
Sentinel
概述
1、Sentinel 以流量为切入点,从流量控制、流量路由、熔断降级、系统自适应过载保护、热点流量防护等多个维度保护服务的稳定性
2、特征
(1)丰富的应用场景:秒杀(即突发流量控制在系统容量可以承受的范围)、消息削峰填谷、集群流量控制、实时熔断下游不可用应用等
(2)完备的实时监控:Sentinel 同时提供实时的监控功能,可以在控制台中看到接入应用的单台机器秒级数据,甚至 500 台以下规模的集群的汇总运行情况
(3)广泛的开源生态:Sentinel 提供开箱即用的与其它开源框架 / 库的整合模块,例如:与 Spring Cloud、Apache Dubbo、gRPC、Quarkus 的整合,只需要引入相应的依赖并进行简单的配置即可快速地接入 Sentinel,同时 Sentinel 提供 Java / Go / C++ 等多语言的原生实现
(4)完善的 SPI 扩展机制:Sentinel 提供简单易用、完善的 SPI 扩展接口,可以通过实现扩展接口来快速地定制逻辑,例如:定制规则管理、适配动态数据源等
3、特性

4、Sentinel 分为两个部分
(1)核心库(Java 客户端)不依赖任何框架 / 库,能够运行于所有 Java 运行时环境,同时对 Dubbo / Spring Cloud 等框架也有较好的支持
(2)控制台(Dashboard)基于 Spring Boot 开发,打包后可以直接运行,不需要额外的 Tomcat 等应用容器
启动控制台
1、获取 Sentinel 控制台:从 release 页面 下载最新版本的控制台 jar 包
2、启动
(1)注意:启动 Sentinel 控制台需要 JDK 版本为 1.8 及以上版本
(2)使用如下命令启动控制台
java -Dserver.port=8080 -Dcsp.sentinel.dashboard.server=localhost:8080 -Dproject.name=sentinel-dashboard -jar sentinel-dashboard.jar(3)其中 -Dserver.port=8080 用于指定 Sentinel 控制台端口为 8080
(4)从 Sentinel 1.6.0 起,Sentinel 控制台引入基本的登录功能,默认用户名和密码都是 sentinel
3、用户可以通过如下参数进行配置
(1)-Dsentinel.dashboard.auth.username=sentinel:用于指定控制台的登录用户名为 sentinel
(2)-Dsentinel.dashboard.auth.password=123456:用于指定控制台的登录密码为 123456;如果省略这两个参数,默认用户和密码均为 sentinel
(3)-Dserver.servlet.session.timeout=7200:用于指定 Spring Boot 服务端 session 的过期时间,如 7200 表示 7200 秒;60m 表示 60 分钟,默认为 30 分钟
(4)同样也可以直接在 Spring properties 文件中进行配置
4、客户端接入控制台
(1)Spring Cloud 依赖
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-sentinel</artifactId>
</dependency>(2)yaml 配置控制台信息
spring:
cloud:
sentinel:
transport:
#spring.cloud.sentinel.transport.port 端口配置会在应用对应的机器上启动一个 Http Server
#该 Server 会与 Sentinel 控制台做交互
#如:Sentinel 控制台添加了1个限流规则,会把规则数据 push 给这个 Http Server 接收,Http Server 再将规则注册到 Sentinel 中
#默认8719端口,假如被占用会自动从8719开始,依次+1扫描,直至找到未被占用的端口
port: 8719
#配置Sentinel dashboard地址
dashboard: localhost:8080
流量控制规则(FlowRule)
1、资源名:唯一名称,默认请求路径
2、针对来源:Sentinel 可以针对调用者进行限流,填写微服务名,默认 default(不区分来源)
