
linux内核负载均衡(二)sched_balance_rq详解
这里有一篇文章讲得很好:http://www.wowotech.net/process_management/load_balance_function.html
我们以6.13-rc2作为基础来分析。
上一篇讲到了触发负载均衡的三种方式:newilde balance,nohz idle balance和周期性balance。sched_balance_rq是核心代码。
sched_balance_rq是在一个sched domain中做负载均衡的,主要思想是将当前的cpu作为目的cpu,从某个调度域中选择比较繁忙的调度组,从该调度组中迁移进程到目的cpu,从而实现负载的均衡。sched domain(调度域)和sched group(调度组)是非常重要的概念,在分析代码之前,我们先sched domain和sched group的概念。
调度域的产生是基于一个事实,系统中cpu是一个层级结构,有smt,mc,numa,socket等层次结构。如果在负载均衡的时候不考虑这些因素会影响进程/系统性能。比如对于有亲和性需求的情况尽可能选择之前的cpu或共享llc的cpu。对于没有亲和性需求的情况可以选择那些idle数量比较多的cpu集合,这样可以减少访存带宽的竞争,提升性能。
调度域是per cpu的,每个cpu都有自己的调度域结构无需跟其他cpu共享。而调度组是在多个cpu间共享的。
调度域是有层级的,最低一层一般是smt域或mc域,它没有子调度域,向上可以找到父调度域,最顶层的调度域包含了系统中的所有cpu。
每个调度域都有多个调度组,有时候我们会发现调度域的child似乎跟它的调度组有相同的cpu集合,事实常常如此,但是不要将两者混为一谈。
下面是sched_domain结构体
| 域 | 含义 |
| struct sched_domain __rcu *parent |
父调度域,调度域是一个层级结构 |
| struct sched_domain __rcu *child | 子调度域 |
| struct sched_group *groups | 调度组,一个调度域由多个调度组组成,组成一个环形链表,groups是链表头 |
| unsigned long min_interval | 均衡间的最小间隔时间 |
| unsigned long max_interval | 负载均衡间的最大时间间隔 |
| unsigned int busy_factor | cpu busy程度,按照cpu busy程度调节均衡间隔时间,busy_factor * balance_interval代表间隔时间 |
| unsigned int imbalance_pct | 负载不均衡门限 |
| unsigned int cache_nice_tries | 和nr_balance_failed配合使用,当nr_balance_failed大于cache_nice_tries会进行更激进的balance |
| unsigned int imb_numa_nr | 对于numa系统允许一定程度的imbalance,这个值的计算见build_sched_domains |
| int nohz_idle | |
| int flags | 调度标志 |
| int level | 调度域在层级中的级别,base为0,逐层向上加1 |
| unsigned long last_balance | 该调度域上次进行负载均衡的时间 |
| unsigned int balance_interval | 基础负载均衡时间间隔,与busy_factor配合使用 |
| unsigned int nr_balance_failed | 该调度域负载均衡失败的次数 |
| u64 max_newidle_lb_cost | 在该domain上进行new idle balance的最大时间间隔(真的吗?),会衰减,防止过大 |
| unsigned long last_decay_max_lb_cost | 记录更新上述cost时的jiffies,也用来控制上面cost的衰减 |
| char *name | 调度域的名字 |
| struct sched_domain_shared *shared | sched_domain是per cpu的,有些变量需要共享,包括调度域中busy cpu个数,是否有idle cpu等 |
| unsigned int span_weight | 调度包含cpu个数 |
| unsigned long span[] | 调度域包含的cpu mask |
sched group结构体
| 成员 | 含义 |
| struct sched_group *next |
本调度域包含的调度组组成的循环链表,next是包含当前cpu的调度组节点 |
| atomic_t ref | 调度组是共享的,这个是引用次数 |
| unsigned int group_weight | 本调度组包含的cpu数 |
| unsigned int cores | |
| struct sched_group_capacity *sgc | 调度组的计算能力 |
| int asym_prefer_cpu | 大小核会用?本调度组最高优先级的cpu |
| int flags | 调度组的标志 |
| unsigned long cpumask[] | 本调度组所包含cpu的cpumask |
linux内核中有一大段注释来讲解调度域和调度组是怎么建立起来的。见topology.c - kernel/sched/topology.c - Linux source code v6.10 - Bootlin Elixir Cross Referencer。可以方便理解build_balance_mask函数。
sched_balance_rq是进行负载均衡的核心函数。
这是它的基本函数流程:
static int sched_balance_rq(int this_cpu, struct rq *this_rq, struct sched_domain *sd, enum cpu_idle_type idle, int *continue_balancing)
先看函数参数。this cpu是指一个idle的cpu,要从其他繁忙的cpu上拉取一些任务过来。this_rq,将任务拉取的这个rq上,sd是在这个调度域上做找繁忙的cpu,idle是当前cpu的idle状态,continue_balancing作为返回值的一部分告诉caller要不要继续做均衡。
