
李宏毅 Keras2.0演示
李宏毅 Keras2.0演示
不得不说李宏毅老师讲课的风格我真的十分喜欢的。
在keras2.0中,李宏毅老师演示的是手写数字识别(这个深度学习框架中的hello world)
创建网络
首先我们需要建立一个Network scratch,input是28*25的dimension,其实就是说这是一张image,image的解析度是28∗28,我们把它拉成长度是28∗28维的向量。output呢?
现在做的是手写数字辨识,所以要决定它是0-9的哪个数字,output就是每一维对应的数字,所以output就是10维。
中间假设你要两个layer,每个layer有500个hidden neuro,那么你会怎么做呢。
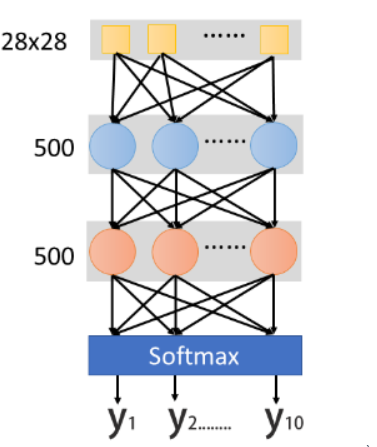
如果用Keras的话,首先需要声明一个network
model=Sequential()
然后你需要吧第一个hidden layer加进去,需要怎么做呢?很简单,只需要add即可。
model.add(Dense(input_dim=28*28,units=500,activation='relu'))
Dense意思就是说你加一个全连接网络,可以加其他的,比如加Con2d,就是加一个convolution layer,这些都很简单。input_dim是说输入的维度是多少,units表示hidden layer的neuro 数,
activation就是激活函数,每个activation是一个简单的英文缩写,比如relu,softplus,softsign,sigmoid,tanh,hard_sigmoid,linear 再加第二个layer,就不需再宣告input_dim,因为它的输入就是
上一层的units,所以不需要再定义一次,在这,只需要声明units和activation
model.add(Dense(units=500,activation='relu'))
配置
第二过程你要做一下configuration,你要定义loss function,选一个optimizer,以及评估指标metrics,其实所有的optimizer都是Gradent descent based,只是有不同的方法来决定
learning rate,比如Adam,SGD,RMSprop,Adagrad,Adalta,Adamax ,Nadam等,设完configuration之后你就可以开始train你的Network
model.compile(loss='categorical crossentropy',optimizer='adam',metrics=['accuracy'])
选择最好的方程
model.fit(x_train,y_train,batch_size=100,epochs=20)
call model.fit 方法,它就开始用Gradent Descent帮你去train你的Network,那么你要给它你的train_data input 和label,这里x_train代表image,y_train代表image的label,关于x_train和y_train的格式,你都要存成numpy array。
那么x_train怎样表示呢?第一个轴表示example,第二个轴代表每个example用多长vecter来表示它。x_train就是一个matrix。y_train也存成一个二维matrix,第一个维度一样代表training examples,
第二维度代表着现在有多少不同的case,只有一维是1,其他的都是0,每一维都对应一个数字,比如第0维对应数字0,如果第N维是1,对应的数字就是N。

使用模型
1.存储和载入模型Save and load models参考kers的说明
2.模型的使用:接下来就要拿这个Network进行使用,使用有两个不通的情景,这两个不同的情景一个是evalution,即为model在test data上表现的怎么样,call evaluate这个函数,然后把x_test,y_test喂给它,就会自动给你计算出Accuracy。它会output一个二维的向量,第一个维度代表了在test set上loss,第二个维度代表了在test set上的accuracy,这两个值是不一样的。loss可能用cross_entropy,Accuraccy是对与不对,即正确率。
case 1
score = model.evaluate(x_test,y_test)
print('Total loss on Testiong Set : ',score[0])
print('Accuracy of Testiong Set : ',score[1])
case 2
第二种是做predict,就是系统上线后,没有正确答案的,call predict进行预测
result = model.predict(x_test)
其他
Sequential序贯模型
是函数式模型的简略版,为最简单的线性、从头到尾的结构顺序,不分叉,是多个网络层的线性堆叠。
Keras实现了很多层,包括core核心层,Convolution卷积层、Pooling池化层等非常丰富有趣的网络结构。
我们可以通过将层的列表传递给Sequential的构造函数,来创建一个Sequential模型。
1 from keras.models import Sequential
2 from keras.layers import Dense, Activation
3
4 model = Sequential([
5 Dense(32, input_shape=(784,)),
6 Activation('relu'),
7 Dense(10),
8 Activation('softmax'),
9 ])
也可以使用.add()方法将各层添加到模型中:
1 model = Sequential()
2 model.add(Dense(32, input_dim=784))
3 model.add(Activation('relu'))
输入数据的尺寸:
模型需要知道它所期待的输入的尺寸(shape)。出于这个原因,序贯模型中的第一层(只有第一层,因为下面的层可以自动的推断尺寸)需要接收关于其输入尺寸的信息,后面的各个层则可以自动的推导出中间数据的shape,因此不需要为每个层都指定这个参数。
- 某些2D层,例如Dense,支持通过参数input_dim指定输入尺寸,某些3D时序层支持input_dim和input_length参数。
- 传递一个input_shape参数给第一层,他是表示尺寸的元组(一个整数orNone的元组,其中None表示可能为任何整数)。在input_shape中不包含数据的batch大小。
