
多路平衡归并排序(胜者树、败者树)
经过计算得知,如果毫无限度地增加 k 值,虽然会减少读写外存数据的次数,但会增加内部归并的时间,得不偿失
1、例如,对于 10 个临时文件,当采用 2-路平衡归并时,若每次从 2 个文件中想得到一个最小值时只需比较 1 次;而采用 5-路平衡归并时,若每次从 5 个文件中想得到一个最小值就需要比较 4 次。以上仅仅是得到一个最小值记录,如要得到整个临时文件,其耗费的时间就会相差很大
2、为了避免在增加 k 值的过程中影响内部归并的效率,在进行 k-路归并时可以使用“败者树”来实现,该方法在增加 k 值时不会影响其内部归并的效率
败者树实现内部归并
1、败者树是树形选择排序的一种变形,本身是一棵完全二叉树
2、在树形选择排序一节中,对于无序表 {49,38,65,97,76,13,27,49} 创建的完全二叉树如下图所示,构建此树的目的是选出无序表中的最小值
(1)这棵树与败者树正好相反,是一棵“胜者树”
(2)因为树中每个非终端结点(除叶子结点之外的其它结点)中的值都表示的是左右孩子相比较后的较小值(谁最小即为胜者)
(3)例如叶子结点 49 和 38 相对比,由于 38 更小,所以其双亲结点中的值保留的是胜者 38。然后用 38 去继续同上层去比较,一直比较到树的根结点
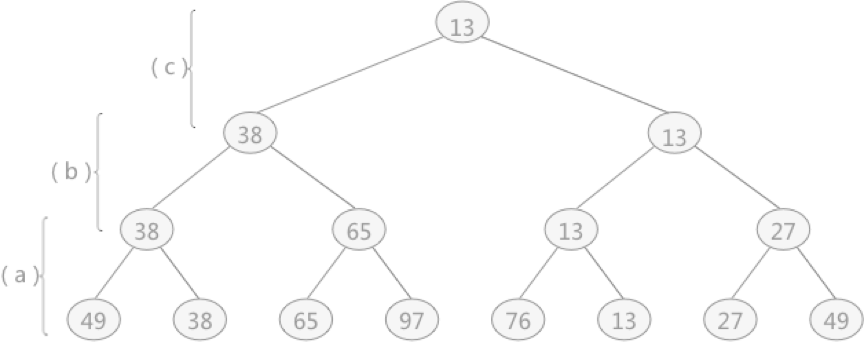
3、败者树恰好相反,其双亲结点存储的是左右孩子比较之后的失败者,而胜利者则继续同其它的胜者去比较
(1)叶子结点 49 和 38 比较,38 更小,所以 38 是胜利者,49 为失败者,但由于是败者树,所以其双亲结点存储的应该是 49
(2)同样,叶子结点 65 和 97 比较,其双亲结点中存储的是 97,而 65 则用来同 38 进行比较,65 会存储到 97 和 49 的双亲结点的位置,38 继续做后续的胜者比较,依次类推
4、胜者树和败者树的区别就是:胜者树中的非终端结点中存储的是胜利的一方;而败者树中的非终端结点存储的是失败的一方。而在比较过程中,都是拿胜者去比较
5、如下图所示为一棵 5-路归并的败者树(从小到大排序)
(1)其中 b0 - b4 为树的叶子结点,分别为 5 个归并段中存储的记录的关键字
(2)ls 为一维数组,表示的是非终端结点,其中存储的数值表示第几归并段(例如 b0 为第 0 个归并段)。ls[0] 中存储的为最终的胜者,表示当前第 3 归并段中的关键字最小
(3)当最终胜者判断完成后,只需要更新叶子结点 b3 的值,即导入关键字 15,然后让该结点不断同其双亲结点所表示的关键字进行比较,败者留在双亲结点中,胜者继续向上比较
(4)例如,叶子结点 15 先同其双亲结点 ls[4] 中表示的 b4 中的 12 进行比较,12 为胜利者,则 ls[4] 改为 15,然后 12 继续同 ls[2] 中表示的 10 做比较,10 为胜者,然后 10 继续同其双亲结点 ls[1] 表示的 b1(关键字 9)作比较,最终 9 为胜者。整个过程如下图所示

(5)注意:为了防止在归并过程中某个归并段变为空,处理的办法为:可以在每个归并段最后附加一个关键字为最大值的记录。这样当某一时刻选出的冠军为最大值时,表明 5 个归并段已全部归并完成。(因为只要还有记录,最终的胜者就不可能是附加的最大值)


【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战