static int sched_balance_rq(int this_cpu, struct rq *this_rq, struct sched_domain *sd, enum cpu_idle_type idle, int *continue_balancing) { int ld_moved, cur_ld_moved, active_balance = 0; struct sched_domain *sd_parent = sd->parent; struct sched_group *group; struct rq *busiest; struct rq_flags rf; struct cpumask *cpus = this_cpu_cpumask_var_ptr(load_balance_mask); struct lb_env env = { .sd = sd, .dst_cpu = this_cpu, .dst_rq = this_rq, .dst_grpmask = group_balance_mask(sd->groups), .idle = idle, .loop_break = SCHED_NR_MIGRATE_BREAK, .cpus = cpus, .fbq_type = all, .tasks = LIST_HEAD_INIT(env.tasks), }; cpumask_and(cpus, sched_domain_span(sd), cpu_active_mask); schedstat_inc(sd->lb_count[idle]); redo: if (!should_we_balance(&env)) { *continue_balancing = 0; goto out_balanced; } group = sched_balance_find_src_group(&env); if (!group) { schedstat_inc(sd->lb_nobusyg[idle]); goto out_balanced; } busiest = sched_balance_find_src_rq(&env, group); if (!busiest) { schedstat_inc(sd->lb_nobusyq[idle]); goto out_balanced; } WARN_ON_ONCE(busiest == env.dst_rq); schedstat_add(sd->lb_imbalance[idle], env.imbalance); env.src_cpu = busiest->cpu; env.src_rq = busiest;
sched_balance_rq使用lb_env作为负载均衡的上下文在各个流程中传递信息。
should_we_balance负责判断当前cpu是否可以做负载均衡。
sched_balance_find_src_group也就是以前的find_busiest_group,负责在本调度域中找最忙的调度组作为迁移进程的源调度组;
sched_balance_find_src_rq就是之前的find_busiest_rq,负责在上面选处理的最忙调度组中找出最忙的rq;
现在已经找到了最忙的rq,可以开始迁移了。
ld_moved = 0; /* Clear this flag as soon as we find a pullable task */ env.flags |= LBF_ALL_PINNED; if (busiest->nr_running > 1) { /* * Attempt to move tasks. If sched_balance_find_src_group has found * an imbalance but busiest->nr_running <= 1, the group is * still unbalanced. ld_moved simply stays zero, so it is * correctly treated as an imbalance. */ env.loop_max = min(sysctl_sched_nr_migrate, busiest->nr_running); more_balance: rq_lock_irqsave(busiest, &rf); update_rq_clock(busiest); /* * cur_ld_moved - load moved in current iteration * ld_moved - cumulative load moved across iterations */ cur_ld_moved = detach_tasks(&env); /* * We've detached some tasks from busiest_rq. Every * task is masked "TASK_ON_RQ_MIGRATING", so we can safely * unlock busiest->lock, and we are able to be sure * that nobody can manipulate the tasks in parallel. * See task_rq_lock() family for the details. */ rq_unlock(busiest, &rf); if (cur_ld_moved) { attach_tasks(&env); ld_moved += cur_ld_moved; }
使用ld_moved记录总的迁移量,,迁移可能进行多轮,cur_ld_moved记录每次的迁移量。迁移要锁住rq,因此时间不能太久,设置loop_max限制最大的迭代次数。
detach_tasks负责在选中的rq上选择env->imbalance指定数量的task取下来放到env的task list中。
attach_tasks负责从env中取出要迁移的task,enqueue到当前group中,增加ld_moved的值。
if (env.flags & LBF_NEED_BREAK) { env.flags &= ~LBF_NEED_BREAK; goto more_balance; } /* * Revisit (affine) tasks on src_cpu that couldn't be moved to * us and move them to an alternate dst_cpu in our sched_group * where they can run. The upper limit on how many times we * iterate on same src_cpu is dependent on number of CPUs in our * sched_group. * * This changes load balance semantics a bit on who can move * load to a given_cpu. In addition to the given_cpu