model = Sequential()
model.add(Dense(32, input_shape=(784,)))
#等价
model = Sequential()
model.add(Dense(32, input_dim=784))
编译
在训练模型之前,我们需要配置学习过程,这是通过compile方法完成的,他接收三个参数:
- 优化器optimizer:它可以是现有优化器的字符串标识符,如rmsprop或adagrad,也可以是Optimizer类的实例。详见:optimizers
- 损失函数loss:模型视图最小化的目标函数。他可以是现有损失函数的标识符,如categorical_crossentropy或者mse,也可以是一个目标函数。
- 评估标准metrics:对于任何分类问题,你都希望将其设置为metrics=['accuracy']。评估标准可以是现有的标准的字符串标识符,也可以是自定义的评估标准函数。
# 多分类问题
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 二分类问题
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 均方误差回归问题
model.compile(optimizer='rmsprop',
loss='mse')
# 自定义评估标准函数
import keras.backend as K
def mean_pred(y_true, y_pred):
return K.mean(y_pred)
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy', mean_pred])
训练
keras模型在输入数据和标签的Numpy矩阵上进行训练。为了训练一个模型,通常使用fit函数
# 对于具有2个类的单输入模型(二进制分类):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(1, activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(2, size=(1000, 1))
# 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, labels, epochs=10, batch_size=32)
# 对于具有10个类的单输入模型(多分类分类):
model = Sequential()
model.add(Dense(32, activation='relu', input_dim=100))
model.add(Dense(10, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 生成虚拟数据
import numpy as np
data = np.random.random((1000, 100))
labels = np.random.randint(10, size=(1000, 1))
# 将标签转换为分类的 one-hot 编码
one_hot_labels = keras.utils.to_categorical(labels, num_classes=10)
# 训练模型,以 32 个样本为一个 batch 进行迭代
model.fit(data, one_hot_labels, epochs=10, batch_size=32)
源代码:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2019/9/9 13:23
# @Author : BaoBao
# @Mail : baobaotql@163.com
# @File : test5.py
# @Software: PyCharm
import numpy as np
from keras.models import Sequential #序贯模型
from keras.layers.core import Dense,Dropout,Activation
from keras.optimizers import SGD,Adam
from keras.utils import np_utils
from keras.datasets import mnist
def load_data():
(x_train,y_train),(x_test,y_test)=mnist.load_data() #载入数据
number=10000
x_train=x_train[0:number]
y_train=y_train[0:number]
x_train=x_train.reshape(number,28*28)
x_test=x_test.reshape(x_test.shape[0],28*28)
x_train=x_train.astype('float32') #astype转换数据类型
x_test=x_test.astype('float32')
y_train=np_utils.to_categorical(y_train,10)
y_test=np_utils.to_categorical(y_test,10)
x_train=x_train
x_test=x_test
x_train=x_train/255
x_test=x_test/255
return (x_train,y_train),(x_test,y_test)
(x_train,y_train),(x_test,y_test)=load_data()
model=Sequential()
model.add(Dense(input_dim=28*28,units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=689,activation='sigmoid'))
model.add(Dense(units=10,activation='softmax'))
model.compile(loss='mse',optimizer=SGD(lr=0.1),metrics=['accuracy'])
#train 模型
model.fit(x_train,y_train,batch_size=100,epochs=20)
#测试结果 并打印accuary
result= model.evaluate(x_test,y_test)
# print('\nTest loss:', result[0])
# print('\nAccuracy:', result[1])
print('TEST ACC :',result[1])


