贪婪技术之 huffman编码树
不同于对字符使用定长编码,huffman编码法使用“频繁出现的字符占用更短的位数,不频繁出现的字符占用更长的位数”的方法,来实现编码压缩。
首先对于text中的所有字符,我们统计每个字符出现的频率,例如:

huffman算法描述:
第一步,初始化n个单节点的树(森林),为它们标上字母表中的字符,并把每个字符的频率都记在树的根中,用来指出树的权重。
第二步,重复以下步骤,当森林中只剩下一颗树时,算法结束。找到两棵权重最小的树,把它们作为左右子树,构建一棵新的树,然后新的树的权重为两棵子树权重之和。
画图表示:



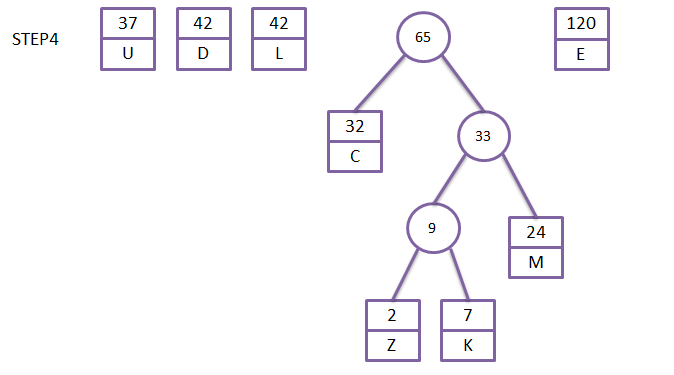

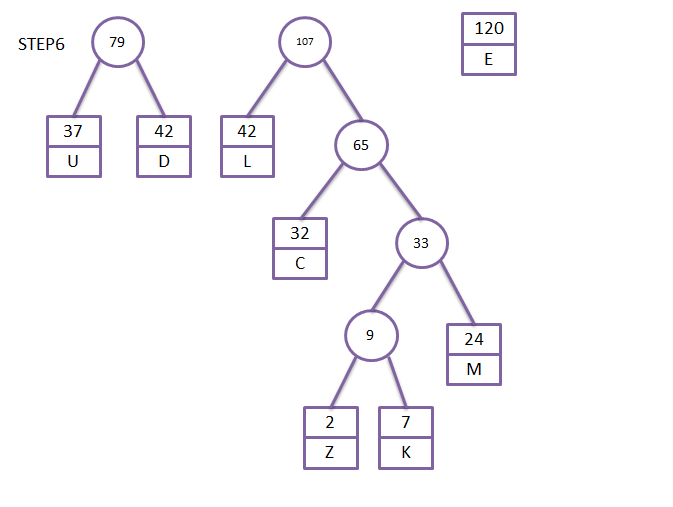


至此,我们就构造出了一颗二叉huffman树。现在我们让每个节点的左边子树为0,右边子树为1,则当一个字符在某一个叶子时,huffman树根到该叶子的路径所构成的编码,就是该字符的huffman编码。

例子中每个字符对应的编码为

明显,在huffman编码下,每个字符的编码都不可能是另一个字符的编码的前缀。因此,只要保存了huffman编码树,就能保证在变长编码下,能顺利解码。从而,huffman编码能有效实现文本信息的压缩。
因为huffman编码树建树的过程,选择的都是最小的频率的两个字符,因此huffman编码方法是一种使编码长度最短的方法。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号