itself * (or a ilb_cpu acting on its behalf where given_cpu is * nohz-idle), we now have balance_cpu in a position to move * load to given_cpu. In rare situations, this may cause * conflicts (balance_cpu and given_cpu/ilb_cpu deciding * _independently_ and at _same_ time to move some load to * given_cpu) causing excess load to be moved to given_cpu. * This however should not happen so much in practice and * moreover subsequent load balance cycles should correct the * excess load moved. */ if ((env.flags & LBF_DST_PINNED) && env.imbalance > 0) { /* Prevent to re-select dst_cpu via env's CPUs */ __cpumask_clear_cpu(env.dst_cpu, env.cpus); env.dst_rq = cpu_rq(env.new_dst_cpu); env.dst_cpu = env.new_dst_cpu; env.flags &= ~LBF_DST_PINNED; env.loop = 0; env.loop_break = SCHED_NR_MIGRATE_BREAK; /* * Go back to "more_balance" rather than "redo" since we * need to continue with same src_cpu. */ goto more_balance; } /* * We failed to reach balance because of affinity. */ if (sd_parent) { int *group_imbalance = &sd_parent->groups->sgc->imbalance; if ((env.flags & LBF_SOME_PINNED) && env.imbalance > 0) *group_imbalance = 1; } /* All tasks on this runqueue were pinned by CPU affinity */ if (unlikely(env.flags & LBF_ALL_PINNED)) { __cpumask_clear_cpu(cpu_of(busiest), cpus); /* * Attempting to continue load balancing at the current * sched_domain level only makes sense if there are * active CPUs remaining as possible busiest CPUs to * pull load from which are not contained within the * destination group that is receiving any migrated * load. */ if (!cpumask_subset(cpus, env.dst_grpmask)) { env.loop = 0; env.loop_break = SCHED_NR_MIGRATE_BREAK; goto redo; } goto out_all_pinned; } }
LBF_NEED_BREAK是用来做中场休息的,其实还没有迁移完,所以这时候只是释放rq锁,然后再回去重新来迁移进程。
LBF_DST_PINNED是指要被迁移的task因为affinity的原有没法迁移,将env.dst_cpu换成env.new_dst_cpu再去试试。
LBF_SOME_PINNED是指因为affinity的原有无法迁移进程,让父调度域去解决。
LBF_ALL_PINNED说明所有task都pin住了,没法迁移,清除在排除掉busiest group的cpu尝试重新选择busiest group从头再来。
if (!ld_moved) { schedstat_inc(sd->lb_failed[idle]); /* * Increment the failure counter only on periodic balance. * We do not want newidle balance, which can be very * frequent, pollute the failure counter causing * excessive cache_hot migrations and active balances. * * Similarly for migration_misfit which is not related to * load/util migration, don't pollute nr_balance_failed. */ if (idle != CPU_NEWLY_IDLE && env.migration_type != migrate_misfit) sd->nr_balance_failed++; if (need_active_balance(&env)) { unsigned long flags; raw_spin_rq_lock_irqsave(busiest, flags); /* * Don't kick the active_load_balance_cpu_stop, * if the curr task on busiest CPU can't be * moved to this_cpu: */ if (!cpumask_test_cpu(this_cpu, busiest->curr->cpus_ptr)) { raw_spin_rq_unlock_irqrestore(busiest, flags); goto out_one_pinned; } /* Record that we found at least one task that could run on this_cpu */ env.flags &= ~LBF_ALL_PINNED; /* * ->active_balance synchronizes accesses to * ->active_balance_work. Once set, it's cleared * only after active load balance is finished. */ if (!busiest->active_balance) { busiest->active_balance = 1; busiest->push_cpu = this_cpu; active_balance = 1; } preempt_disable(); raw_spin_rq_unlock_irqrestore(busiest, flags); if (active_balance) { stop_one_cpu_nowait(cpu_of(busiest), active_load_balance_cpu_stop, busiest, &busiest->active_balance_work); } preempt_enable(); } } else { sd->nr_balance_failed = 0; }
