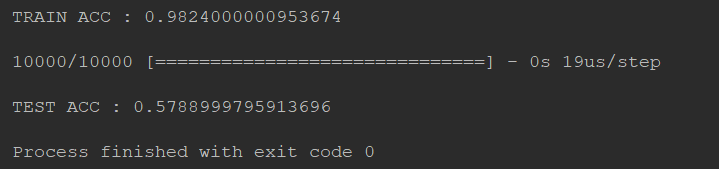
在之前的一章中我们讲到的keras手写数字集的识别中,所使用的loss function为‘mse’,即均方差。那我们如何才能知道所得出的结果是不是overfitting?我们通过运行结果中的training和testing即可得知。
源代码与运行截图如下:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm
import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255 #归一化到0-1区间 变为只有0 1的矩阵
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test)=load_data()
model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#
#model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20)
#测试结果 并打印accuary
result= model.evaluate(x_train,y_train,batch_size=10000)
print('\nTRAIN ACC :',result[1])
result= model.evaluate(x_test,y_test,batch_size=10000)
# print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1])
print('\nTEST ACC :',result[1])
运行截图:
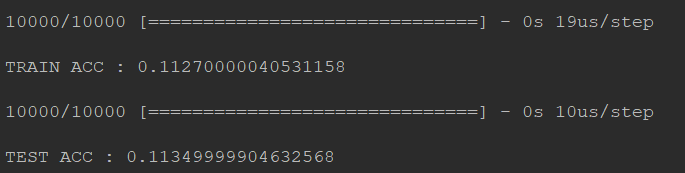
通过图片中的运行结果我们可以发现。训练结果中在training data上的准确率为0.1127,在testing data上的准确率为0.1134
虽然准确率不够高,但是这其中的train和test的准确率相差无几,所以这并不是overfitting问题。这其实就是模型的建立问题。
考虑更换loss function。原loss function 为 mse 更换为'categorical_crossentropy'然后观察训练结果。
源代码(只修改了loss):
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm
import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255 #归一化到0-1区间 变为只有0 1的矩阵
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test)=load_data()
model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
#model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#
model.compile(loss='categorical_crossentropy',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20)
#测试结果 并打印accuary
result= model.evaluate(x_train,y_train,batch_size=10000)
print('\nTRAIN ACC :',result[1])
result= model.evaluate(x_test,y_test,batch_size=10000)
# print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1])
print('\nTEST ACC :',result[1])
运行截图:

deep layer
考虑使hidden layer更深一些
for _ in range(10):
model.add(Dense(units=689,activation='sigmoid'))
结果不是很理想呢.....
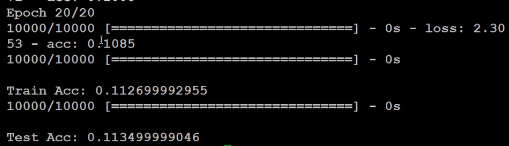
normalize
现在的图片是有进行normalize,每个pixel我们用一个0-1之间的值进行表示,那么我们不进行normalize,把255拿掉会怎样呢?
#注释掉
# x_train=x_train/255
# x_test=x_test/255
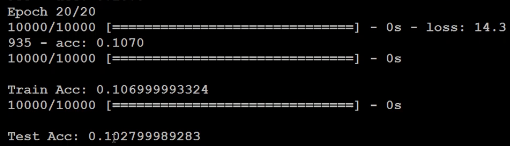
你会发现你又做不起来了,所以这种小小的地方,只是有没有做normalizion,其实对你的结果会有关键性影响。
optimizer
修改优化器optimizer,将SGD修改为Adam,然后再去跑一次,你会发现,用adam的时候最后不收敛的地方查不到,但是上升的速度变快。
源代码不贴了,就是修改了optimizer
model.compile(loss='categorical_crossentropy',optimizer='adam',metrics=['accuracy'])
你会惊奇的发现!wow!train accuracy居然达到100%!而且test accuracy也表现的不错~
运行截图:
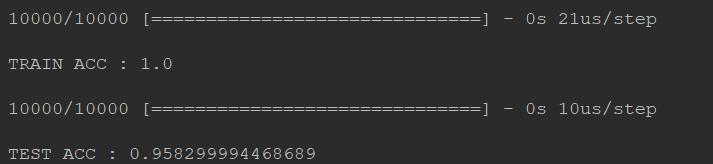
Random noise
添加噪声数据,看看结果会掉多少?完整代码不贴了QAQ
x_test = np.random.normal(x_test)
可以看出train的结果是ok的 但是test不太行,出现了overfitting!
运行截图:
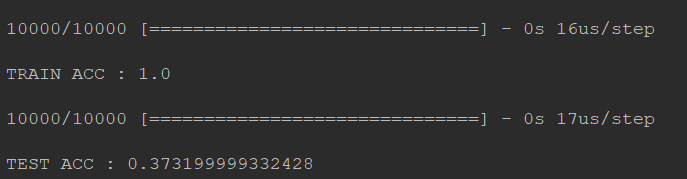
dropout
#dropout 就是在每一个隐藏层后面都dropout一下 model.add(Dense(input_dim=28*28,units=689,activation='relu')) model.add(Dropout(0.7)) model.add(Dense(units=689,activation='relu')) model.add(Dropout(0.7)) model.add(Dense(units=689,activation='relu')) model.add(Dropout(0.7)) model.add(Dense(units=10,activation='softmax'))
要知道dropout加入之后,train的效果会变差,然而test的正确率提升了