
调用百度API进行文本纠错
毕设做的是文本纠错方面,然后今天进组见研究生导师 。老师对我做的东西蛮感兴趣。然后介绍自己现在做的一些项目,其中有个模块需要有用到文本纠错功能。
要求1:有多人同时在线编辑文档,然后文档功能有类似Word中的在疑似错误下标浪线,或者标记高亮,并且要推荐修改选项
要求2:语料数据的获取、处理以及完善
要求3:文章写完后要有生成keyword
根据老师所讲要查阅文献,以及已有项目来分析可行性,首先想到之前曾有同学调用百度API来进行文档的纠错,然后在这里试了一下。
API描述
识别输入文本中有错误的片段,提示错误并给出正确的文本结果。支持短文本、长文本、语音等内容的错误识别,纠错是搜索引擎、语音识别、内容审查等功能更好运行的基础模块之一。
Step 1 获取assess_token
根据百度开发手册 ,我们需要进行获取assess_token(用户身份验证和授权的凭证)
详细请见百度开发手册
因为百度所给的实例中是python2 然后我用的是python3 会有一些变化 这里只贴python3代码供自己回忆参考
import urllib.request import urllib,sys import ssl # client_id 为官网获取的AK, client_secret 为官网获取的SK host = 'https://aip.baidubce.com/oauth/2.0/token?' \ 'grant_type=client_credentials&client_id=**********&client_secret=**************' request = urllib.request.Request(host) request.add_header('Content-Type', 'application/json; charset=UTF-8') response = urllib.request.urlopen(request) content = response.read() if (content): print(content)
执行代码后 可在控制台中看到所要的token_key
另附实例
# -*- coding: utf-8 -*- import urllib import json #client_id 为官网获取的AK, client_secret 为官网获取的SK client_id =【百度云应用的AK】 client_secret =【百度云应用的SK】 #获取token def get_token(): host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret request = urllib.request.Request(host) request.add_header('Content-Type', 'application/json; charset=UTF-8') response = urllib.request.urlopen(request) token_content = response.read() if token_content: token_info = json.loads(token_content) token_key = token_info['access_token'] return token_key
Step 2 文本纠错应用部分
POST方式调用
注意:要求使用JSON格式的结构体来描述一个请求的具体内容。
body整体文本内容可以支持GBK和UTF-8两种格式的编码。
URL参数:参数 值
access_token 通过API Key和Secret Key获取的access_token,参考“Access Token获取”
Header如下:参数 值
Content-Type application/json
返回说明
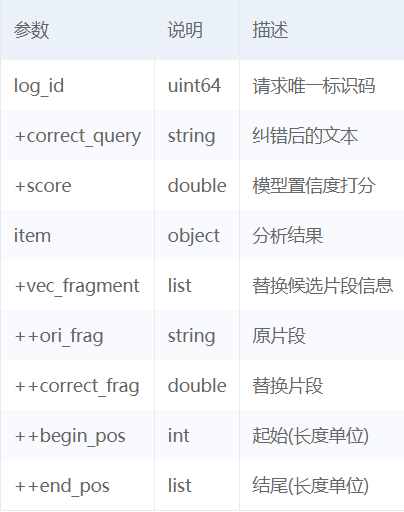
# -*- coding: utf-8 -*- #!/usr/bin/env python import urllib import json #Access Token的有效期为30天(以秒为单位),请您集成时注意在程序中定期请求新的token #client_id 为官网获取的AK, client_secret 为官网获取的SK client_id ='***********' client_secret ='*************' #获取token def get_token(): host = 'https://aip.baidubce.com/oauth/2.0/token?grant_type=client_credentials&client_id=' + client_id + '&client_secret=' + client_secret request = urllib.request.Request(host) request.add_header('Content-Type', 'application/json; charset=UTF-8') response = urllib.request.urlopen(request) token_content = response.read() if token_content: token_info = json.loads(token_content) token_key = token_info['access_token'] return token_key def txt_correction(content): print('原文:', content) token = get_token() url = 'https://aip.baidubce.com/rpc/2.0/nlp/v1/ecnet' params = dict() params['text'] = content params = json.dumps(params).encode('utf-8') access_token = token url = url + "?access_token=" + access_token request = urllib.request.Request(url=url, data=params) request.add_header('Content-Type', 'application/json') response = urllib.request.urlopen(request) content = response.read() if content: content = content.decode('GB2312') data = json.loads(content) item = data['item'] print('纠错后:', item['correct_query']) print('Score:', item['score']) txt_correction('汽车形式在这条道路上')
运行结果如下:
>> 原文:汽车形式在这条道路上 >> 纠错后:汽车行驶在这条公路上 >> Score:0.982835