如果ld_moved为0说明迁移进程失败了。增加sd->nr_balance_failed计数。
使用need_active_balance判断是否需要对正在运行的task进行迁移。如果需要,会调用stop_one_cpu_nowait去唤醒migration线程去做迁移。
如果ld_moved不为0,说明至少成功迁移1个进程,可以收工了。
下面对关键函数进行分析:
先介绍一个数据结构lb_env,函数利用它来进行控制信息传递。
struct lb_env env = { .sd = sd, .dst_cpu = this_cpu, //当前cpu,也就是要将remote task拉到这里来 .dst_rq = this_rq, //当前rq .dst_grpmask = group_balance_mask(sd->groups), //可以用来load balance的cpu .idle = idle, //cpu idle类型,0是not idle, .loop_break = SCHED_NR_MIGRATE_BREAK, // detach task的时候不能太久,循环一定次数就休息以下 .cpus = cpus, .fbq_type = all, .tasks = LIST_HEAD_INIT(env.tasks), // 存放要迁移的task };
should_we_balance,判断是否要进行均衡。
static int should_we_balance(struct lb_env *env) { struct cpumask *swb_cpus = this_cpu_cpumask_var_ptr(should_we_balance_tmpmask); struct sched_group *sg = env->sd->groups; int cpu, idle_smt = -1;
//判断一下当前cpu是不是可以用,或许已经被hotunplug了。 if (!cpumask_test_cpu(env->dst_cpu, env->cpus)) return 0;
// 对于将要进入idle状态的cpu,只要rq没有进程,也不会有将要被唤醒的进程就return 1 if (env->idle == CPU_NEWLY_IDLE) { if (env->dst_rq->nr_running > 0 || env->dst_rq->ttwu_pending) return 0; return 1; }
cpumask_copy(swb_cpus, group_balance_mask(sg)); /* Try to find first idle CPU */
// 从调度组中找到第一个idle的cpu for_each_cpu_and(cpu, swb_cpus, env->cpus) { if (!idle_cpu(cpu)) continue; // 先不要为busy core的idle smt做均衡,但是记着这个idle smt if (!(env->sd->flags & SD_SHARE_CPUCAPACITY) && !is_core_idle(cpu)) { if (idle_smt == -1) idle_smt = cpu; /* * If the core is not idle, and first SMT sibling which is * idle has been found, then its not needed to check other * SMT siblings for idleness: */ #ifdef CONFIG_SCHED_SMT cpumask_andnot(swb_cpus, swb_cpus, cpu_smt_mask(cpu)); #endif continue; } // 走到这里肯定是找到了一个idle cpu,看看它是不是就是当前的cpu,如果是才返回1。 return cpu == env->dst_cpu; } /* Are we the first idle CPU with busy siblings? */
// 走到这里说明没找到一个idle core,但是可能存在一个idle smt,看看是不是本cpu if (idle_smt != -1) return idle_smt == env->dst_cpu; /* Are we the first CPU of this group ? */
// 走到这里说明没有idle cpu,看看当前cpu是不是调度组中可被用作均衡的第一个cpu return group_balance_cpu(sg) == env->dst_cpu; }
大致就是在当前的调度组里找idle的cpu,如果没有就用当前调度组里可用做均衡的第一个cpu,但是两者必须都满足等于当前cpu才可以,因为我们就是要在当前的cpu上做均衡,其实就是在验证当前cpu的条件。
sched_balance_find_src_group会找到当前调度域里面最繁忙的调度组。下面是一张决策表:
| busiest\local type | has_spare | fully_busy | misfit | asym | imbalanced | overloaded |
| has_spare | nr_idle | balanced | N/A | N/A | balanced | balanced |
| fully_busy | nr_idle | nr_ilde | N/A | N/A | balanced | balanced |
| misfit_task | force | N/A | N/A | N/A | N/A | N/A |
| asym_packing | force | force | N/A | N/A | force | force |