3、阔值类型、单机阀值
(1)QPS(每秒钟的请求数量):当调用该 API 的 QPS 达到单机阀值时,进行限流
(2)线程数:当调用该 API 的线程数达到单机阀值时,进行限流
4、是否集群
5、流控模式:
(1)直接:统计当前资源的请求,触发阈值时,对当前资源直接限流(默认)
(2)关联:统计与当前资源相关的另一个资源,触发阀值时,对当前资源限流
(3)链路:统计从指定链路访问到本资源的请求,触发阈值时,对指定链路限流
6、流控效果
(1)快速失败:当 QPS 超过任意规则的阈值后,新的请求就会被立即拒绝,抛出 FlowException
(2)Warm Up:根据 codeFactor(冷加载因子,默认为 3)的值,系统初始化的默认阈值 = 设置阈值 / codeFactor,经过预热时长后,才达到设置的 QPS 阀值
(3)排队等待:匀速排队,让请求以匀速通过,阈值类型必须设置为 QPS,否则无效
7、同一个资源可以对应多条限流规则。FlowSlot 会对该资源的所有限流规则依次遍历,直到有规则触发限流或者所有规则遍历完毕
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,资源名是限流规则的作用对象 | |
| count | 限流阈值 | |
| grade | 限流阈值类型,QPS 或线程数模式 | QPS 模式 |
| limitApp | 流控针对的调用来源 | default,代表不区分调用来源 |
| strategy | 调用关系限流策略:直接、链路、关联 | 根据资源本身(直接) |
| controlBehavior | 流控效果(直接拒绝 / 排队等待 / 慢启动模式),不支持按调用关系限流 | 直接拒绝 |
并发线程数流量控制
1、线程数限流用于保护业务线程数不被耗尽
2、例如:当应用所依赖的下游应用由于某种原因导致服务不稳定、响应延迟增加,对于调用者来说,意味着吞吐量下降和更多的线程数占用,极端情况下甚至导致线程池耗尽
3、为应对高线程占用的情况,业内有使用隔离的方案
(1)通过不同业务逻辑使用不同线程池来隔离业务自身之间的资源争抢(线程池隔离)
(2)使用信号量来控制同时请求的个数(信号量隔离)
(3)这种隔离方案虽然能够控制线程数量,但无法控制请求排队时间
(4)当请求过多时排队也是无益的,直接拒绝能够迅速降低系统压力
4、Sentinel 线程数限流不负责创建和管理线程池,而是简单统计当前请求上下文的线程个数,如果超出阈值,新的请求会被立即拒绝
QPS 流量控制
1、当 QPS 超过某个阈值的时候,则采取措施进行流量控制。流量控制的手段包括下面 3 种,对应 FlowRule 中的 controlBehavior 字段
2、直接拒绝(RuleConstant.CONTROL_BEHAVIOR_DEFAULT)方式
(1)该方式是默认的流量控制方式
(2)当 QPS 超过任意规则的阈值后,新的请求就会被立即拒绝,拒绝方式为抛出 FlowException
(3)这种方式适用于对系统处理能力确切已知的情况下,比如通过压测确定了系统的准确水位时
3、冷启动(RuleConstant.CONTROL_BEHAVIOR_WARM_UP)方式
(1)该方式主要用于系统长期处于低水位的情况下,当流量突然增加时,直接把系统拉升到高水位可能瞬间把系统压垮
(2)通过“冷启动”,让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限,给冷系统一个预热的时间,避免冷系统被压垮的情况
(3)通常冷启动的过程系统允许通过的 QPS 曲线如下图所示:

4、匀速器(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式
(1)这种方式严格控制了请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法
(2)该方式的作用如下图所示:
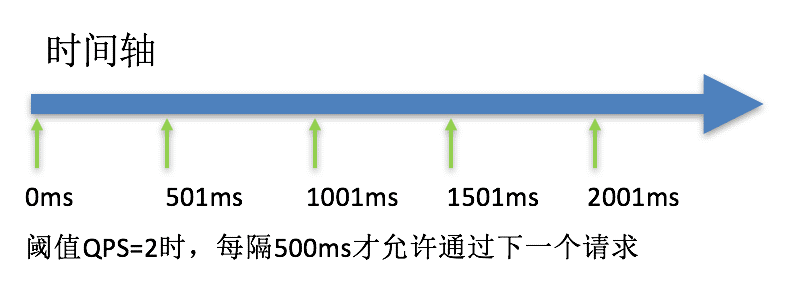
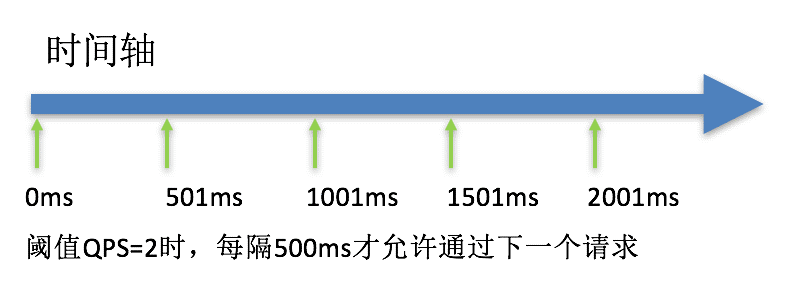
(3)这种方式主要用于处理间隔性突发的流量,例如:消息队列,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求
