【YOLOv8改进 - 注意力机制】NAM:基于归一化的注意力模块,将权重稀疏惩罚应用于注意力机制中,提高效率性能
YOLO目标检测创新改进与实战案例专栏
专栏目录: YOLO有效改进系列及项目实战目录 包含卷积,主干 注意力,检测头等创新机制 以及 各种目标检测分割项目实战案例
专栏链接: YOLO基础解析+创新改进+实战案例
摘要
识别较不显著的特征是模型压缩的关键。然而,这在革命性的注意力机制中尚未被研究。在这项工作中,我们提出了一种新颖的基于归一化的注意力模块(NAM),该模块抑制了较不显著的权重。它对注意力模块施加了权重稀疏惩罚,从而使其在保留相似性能的同时变得更具计算效率。在Resnet和Mobilenet上与其他三种注意力机制的比较表明,我们的方法可以带来更高的准确性。本文的代码可以在https://github.com/Christian-lyc/NAM公开获取。
文章链接
论文地址:论文地址
代码地址:代码地址
基本原理
NAM (Normalization-based Attention Module)是一种新颖的注意力机制,旨在通过抑制不太显著的特征来提高模型的效率。NAM模块将权重稀疏惩罚应用于注意力机制中,以提高计算效率同时保持性能。NAM模块通过批量归一化(Batch Normalization)的缩放因子来衡量通道的重要性,避免了SE(Squeeze-and-Excitation)、BAM(Bottleneck Attention Module)和CBAM(Convolutional Block Attention Module)中使用的全连接和卷积层。这使得NAM成为一种高效的注意力机制。
NAM模块结合了通道注意力和空间注意力的子模块,利用批量归一化的缩放因子来衡量通道和像素的重要性,从而实现对特征的有效识别和利用。
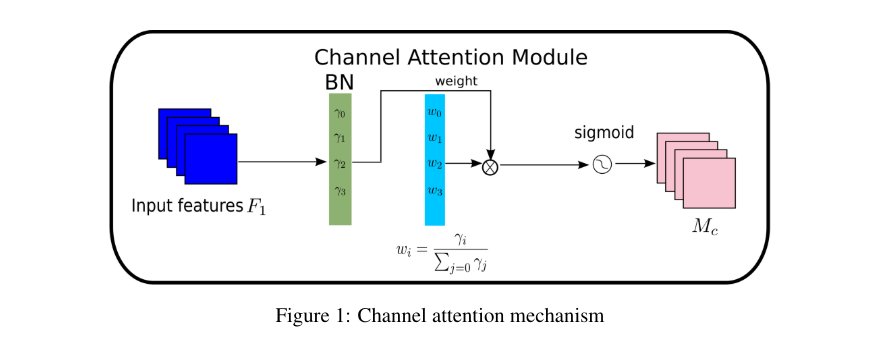
- 通道注意力子模块:使用批量归一化的缩放因子来衡量通道的重要性,通过计算权重来获得输出特征。
-
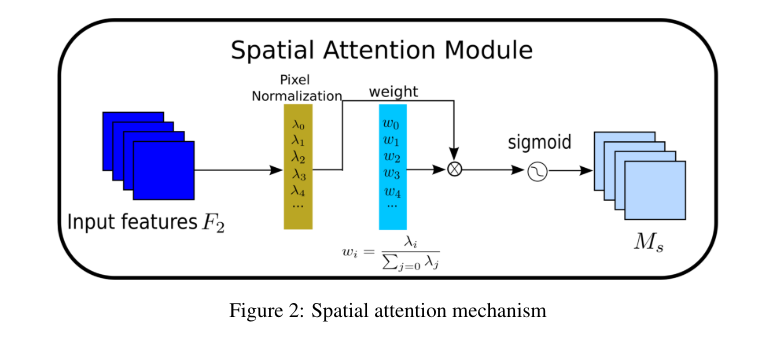
空间注意力子模块:应用像素归一化来衡量像素的重要性,得到输出特征。
-
权重稀疏惩罚:NAM模块通过添加正则化项到损失函数中,以抑制不太显著的权重,从而提高模型的泛化能力和效率。
数学公式:
NAM模块的损失函数如下所示:
$$
Loss = ∑(x,y) l(f(x, W), y) + p ∑ g(γ) + p ∑ g(λ)
$$
其中:
- x:输入
- y:输出
- W:网络权重
- l(·):损失函数
- g(·):l1范数惩罚函数
- p:平衡g(γ)和g(λ)的惩罚参数
通道注意力子模块的输出特征:
$$
M_c = sigmoid(W_γ(BN(F_1)))
$$
空间注意力子模块的输出特征(Equation 3):
$$
M_s = sigmoid(W_λ(BN_s(F_2)))
$$
其中:
- M_c:通道注意力子模块的输出特征
- M_s:空间注意力子模块的输出特征
- W_γ:通道注意力子模块的权重
- W_λ:空间注意力子模块的权重
- BN:批量归一化
- F_1、F_2:输入特征
核心代码
import torch.nn as nn
import torch
from torch.nn import functional as F
# 定义通道注意力模块
class Channel_Att(nn.Module):
def __init__(self, channels, t=16):
super(Channel_Att, self).__init__()
self.channels = channels # 输入的通道数
# 定义批量归一化层
self.bn2 = nn.BatchNorm2d(self.channels, affine=True)
def forward(self, x):
residual = x # 保存输入特征图以便后续相乘
x = self.bn2(x) # 对输入特征图进行批量归一化处理
# 获取批量归一化层的权重,并进行绝对值处理和归一化
weight_bn = self.bn2.weight.data.abs() / torch.sum(self.bn2.weight.data.abs())
# 调整特征图的维度顺序,从[N, C, H, W]变为[N, H, W, C]
x = x.permute(0, 2, 3, 1).contiguous()
# 将归一化后的权重与调整维度后的特征图相乘
x = torch.mul(weight_bn, x)
# 再将特征图的维度顺序调整回[N, C, H, W]
x = x.permute(0, 3, 1, 2).contiguous()
# 对特征图进行Sigmoid激活,并与残差相乘
x = torch.sigmoid(x) * residual
return x # 返回处理后的特征图
# 定义注意力模块
class Att(nn.Module):
def __init__(self, channels, shape, out_channels=None, no_spatial=True):
super(Att, self).__init__()
# 实例化通道注意力模块
self.Channel_Att = Channel_Att(channels)
def forward(self, x):
# 将输入特征图通过通道注意力模块
x_out1 = self.Channel_Att(x)
return x_out1 # 返回通道注意力处理后的特征图
task与yaml配置
详见:https://blog.csdn.net/shangyanaf/article/details/140083725

 浙公网安备 33010602011771号
浙公网安备 33010602011771号