

linux kernel负载均衡分析(一)
linux的负载均衡是一个很负载的过程,本篇讲一下触发负载均衡的流程,下一篇具体讲load balance流程。
负载均衡是kernel调度一个重要的方面,下面是三篇博客,讲得很好。
CFS任务的负载均衡(任务放置) (wowotech.net)
CFS任务的负载均衡(load balance) (wowotech.net)
在6.10以后的内核中,原来的rebalance_domains改名为sched_balance_domains。load_balance改名为sched_balance_rq。
sched_balance_rq是一个负载均衡的必经之路,从它的调用路径可以看到负载均衡的几种触发方式。
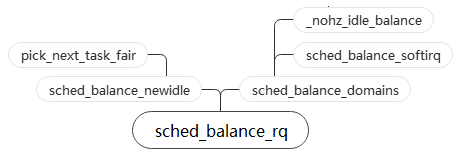
上面这张图是sched_balance_rq的调用链。可以看到直接调用它的有两个函数,sched_balance_newidle和sched_balance_domains,分别来看。
sched_balance_newidle的情况
调用它的是pick_next_task_fair,这个函数是在cfs调度器中选择下一个task时调用的,而它嗲用sched_balance——newidle的前提时当前没有可供调用的task,在进入idle状态之前,调用sched_balance_newidle尝试从其他busy的cpu上拉取task。总结一下这种情形,在cpu进入idle之前先看看其他cpu有没有多余的task。
static int sched_balance_newidle(struct rq *this_rq, struct rq_flags *rf) { unsigned long next_balance = jiffies + HZ; int this_cpu = this_rq->cpu; int continue_balancing = 1; u64 t0, t1, curr_cost = 0; struct sched_domain *sd; int pulled_task = 0; update_misfit_status(NULL, this_rq); /* * There is a task waiting to run. No need to search for one. * Return 0; the task will be enqueued when switching to idle. */ if (this_rq->ttwu_pending) //如果这个rq有被选中作为ttwu的cpu rq,返回 return 0; /* * We must set idle_stamp _before_ calling sched_balance_rq() * for CPU_NEWLY_IDLE, such that we measure the this duration * as idle time. */ this_rq->idle_stamp = rq_clock(this_rq); /* * Do not pull tasks towards !active CPUs... */ if (!cpu_active(this_cpu)) return 0; /* * This is OK, because current is on_cpu, which avoids it being picked * for load-balance and preemption/IRQs are still disabled avoiding * further scheduler activity on it and we're being very careful to * re-start the picking loop. */ rq_unpin_lock(this_rq, rf); rcu_read_lock(); sd = rcu_dereference_check_sched_domain(this_rq->sd); if (!get_rd_overloaded(this_rq->rd) || //root domain没有overload的cpu (sd && this_rq->avg_idle < sd->max_newidle_lb_cost)) { //rq的avg_idle小于max_newidle_lb_cost if (sd) update_next_balance(sd, &next_balance); rcu_read_unlock(); goto out; } rcu_read_unlock(); raw_spin_rq_unlock(this_rq); t0 = sched_clock_cpu(this_cpu); //记录当前的时间用于测量负载均衡的时间作为domain cost sched_balance_update_blocked_averages(this_cpu); rcu_read_lock(); for_each_domain(this_cpu, sd) { 开始沿着当前cpu最低domain向上进行负载均衡 u64 domain_cost; update_next_balance(sd, &next_balance); if (this_rq->avg_idle < curr_cost + sd->max_newidle_lb_cost) //当前rq的avg_idle没有当前已经产生的cost+max_newidle_lb_cost大 break; //说明代价过大,break if (sd->flags & SD_BALANCE_NEWIDLE) { //当前的domain允许newidle balance pulled_task = sched_balance_rq(this_cpu, this_rq, //负载均衡核心函数 sd, CPU_NEWLY_IDLE, &continue_balancing); t1 = sched_clock_cpu(this_cpu); //这次负载均衡结束,看一下时间 domain_cost = t1 - t0; //domain cost就是这次负载均衡消耗的时间 update_newidle_cost(sd, domain_cost); curr_cost += domain_cost; // curr cost记录本次newidle balance总的耗时 t0 = t1; } /* * Stop searching for tasks to pull if there are * now runnable tasks on this rq. */ if (pulled_task || !continue_balancing) //这次拉取到了task,或者不能再继续做balance,break break; } rcu_read_unlock(); raw_spin_rq_lock(this_rq); if (curr_cost > this_rq->max_idle_balance_cost) this_rq->max_idle_balance_cost = curr_cost; //如果这次newidle balance耗时超过max,更新max cost /* * While browsing the domains, we released the rq lock, a task could * have been enqueued in the meantime. Since we're not going idle, * pretend we