| imbalanced | force | force | N/A | N/A | force | force |
| overloaded | force | force | N/A | N/A | force | avg_load |
这个表在该函数的注释里。下面是具体含义:
busiest是指要对比的调度组,local是本地调度组,表中的第一行/列代表调度组的类型;
N/A: 不适用,该情况已经过滤掉;
balanced: 这两个group已经平衡了;
force:需要迁移负载,计算imbalance;
avg_load:根据imbalance的值确定;
nr_idle: dst_cpu不太忙,这俩组的idle cpu相差较大;
可以看出,如果当前的调度组比较闲而另一个组比较忙,那一定是要做迁移的,其他情况可以对照这个表来看。
static struct sched_group *sched_balance_find_src_group(struct lb_env *env) { struct sg_lb_stats *local, *busiest; struct sd_lb_stats sds; init_sd_lb_stats(&sds); /* * Compute the various statistics relevant for load balancing at * this level. */ update_sd_lb_stats(env, &sds); //找到本调度域最忙的调度组 /* There is no busy sibling group to pull tasks from */ if (!sds.busiest) goto out_balanced; busiest = &sds.busiest_stat; //下面开始做判断
主要的逻辑就是先调用update_sd_lb_stats找到本调度域中最繁忙的调度组,接下来就根据上面的决策表来判断。update_sd_lb_stats是一个非常关键的函数,后面详细分析。
/* Misfit tasks should be dealt with regardless of the avg load */ ... if (busiest->group_type == group_imbalanced) goto force_balance; local = &sds.local_stat; if (local->group_type > busiest->group_type) goto out_balanced; if (local->group_type == group_overloaded) { ... } ... force_balance: /* Looks like there is an imbalance. Compute it */ calculate_imbalance(env, &sds); return env->imbalance ? sds.busiest : NULL; out_balanced: env->imbalance = 0; return NULL; }
忽略掉的判断大致是比较local group跟busiest group之间的负载差异,再两者之间尽量做均衡,因为只能从busiest拉取任务到local,如果local比busiest还要忙,即使不均衡也当成均衡来对待。最终如果需要均衡就会跳到force_balance,执行calculate_imbalance计算imbalance的值,也就是需要迁移多少负载。
这里涉及到group type的枚举值来表示调度组现在的忙闲状态。
| enum group_type | 含义 |
| group_has_spare = 0 | 组内有剩余算力 |
| group_fully_busy | 组内cpu没有剩余算力 |
| group_misfit_task | 组内有task运行在算力较小的cpu上,需要迁移。适用于非对称系统 |
| group_smt_balance | 均衡smt group,可以将运行在一个core内所有smt都在忙的超线程上的task迁移到另一个idle core上 |
| group_asym_packing | 异构系统适用,local cpu有算力更大的cpu可用 |
| group_imbalanced | task被affinity设置限制,阻止了之前的负载均衡 |
| group_overloaded | 组内cpu过载 |
这些都是在update_sd_lb_stats算出来的,且可以通过比较大小来确定busy程度,越大越忙。在update_sd_pick_busiest中会用到这一点来选出最忙的组。
sched_balance_find_src_rq会在上面选好的调度组里找最繁忙的rq。
detach_tasks
static int detach_tasks(struct lb_env *env) { struct list_head *tasks = &env->src_rq->cfs_tasks; while (!list_empty(tasks)) { env->loop++; /* We've more or less seen every task there is, call it quits */ if (env->loop > env->loop_max) break; /* take a breather every nr_migrate tasks */ if (env->loop > env->loop_break) { env->loop_break += SCHED_NR_MIGRATE_BREAK; env->flags |= LBF_NEED_BREAK; break; } p = list_last_entry(tasks, struct task_struct, se.group_node); if (!can_migrate_task(p, env)) goto next; switch (env->migration_type) { case migrate_load: load = max_t(unsigned long, task_h_load(p), 1); if (sched_feat(LB_MIN) && load < 16 && !env->sd->nr_balance_failed) goto next; /* * Make sure that we don't migrate too much load. * Nevertheless, let relax the constraint if * scheduler fails to find a good waiting task to * migrate. */ if (shr_bound(load, env->sd->nr_balance_failed) > env->imbalance) goto