(4)以固定的间隔时间让请求通过。当请求到来时,如果当前请求距离上个通过的请求通过的时间间隔不小于预设值,则让当前请求通过;否则,计算当前请求的预期通过时间,如果该请求的预期通过时间小于规则预设的 timeout 时间,则该请求会等待直到预设时间到来通过(排队等待处理);若预期的通过时间超出最大排队时长,则直接拒接这个请求
(5)这种方式适合用于请求以突刺状来到,这时不希望一下子把所有的请求都通过,这样可能会把系统压垮;同时也期待系统以稳定的速度,逐步处理这些请求,以起到“削峰填谷”的效果,而不是拒绝所有请求
(6)效果如下所示

(7)Sentinel 匀速排队等待策略是 Leaky Bucket 算法结合虚拟队列等待机制实现的
(8)注意:匀速排队模式暂时不支持 QPS > 1000 的场景
基于调用关系的流量控制
1、概述
(1)调用关系包括调用方、被调用方;方法又可能会调用其它方法,形成一个调用链路的层次关系
(2)Sentinel 通过 NodeSelectorSlot 建立不同资源间的调用的关系,并且通过 ClusterNodeBuilderSlot 记录每个资源的实时统计信息
(3)有了调用链路的统计信息,可以衍生出多种流量控制手段
2、根据调用方限流
(1)ContextUtil.enter(resourceName, origin) 方法中的 origin 参数标明了调用方身份。这些信息会在 ClusterBuilderSlot 中被统计。
(2)限流规则中的 limitApp 字段用于根据调用方进行流量控制。该字段的值有以下三种选项,分别对应不同的场景
(3)default:表示不区分调用者,来自任何调用者的请求都将进行限流统计。如果这个资源名的调用总和超过了这条规则定义的阈值,则触发限流
(4){some_origin_name}:表示针对特定的调用者,只有来自这个调用者的请求才会进行流量控制。例如 NodeA 配置了一条针对调用者 caller1 的规则,那么当且仅当来自 caller1 对 NodeA 的请求才会触发流量控制
(5)other:表示针对除 {some_origin_name} 以外的其余调用方的流量进行流量控制。例如,资源 NodeA 配置了一条针对调用者 caller1 的限流规则,同时又配置了一条调用者为 other 的规则,那么任意来自非 caller1 对 NodeA 的调用,都不能超过 other 这条规则定义的阈值
(6)同一个资源名可以配置多条规则,规则的生效顺序为:{some_origin_name} > other > default
3、根据调用链路入口限流:链路限流
(1)NodeSelectorSlot 中记录了资源之间的调用链路,这些资源通过调用关系,相互之间构成一棵调用树
(2)这棵树的根节点是一个名字为 machine-root 的虚拟节点,调用链的入口都是这个虚节点的子节点
(3)一棵典型的调用树如下图所示
machine-root
/ \
/ \
Entrance1 Entrance2
/ \
/ \
DefaultNode(nodeA) DefaultNode(nodeA)(4)上图中来自入口 Entrance1 和 Entrance2 的请求都调用到了资源 NodeA,Sentinel 允许只根据某个入口的统计信息对资源限流
(5)比如:可以设置 FlowRule.strategy 为 RuleConstant.CHAIN,同时设置 FlowRule.ref_identity 为 Entrance1 来表示只有从入口 Entrance1 的调用才会记录到 NodeA 的限流统计当中,而对来自 Entrance2 的调用漠不关心
(6)调用链的入口是通过 API 方法 ContextUtil.enter(name) 定义的
4、具有关系的资源流量控制:关联流量控制
(1)当两个资源之间具有资源争抢或者依赖关系的时候,这两个资源便具有了关联
(2)比如:对数据库同一个字段的读操作和写操作存在争抢,读的速度过高会影响写得速度,写的速度过高会影响读的速度
(3)如果放任读写操作争抢资源,则争抢本身带来的开销会降低整体的吞吐量
(4)可使用关联限流来避免具有关联关系的资源之间过度的争抢
(5)举例:read_db 和 write_db 这两个资源分别代表数据库读写,可以给 read_db 设置限流规则来达到写优先的目的:设置 FlowRule.strategy 为 RuleConstant.RELATE 同时设置 FlowRule.ref_identity 为 write_db