pulled a task. */ if (this_rq->cfs.h_nr_running && !pulled_task) //在我们做balance的时候,有人塞给我们一个task,假装已经拉取到了一个task pulled_task = 1; /* Is there a task of a high priority class? */ if (this_rq->nr_running != this_rq->cfs.h_nr_running) pulled_task = -1; out: /* Move the next balance forward */ if (time_after(this_rq->next_balance, next_balance)) this_rq->next_balance = next_balance; if (pulled_task) this_rq->idle_stamp = 0; //拉取到task设置idle时间戳为0, why? else nohz_newidle_balance(this_rq); rq_repin_lock(this_rq, rf); return pulled_task; }
如果拉取到任务,pick_next_task_fair会重新pick task,将拉取到的task调度上去。
sched_balance_domains的情况
调用它的函数有两个:sched_balance_softirq和_nohz_idle_balance。但从上面那张图很难了解到这两个函数的调用栈。我们再看一下下面这张图。

这张图有点复杂。我们看到,调用sched_balance_domains和_nohz_idle_balance的都是sched_balance_softirq。
static __latent_entropy void sched_balance_softirq(struct softirq_action *h) { struct rq *this_rq = this_rq(); enum cpu_idle_type idle = this_rq->idle_balance; /* * If this CPU has a pending NOHZ_BALANCE_KICK, then do the * balancing on behalf of the other idle CPUs whose ticks are * stopped. Do nohz_idle_balance *before* sched_balance_domains to * give the idle CPUs a chance to load balance. Else we may * load balance only within the local sched_domain hierarchy * and abort nohz_idle_balance altogether if we pull some load. */ if (nohz_idle_balance(this_rq, idle)) return; /* normal load balance */ sched_balance_update_blocked_averages(this_rq->cpu); sched_balance_domains(this_rq, idle); }
这是sched软中断的处理函数。它会先尝试nohz_idle_balance,如果成功直接返回,反之会再调用sched_balance_domains。在linux中,如果开启了nohz,cpu是可以在空闲的时候关闭时钟中断,也叫tickless mode。处于nohz idle状态的cpu是不会有时钟中断的,当busy cpu需要空闲cpu的帮助时,可以使用nohz_idle_balance,发送ipi中断给idle cpu,让idle cpu将本地的task拉取过去。如果成功拉取,自然不需要本地再进行负载均衡。sched_balance_domains是正常的负载均衡。
再向上看的话可以发现开启sched软中断的途径有两种,都是再update_process_times内,也就是在时钟中断处理函数内,也就是说sched软中断是周期性调用的。
sched_balance_trigger负责开启软中断。有两种途径。
/* * Trigger the SCHED_SOFTIRQ if it is time to do periodic load balancing. */ void sched_balance_trigger(struct rq *rq) { /* * Don't need to rebalance while attached to NULL domain or * runqueue CPU is not active */ if (unlikely(on_null_domain(rq) || !cpu_active(cpu_of(rq)))) return; if (time_after_eq(jiffies, rq->next_balance)) raise_softirq(SCHED_SOFTIRQ); nohz_balancer_kick(rq); }
该函数的入参是rq,这种周期性的load balance是针对当前cpu的。两种情况触发,
第一是当前时刻已经到了下一次该做负载均衡的时间,判断的方法是对比当前的jiffies和rq->next_balance的值;
第二种是调用nohz_balance_kick,它会选则一个idle cpu来求援,让其帮忙拉取本地任务过去。
nohz的情形比较复杂,重点看一下。
static void nohz_balancer_kick(struct rq *rq) { unsigned long now = jiffies; struct sched_domain_shared *sds; struct sched_domain *sd; int nr_busy, i, cpu = rq->cpu; unsigned int flags = 0; if (unlikely(rq->idle_balance)) return; /* * We may be recently in ticked or tickless idle mode. At the first * busy tick after returning from idle, we will update the busy stats. */ nohz_balance_exit_idle(rq); /* * None are in tickless mode and hence no need for NOHZ idle load * balancing: */ if (likely(!atomic_read(&nohz.nr_cpus))) //nohz是一个全局变量,表示处于nohz状态的cpu,数量,cpumask等。这一行判断当前是不是没有处于