next; env->imbalance -= load; break; case migrate_util: util = task_util_est(p); if (shr_bound(util, env->sd->nr_balance_failed) > env->imbalance) goto next; env->imbalance -= util; break; case migrate_task: env->imbalance--; break; case migrate_misfit: /* This is not a misfit task */ if (task_fits_cpu(p, env->src_cpu)) goto next; env->imbalance = 0; break; } detach_task(p, env); list_add(&p->se.group_node, &env->tasks); detached++; #ifdef CONFIG_PREEMPTION /* * NEWIDLE balancing is a source of latency, so preemptible * kernels will stop after the first task is detached to minimize * the critical section. */ if (env->idle == CPU_NEWLY_IDLE) break; #endif /* * We only want to steal up to the prescribed amount of * load/util/tasks. */ if (env->imbalance <= 0) break; continue; next: list_move(&p->se.group_node, tasks); } return detached; }
从源rq里拿到cfs_tasks,遍历这个task链表,从最后一个开始拿task,这样可以尽量避免task还处于cache hot的状态。取出一个task后,使用can_migrate_task判断该task是否可以迁移。如果可以,根据migrate_type来做不同的计算方式,在每一轮的循环中都做判断是继续迁移。但是migrate_type是task还是load,util,最终都是通过迁移task来实现的。如果不能迁移task就将这个task放到cfs_tasks 链表的头部。
detach_task负责将进程供rq上取下来。取下的task挂到env->tasks上。对于newly idle的情形迁移一个进程也就可以了。如果当前imblance值已经较小到0以下就可以完工了。
detach_task
static void detach_task(struct task_struct *p, struct lb_env *env) { lockdep_assert_rq_held(env->src_rq); deactivate_task(env->src_rq, p, DEQUEUE_NOCLOCK); set_task_cpu(p, env->dst_cpu); } void deactivate_task(struct rq *rq, struct task_struct *p, int flags) { SCHED_WARN_ON(flags & DEQUEUE_SLEEP); WRITE_ONCE(p->on_rq, TASK_ON_RQ_MIGRATING); ASSERT_EXCLUSIVE_WRITER(p->on_rq); /* * Code explicitly relies on TASK_ON_RQ_MIGRATING begin set *before* * dequeue_task() and cleared *after* enqueue_task(). */ dequeue_task(rq, p, flags); }
detach_task调用deactivate_task将task从rq从取下来,设置task的cpu为env->dst_cpu,但是此时task还没有加入到任何cpu。
deactivate_task将task的on_rq成员设置为TASK_ON_RQ_MIGRATING,调用dequeue_task将task从rq中取下来。
attach_tasks
static void attach_tasks(struct lb_env *env) { struct list_head *tasks = &env->tasks; struct task_struct *p; struct rq_flags rf; rq_lock(env->dst_rq, &rf); update_rq_clock(env->dst_rq); while (!list_empty(tasks)) { p = list_first_entry(tasks, struct task_struct, se.group_node); list_del_init(&p->se.group_node); attach_task(env->dst_rq, p); } rq_unlock(env->dst_rq, &rf); }
attach_tasks从env的task list中一个个取出task,调用attach_task将其加入env->dst_rq中。
static void attach_task(struct rq *rq, struct task_struct *p) { lockdep_assert_rq_held(rq); WARN_ON_ONCE(task_rq(p) != rq); activate_task(rq, p, ENQUEUE_NOCLOCK); wakeup_preempt(rq, p, 0); }
void activate_task(struct rq *rq, struct task_struct *p, int flags) { if (task_on_rq_migrating(p)) flags |= ENQUEUE_MIGRATED; if (flags & ENQUEUE_MIGRATED) sched_mm_cid_migrate_to(rq, p); enqueue_task(rq, p, flags); WRITE_ONCE(p->on_rq, TASK_ON_RQ_QUEUED); ASSERT_EXCLUSIVE_WRITER(p->on_rq); }
attach_task最终调用enqueue_task将task加入到dst rq中。设置task on_rq成员为TASK_ON_RQ_QUEUED。
need_active_balance