(6)这样当写库操作过于频繁时,读数据的请求会被限流
熔断降级
1、慢调用比例(SLOW_REQUEST_RATIO)
(1)选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间,默认 4900ms),请求的响应时间大于该值则统计为慢调用
(2)当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断
(3)经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断
2、异常比例(ERROR_RATIO)
(1)当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断
(2)经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断
(3)异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%
3、异常数(ERROR_COUNT)
(1)当单位统计时长内的异常数目超过阈值之后会自动进行熔断
(2)经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断
4、注意:异常降级仅针对业务异常,对 Sentinel 限流降级本身的异常(BlockException)不生效。为了统计异常比例或异常数,需要通过 Tracer.trace(ex) 记录业务异常
5、开源整合模块,如:Sentinel Dubbo Adapter、Sentinel Web Servlet Filter、@SentinelResource 注解会自动统计业务异常,无需手动调用
6、熔断降级规则(DegradeRule)包含下面几个重要的属性
| Field | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,即规则的作用对象 | |
| grade | 熔断策略,支持慢调用比例/异常比例/异常数策略 | 慢调用比例 |
| count | 慢调用比例模式下为慢调用临界 RT(超出该值计为慢调用);异常比例/异常数模式下为对应的阈值 | |
| timeWindow | 熔断时长,单位为 s | |
| minRequestAmount | 熔断触发的最小请求数,请求数小于该值时即使异常比率超出阈值也不会熔断(1.7.0 引入) | 5 |
| statIntervalMs | 统计时长(单位为 ms),如 60*1000 代表分钟级(1.8.0 引入) | 1000 ms |
| slowRatioThreshold | 慢调用比例阈值,仅慢调用比例模式有效(1.8.0 引入) |
热点参数限流
1、概述
(1)热点:即经常访问的数据
(2)很多时候希望统计某个热点数据中访问频次最高的 Top K 数据,并对其访问进行限制
(3)热点参数限流会统计传入参数中的热点参数,并根据配置的限流阈值与模式,对包含热点参数的资源调用进行限流
(4)热点参数限流可以看做是一种特殊的流量控制,仅对包含热点参数的资源调用生效

(5)Sentinel 利用 LRU 策略统计最近最常访问的热点参数,结合令牌桶算法来进行参数级别的流控
2、热点参数规则(ParamFlowRule)类似于流量控制规则(FlowRule)
| 属性 | 说明 | 默认值 |
|---|---|---|
| resource | 资源名,必填 | |
| count | 限流阈值,必填 | |
| grade | 限流模式 | QPS 模式 |
| durationInSec | 统计窗口时间长度(单位为秒),1.6.0 版本开始支持 | 1s |
| controlBehavior | 流控效果(支持快速失败和匀速排队模式),1.6.0 版本开始支持 | 快速失败 |
| maxQueueingTimeMs | 最大排队等待时长(仅在匀速排队模式生效),1.6.0 版本开始支持 | 0ms |
| paramIdx | 热点参数的索引,必填,对应 SphU.entry(xxx, args) 中的参数索引位置 | |
| paramFlowItemList | 参数例外项,可以针对指定的参数值单独设置限流阈值,不受前面 count 阈值的限制。仅支持基本类型和字符串类型 | |