return; //nohz状态的cpu if (READ_ONCE(nohz.has_blocked) && time_after(now, READ_ONCE(nohz.next_blocked))) //到了next blocked时间,这啥意思? flags = NOHZ_STATS_KICK; if (time_before(now, nohz.next_balance)) //还没到balance的时间 goto out; if (rq->nr_running >= 2) { //当前的rq任务数量大于1个 flags = NOHZ_STATS_KICK | NOHZ_BALANCE_KICK; goto out; } rcu_read_lock(); sd = rcu_dereference(rq->sd); if (sd) { /* * If there's a runnable CFS task and the current CPU has reduced * capacity, kick the ILB to see if there's a better CPU to run on: */ if (rq->cfs.h_nr_running >= 1 && check_cpu_capacity(rq, sd)) { //当前cpu太弱,请求更强的cpu帮忙 flags = NOHZ_STATS_KICK | NOHZ_BALANCE_KICK; goto unlock; } } sd = rcu_dereference(per_cpu(sd_asym_packing, cpu)); if (sd) { /* * When ASYM_PACKING; see if there's a more preferred CPU * currently idle; in which case, kick the ILB to move tasks * around. * * When balancing between cores, all the SMT siblings of the * preferred CPU must be idle. */ for_each_cpu_and(i, sched_domain_span(sd), nohz.idle_cpus_mask) { if (sched_asym(sd, i, cpu)) { flags = NOHZ_STATS_KICK | NOHZ_BALANCE_KICK; goto unlock; } } } sd = rcu_dereference(per_cpu(sd_asym_cpucapacity, cpu)); if (sd) { /* * When ASYM_CPUCAPACITY; see if there's a higher capacity CPU * to run the misfit task on. */ if (check_misfit_status(rq)) { flags = NOHZ_STATS_KICK | NOHZ_BALANCE_KICK; goto unlock; } /* * For asymmetric systems, we do not want to nicely balance * cache use, instead we want to embrace asymmetry and only * ensure tasks have enough CPU capacity. * * Skip the LLC logic because it's not relevant in that case. */ goto unlock; } sds = rcu_dereference(per_cpu(sd_llc_shared, cpu)); if (sds) { /* * If there is an imbalance between LLC domains (IOW we could * increase the overall cache utilization), we need a less-loaded LLC * domain to pull some load from. Likewise, we may need to spread * load within the current LLC domain (e.g. packed SMT cores but * other CPUs are idle). We can't really know from here how busy * the others are - so just get a NOHZ balance going if it looks * like this LLC domain has tasks we could move. */ nr_busy = atomic_read(&sds->nr_busy_cpus); //llc domain的busy cpu数量大于1 if (nr_busy > 1) { flags = NOHZ_STATS_KICK | NOHZ_BALANCE_KICK; goto unlock; } } unlock: rcu_read_unlock(); out: if (READ_ONCE(nohz.needs_update)) flags |= NOHZ_NEXT_KICK; if (flags) kick_ilb(flags); //去叫一个cpu过来帮忙 }
这个函数决定在什么情况下去喊idle core帮忙:到了next blocked时间 || 当前rq大于1个task || 当前cpu太弱 || 当前cpu所在的llc domain的busy cpu大于1 || nohz.needs_update不为0。如果当前还没到balance的时间且nohz.needs_update为0则不会触发。
static void kick_ilb(unsigned int flags) { int ilb_cpu; /* * Increase nohz.next_balance only when if full ilb is triggered but * not if we only update stats. */ if (flags & NOHZ_BALANCE_KICK) nohz.next_balance = jiffies+1; ilb_cpu = find_new_ilb(); //找一个idle的cpu。 if (ilb_cpu < 0) return; /* * Don't bother if no new NOHZ balance work items for ilb_cpu, * i.e. all bits in flags are already set in ilb_cpu. */ if ((atomic_read(nohz_flags(ilb_cpu)) & flags) == flags) //如果传入的flag跟ilb cpu rq的flag相比没有新增则返回,rq的nohz_flag是啥意思? return; /* * Access to rq::nohz_csd is serialized by NOHZ_KICK_MASK; he who sets * the first flag owns it; cleared by nohz_csd_func(). */ flags = atomic_fetch_or(flags, nohz_flags(ilb_cpu)); if (flags & NOHZ_KICK_MASK) return; /* * This way we generate an IPI on the target CPU which * is idle, and the softirq performing NOHZ idle load balancing * will be run before returning from the IPI. */ smp_call_function_single_async(ilb_cpu, &cpu_rq(ilb_cpu)->nohz_csd); //向我们选中的cpu发ipi中断 }
关键是要找一个合适的idle cpu。