static int need_active_balance(struct lb_env *env) { struct sched_domain *sd = env->sd; if (asym_active_balance(env)) return 1; if (imbalanced_active_balance(env)) return 1; /* * The dst_cpu is idle and the src_cpu CPU has only 1 CFS task. * It's worth migrating the task if the src_cpu's capacity is reduced * because of other sched_class or IRQs if more capacity stays * available on dst_cpu. */ if (env->idle && (env->src_rq->cfs.h_nr_running == 1)) { if ((check_cpu_capacity(env->src_rq, sd)) && (capacity_of(env->src_cpu)*sd->imbalance_pct < capacity_of(env->dst_cpu)*100)) return 1; } if (env->migration_type == migrate_misfit) return 1; return 0; }
判断在异构和imbalanced情形下是否需要进行active balance。
如果dst cpu是idle的,src rq只有一个task,如果src cpu的算力很低也会去做active balance。
如果迁移类型是migrate_misfit返回1。其他情况返回0。
imbalanced_active_balance
static inline bool imbalanced_active_balance(struct lb_env *env) { struct sched_domain *sd = env->sd; /* * The imbalanced case includes the case of pinned tasks preventing a fair * distribution of the load on the system but also the even distribution of the * threads on a system with spare capacity */ if ((env->migration_type == migrate_task) && (sd->nr_balance_failed > sd->cache_nice_tries+2)) return 1; return 0; }
如果迁移类型为migrate_task,且迁移失败的次数超过sd->cache_nice_tries+2就认为需要进行active balance。
can_migrate_task
static int can_migrate_task(struct task_struct *p, struct lb_env *env) { int tsk_cache_hot; lockdep_assert_rq_held(env->src_rq); /* * We do not migrate tasks that are: * 1) throttled_lb_pair, or * 2) cannot be migrated to this CPU due to cpus_ptr, or * 3) running (obviously), or * 4) are cache-hot on their current CPU. */ if (throttled_lb_pair(task_group(p), env->src_cpu, env->dst_cpu)) return 0; /* Disregard percpu kthreads; they are where they need to be. */ if (kthread_is_per_cpu(p)) return 0; if (!cpumask_test_cpu(env->dst_cpu, p->cpus_ptr)) { int cpu; schedstat_inc(p->stats.nr_failed_migrations_affine); env->flags |= LBF_SOME_PINNED; /* * Remember if this task can be migrated to any other CPU in * our sched_group. We may want to revisit it if we couldn't * meet load balance goals by pulling other tasks on src_cpu. * * Avoid computing new_dst_cpu * - for NEWLY_IDLE * - if we have already computed one in current iteration * - if it's an active balance */ if (env->idle == CPU_NEWLY_IDLE || env->flags & (LBF_DST_PINNED | LBF_ACTIVE_LB)) return 0; /* Prevent to re-select dst_cpu via env's CPUs: */ for_each_cpu_and(cpu, env->dst_grpmask, env->cpus) { if (cpumask_test_cpu(cpu, p->cpus_ptr)) { env->flags |= LBF_DST_PINNED; env->new_dst_cpu = cpu; break; } } return 0; } /* Record that we found at least one task that could run on dst_cpu */ env->flags &= ~LBF_ALL_PINNED; if (task_on_cpu(env->src_rq, p)) { schedstat_inc(p->stats.nr_failed_migrations_running); return 0; } /* * Aggressive migration if: * 1) active balance * 2) destination numa is preferred * 3) task is cache cold, or * 4) too many balance attempts have failed. */ if (env->flags & LBF_ACTIVE_LB) return 1; tsk_cache_hot = migrate_degrades_locality(p, env); if (tsk_cache_hot == -1) tsk_cache_hot = task_hot(p, env); if (tsk_cache_hot <= 0 || env->sd->nr_balance_failed > env->sd->cache_nice_tries) { if (tsk_cache_hot == 1) { schedstat_inc(env->sd->lb_hot_gained[env->idle]); schedstat_inc(p->stats.nr_forced_migrations); } return 1; } schedstat_inc(p->stats.nr_failed_migrations_hot); return 0; }