| clusterMode | 是否是集群参数流控规则 | false |
| clusterConfig | 集群流控相关配置 |
系统自适应限流
1、背景
(1)Sentinel 做系统自适应保护的目的
(2)保证系统不被拖垮
(3)在系统稳定的前提下,保持系统的吞吐量
(4)长期以来,系统自适应保护的思路是根据硬指标,即系统的负载(load1)来做系统过载保护。当系统负载高于某个阈值,就禁止或者减少流量的进入;当 load 开始好转,则恢复流量的进入。这个思路带来了不可避免的两个问题
(5)load 是一个“果”,如果根据 load 的情况来调节流量的通过率,那么就始终有延迟性。也就意味着通过率的任何调整,都会过一段时间才能看到效果。当前通过率是使 load 恶化的一个动作,那么也至少要过 1 秒之后才能观测到;同理,如果当前通过率调整是让 load 好转的一个动作,也需要 1 秒之后才能继续调整,这样就浪费了系统的处理能力。所以曲线总是会有抖动
(6)恢复慢。下游应用不可靠,导致应用 RT 很高,从而 load 到了一个很高的点。过了一段时间之后下游应用恢复了,应用 RT 也相应减少。这时其实应该大幅度增大流量的通过率;但是由于这个时候 load 仍然很高,通过率的恢复仍然不高
(7)应该根据系统能够处理的请求,和允许进来的请求,来做平衡,而不是根据一个间接的指标(系统 load)来做限流。最终追求的目标是在系统不被拖垮的情况下,提高系统的吞吐率,而不是 load 一定要到低于某个阈值。如果还是按照固有的思维,超过特定的 load 就禁止流量进入,系统 load 恢复就放开流量,这样做的结果是无论怎么调参数,调比例,都是按照果来调节因,都无法取得良好的效果
(8)Sentinel 在系统自适应保护的做法是,用 load1 作为启动控制流量的值,而允许通过的流量由处理请求的能力,即请求的响应时间以及当前系统正在处理的请求速率来决定
2、系统规则
(1)系统保护规则是从应用级别的入口流量进行控制,从单台机器的总体 Load、RT、入口 QPS、线程数四个维度监控应用数据,让系统尽可能跑在最大吞吐量的同时保证系统整体的稳定性
(2)系统保护规则是应用整体维度的,而不是资源维度的,并且仅对入口流量生效
(3)入口流量指的是进入应用的流量(EntryType.IN),比如 Web 服务或 Dubbo 服务端接收的请求,都属于入口流量
3、系统规则支持以下的阈值类型
(1)Load(仅对 Linux / Unix-like 机器生效):当系统 load1 超过阈值,且系统当前的并发线程数超过系统容量时才会触发系统保护。系统容量由系统的 maxQps * minRt 计算得出。设定参考值一般是 CPU cores * 2.5
(2)CPU usage(1.5.0+ 版本):当系统 CPU 使用率超过阈值即触发系统保护(取值范围 0.0-1.0)
(3)RT:当单台机器上所有入口流量的平均 RT 达到阈值即触发系统保护,单位是毫秒
(4)线程数:当单台机器上所有入口流量的并发线程数达到阈值即触发系统保护
(5)入口 QPS:当单台机器上所有入口流量的 QPS 达到阈值即触发系统保护
| Field | 说明 | 默认值 |
|---|---|---|
| highestSystemLoad | load1 触发值,用于触发自适应控制阶段 | -1 (不生效) |
| avgRt | 所有入口流量的平均响应时间 | -1 (不生效) |
| maxThread | 入口流量的最大并发数 | -1 (不生效) |
| qps | 所有入口资源的 QPS | -1 (不生效) |
| highestCpuUsage | 当前系统的 CPU 使用率(0.0-1.0) | -1 (不生效) |
4、原理

(1)把系统处理请求的过程想象为一个水管,到来的请求是往这个水管灌水,当系统处理顺畅的时候,请求不需要排队,直接从水管中穿过,这个请求的 RT 是最短的;反之,当请求堆积的时候,那么处理请求的时间则会变为:排队时间 + 最短处理时间
(2)推论一:如果能够保证水管里的水量,能够让水顺畅的流动,则不会增加排队的请求;也就是说,这个时候的系统负载不会进一步恶化
(3)用 T 来表示水管内部的水量,用 RT 来表示请求的处理时间,用 P 来表示进来的请求数,那么一个请求从进入水管道到从水管出来,这个水管会存在 P * RT 个请求。即当 T ≈ QPS * Avg(RT) 时,可以认为系统的处理能力和允许进入的请求个数达到了平衡,系统的负载不会进一步恶化
(4)接下来的问题是,水管的水位是可以达到了一个平衡点,但是这个平衡点只能保证水管的水位不再继续增高,但是还面临一个问题,就是在达到平衡点之前,这个水管里已经堆积了多少水。如果之前水管的水已经在一个量级了,那么这个时候系统允许通过的水量可能只能缓慢通过,RT 会大,之前堆积在水管里的水会滞留;反之,如果之前的水管水位偏低,那么又会浪费了系统的处理能力
(5)推论二: 当保持入口的流量是水管出来的流量的最大的值时,可以最大利用水管的处理能力
(6)然而,和 TCP BBR 的不一样的地方在于,还需要用一个系统负载的值(load1)来激发这套机制启动
(7)注:这种系统自适应算法对于低 load 的请求,它的效果是一个“兜底”的角色。对于不是应用本身造成的 load 高的情况(如:其它进程导致的不稳定的情况),效果不明显
@SentinelResource
1、注意:注解方式埋点不支持 private 方法
2、@SentinelResource 用于定义资源,并提供可选的异常处理和 fallback 配置项
3、@SentinelResource 注解包含以下属性
(1)value:资源名称,必需项(不能为空)
(2)entryType:entry 类型,可选项(默认为 EntryType.OUT)
(3)blockHandler / blockHandlerClass:blockHandler 对应处理 BlockException 的函数名称,可选项
blockHandler 函数访问范围需要是 public
返回类型需要与原方法相匹配
参数类型需要和原方法相匹配并且最后加一个额外的参数,类型为 BlockException
blockHandler 函数默认需要和原方法在同一个类中
若希望使用其他类的函数,则可以指定 blockHandlerClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析(4)fallback:fallback 函数名称,可选项,用于在抛出异常时提供 fallback 处理逻辑
fallback 函数可以针对所有类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理
返回值类型必须与原函数返回值类型一致
方法参数列表需要和原函数一致,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常
fallback 函数默认需要和原方法在同一个类中
若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析(5)defaultFallback(since 1.6.0):默认的 fallback 函数名称,可选项,通常用于通用的 fallback 逻辑(即可以用于很多服务或方法)
默认 fallback 函数可以针对所以类型的异常(除了 exceptionsToIgnore 里面排除掉的异常类型)进行处理
若同时配置了 fallback 和 defaultFallback,则只有 fallback 会生效
返回值类型必须与原函数返回值类型一致
方法参数列表需要为空,或者可以额外多一个 Throwable 类型的参数用于接收对应的异常
defaultFallback 函数默认需要和原方法在同一个类中
若希望使用其他类的函数,则可以指定 fallbackClass 为对应的类的 Class 对象,注意对应的函数必需为 static 函数,否则无法解析(6)exceptionsToIgnore(since 1.6.0):用于指定哪些异常被排除掉,不会计入异常统计中,也不会进入 fallback 逻辑中,而是会原样抛出
(7)注:1.6.0 之前的版本 fallback 函数只针对降级异常(DegradeException)进行处理,不能针对业务异常进行处理
(8)若 blockHandler 和 fallback 都进行了配置,则被限流降级而抛出 BlockException 时只会进入 blockHandler 处理逻辑
(9)若未配置 blockHandler、fallback 和 defaultFallback,则被限流降级时会将 BlockException 直接抛出