注释似乎已经比较清楚了。对于以下情形不做迁移:
1. throttled进程组;
2. per cpu线程;
3. dst cpu没有包含在task的cpus_ptr内;
4. task正在运行;
对下面的情形会进行比较激进的迁移:
1. env flag有LBF_ACTIVE_LB标签;
2. 没有numa对局部性的影响;
3. cache是冷的;
4. 失败了很多次;
我们来看看这个numa局部性对进程迁移的影响。
#ifdef CONFIG_NUMA_BALANCING /* * Returns 1, if task migration degrades locality * Returns 0, if task migration improves locality i.e migration preferred. * Returns -1, if task migration is not affected by locality. */ static int migrate_degrades_locality(struct task_struct *p, struct lb_env *env) { struct numa_group *numa_group = rcu_dereference(p->numa_group); unsigned long src_weight, dst_weight; int src_nid, dst_nid, dist; if (!static_branch_likely(&sched_numa_balancing)) return -1; if (!p->numa_faults || !(env->sd->flags & SD_NUMA)) return -1; src_nid = cpu_to_node(env->src_cpu); dst_nid = cpu_to_node(env->dst_cpu); if (src_nid == dst_nid) return -1; /* Migrating away from the preferred node is always bad. */ if (src_nid == p->numa_preferred_nid) { if (env->src_rq->nr_running > env->src_rq->nr_preferred_running) return 1; else return -1; } /* Encourage migration to the preferred node. */ if (dst_nid == p->numa_preferred_nid) return 0; /* Leaving a core idle is often worse than degrading locality. */ if (env->idle == CPU_IDLE) return -1; dist = node_distance(src_nid, dst_nid); if (numa_group) { src_weight = group_weight(p, src_nid, dist); dst_weight = group_weight(p, dst_nid, dist); } else { src_weight = task_weight(p, src_nid, dist); dst_weight = task_weight(p, dst_nid, dist); } return dst_weight < src_weight; }
可以看出,这个函数是在开启NUMA_BALANCE才会有意义。开头的注释很明确:返回1说明迁移对numa局部性有影响,返回0说明对numa局部性有益,返回-1说明对numa 局部性无关。
首先是检查sched_numa_balancing有没有打开,如果没打开就认为对numa局部性无影响,其实这只能说明numa balance没生效的情况,在事实上可能会对numa亲和性造成影响。
如果task struct没有numa_faults或者当前的调度域不跨numa也认为对numa局部性无影响,其实这一点可以说明对numa亲和性无影响。
如果dst cpu和src cpu在一个node上,也认为是numa局部性无关的。
如果src node是task的numa_preferred_nid,且src rq上可运行的进程大于nr_preferred_running,说明迁移会对numa局部性造成影响。
如果dst node是task的preferred node,那么认为迁移有利;
还考虑了numa group的影响。
总的来说can_migrate_task考虑了numa的影响,但是只是一个软限制,当迁移失败的次数较多时依然会迁移对numa亲和性不利的task。
即使在can_migrate_task做一些改动,让其对某些task不做迁移,也会因为增加nr_balance_failed次数,导致引发active_balance,从而唤醒migrate线程去进行更激进的进程迁移。可见,内核对load balance的执着,顽强,在一切可能的情形下去做load balance。但是在migration线程中也会调用can_migration_task去判断是否可以迁移线程,这样can_migration_task应该是可以阻止线程迁移的一个点。
本篇还留了一个小尾巴,对于active balance那一块还没有深入的讲解,在下一篇会分析有关migration 线程的代码。
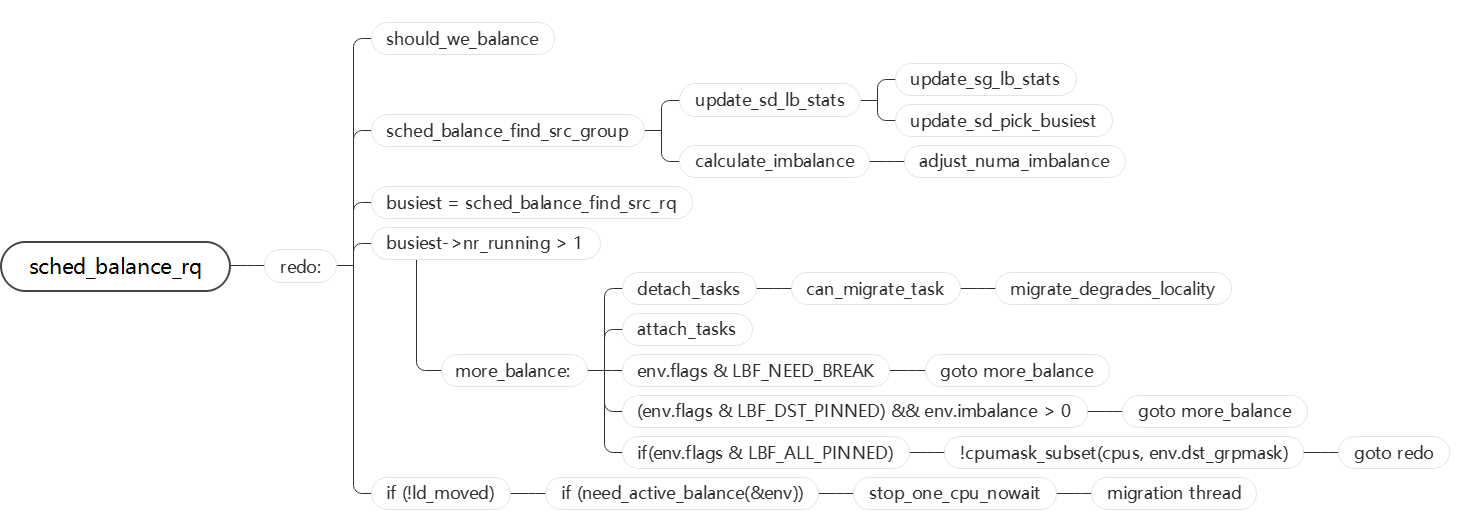
sched_balance_rq函数非常复杂,下面用一个函数流程图作为结束。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号