OpenFeign 支持
1、Sentinel 适配 OpenFeign 组件。如果想使用,除了引入 sentinel-starter 的依赖外还需要 2 个步骤
(1)配置文件打开 sentinel 对 feign 的支持:feign.sentinel.enabled=true
(2)加入 openfeign starter 依赖使 sentinel starter 中的自动化配置类生效
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2、Feign 对应的接口中的资源名策略定义:httpmethod:protocol://requesturl。@FeignClient 注解中的所有属性,Sentinel 都做了兼容
规则持久化 / 动态规则扩展
1、Sentinel 的理念是开发者只需要关注资源的定义,当资源定义成功后可以动态增加各种流控降级规则。Sentinel 提供两种方式修改规则:
(1)通过 API 直接修改(loadRules)
(2)通过 DataSource 适配不同数据源修改
2、DataSource 扩展
(1)loadRules() 方法只接受内存态的规则对象,但更多时候规则存储在文件、数据库或者配置中心当中
(2)DataSource 接口提供了对接任意配置源的能力。相比直接通过 API 修改规则,实现 DataSource 接口是更加可靠的做法
(3)推荐通过控制台设置规则后将规则推送到统一的规则中心,客户端实现 ReadableDataSource 接口端监听规则中心实时获取变更,流程如下;

3、DataSource 扩展常见的实现方式有
(1)拉模式:客户端主动向某个规则管理中心定期轮询拉取规则,这个规则中心可以是 RDBMS、文件,甚至是 VCS 等。这样做的方式是简单,缺点是无法及时获取变更
(2)推模式:规则中心统一推送,客户端通过注册监听器的方式时刻监听变化,比如使用 Nacos、Zookeeper 等配置中心。这种方式有更好的实时性和一致性保证
4、Sentinel 目前支持以下数据源扩展
(1)Pull-based:动态文件数据源、Consul、Eureka
(2)Push-based:ZooKeeper、Redis、Nacos、Apollo、etcd
5、推模式:使用 Nacos 配置规则
(1)Sentinel 针对 Nacos 作了适配,底层可以采用 Nacos 作为规则配置数据源。使用时只需添加以下依赖
<dependency>
<groupId>com.alibaba.csp</groupId>
<artifactId>sentinel-datasource-nacos</artifactId>
</dependency>(2)yaml 配置 Nacos 数据源
spring:
cloud:
sentinel:
datasource:
ds1:
nacos:
server-addr: localhost:8848
dataId: ${spring.application.name}
groupId: DEFAULT_GROUP
data-type: json
rule-type: flow(3)Nacos 配置流控规则
[
{
"resource": "/**",
"limitApp": "default",
"grade": 1,
"count": 1,
"strategy": 0,
"controlBehavior": 0,
"clusterMode": false
}
]resource:资源名称
limitApp:来源应用
grade:阈值类型,0表示线程数,1表示QPS
count:单机阈值
strategy:流控模式,0表示直接,1表示关联,2表示链路
controlBehavior:流控效果,0表示快速失败,1表示Warm Up,2表示排队等待
clusterMode:是否集群

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 微软正式发布.NET 10 Preview 1:开启下一代开发框架新篇章
· 没有源码,如何修改代码逻辑?
· PowerShell开发游戏 · 打蜜蜂
· 在鹅厂做java开发是什么体验
· WPF到Web的无缝过渡:英雄联盟客户端的OpenSilver迁移实战