static inline int find_new_ilb(void) { const struct cpumask *hk_mask; int ilb_cpu; hk_mask = housekeeping_cpumask(HK_TYPE_MISC); for_each_cpu_and(ilb_cpu, nohz.idle_cpus_mask, hk_mask) { if (ilb_cpu == smp_processor_id()) continue; if (idle_cpu(ilb_cpu)) return ilb_cpu; } return -1; }
找idle cpu的范围是nohz的idle_cpus_mask成员。还要满足housekeeping的要求。在发送完ipi中断后,ipi中断处理函数会调用nohz_csd_func处理nohz相关的事务。
static void nohz_csd_func(void *info) { struct rq *rq = info; int cpu = cpu_of(rq); unsigned int flags; /* * Release the rq::nohz_csd. */ flags = atomic_fetch_andnot(NOHZ_KICK_MASK | NOHZ_NEWILB_KICK, nohz_flags(cpu)); WARN_ON(!(flags & NOHZ_KICK_MASK)); rq->idle_balance = idle_cpu(cpu); if (rq->idle_balance && !need_resched()) { rq->nohz_idle_balance = flags; raise_softirq_irqoff(SCHED_SOFTIRQ); } }
检查完标志位后,给rq的idle_balance赋值,用于表示当前cpu是否位idle cpu,最后触发sched softirq。记住当前的cpu已经不是发送ipi中断的那个cpu了。
这样nohz idle balance trigger sched 软中断的情况就分析完了。我们来看一下具体处理nohz idle balance的函数。
static bool nohz_idle_balance(struct rq *this_rq, enum cpu_idle_type idle) { unsigned int flags = this_rq->nohz_idle_balance; if (!flags) return false; this_rq->nohz_idle_balance = 0; if (idle != CPU_IDLE) return false; _nohz_idle_balance(this_rq, flags); return true; }
一些必要的检查后调用_nohz_idle_balance。
static void _nohz_idle_balance(struct rq *this_rq, unsigned int flags) { /* Earliest time when we have to do rebalance again */ unsigned long now = jiffies; unsigned long next_balance = now + 60*HZ; bool has_blocked_load = false; int update_next_balance = 0; int this_cpu = this_rq->cpu; int balance_cpu; struct rq *rq; SCHED_WARN_ON((flags & NOHZ_KICK_MASK) == NOHZ_BALANCE_KICK); /* * We assume there will be no idle load after this update and clear * the has_blocked flag. If a cpu enters idle in the mean time, it will * set the has_blocked flag and trigger another update of idle load. * Because a cpu that becomes idle, is added to idle_cpus_mask before * setting the flag, we are sure to not clear the state and not * check the load of an idle cpu. * * Same applies to idle_cpus_mask vs needs_update. */ if (flags & NOHZ_STATS_KICK) WRITE_ONCE(nohz.has_blocked, 0); if (flags & NOHZ_NEXT_KICK) WRITE_ONCE(nohz.needs_update, 0); /* * Ensures that if we miss the CPU, we must see the has_blocked * store from nohz_balance_enter_idle(). */ smp_mb(); /* * Start with the next CPU after this_cpu so we will end with this_cpu and let a * chance for other idle cpu to pull load. */ for_each_cpu_wrap(balance_cpu, nohz.idle_cpus_mask, this_cpu+1) { //_nohz_idle_balance不是只在被kick的cpu上做 if (!idle_cpu(balance_cpu)) //负载均衡,而是在所有idle core上,也不是拉取 continue; //kicker的任务,而是在每个idle core做负载均衡 /* * If this CPU gets work to do, stop the load balancing * work being done for other CPUs. Next load * balancing owner will pick it up. */ if (need_resched()) { //如果当前的cpu需要调度,放弃本次load balance,设置blocked_load if (flags & NOHZ_STATS_KICK) //设置nohz的needs update has_blocked_load = true; if (flags & NOHZ_NEXT_KICK) WRITE_ONCE(nohz.needs_update, 1); goto abort; } rq = cpu_rq(balance_cpu); if (flags & NOHZ_STATS_KICK) has_blocked_load |= update_nohz_stats(rq); /* * If time for next balance is due, * do the balance. */ if (time_after_eq(jiffies, rq->next_balance)) { struct rq_flags rf; rq_lock_irqsave(rq, &rf); update_rq_clock(rq); rq_unlock_irqrestore(rq, &rf); if (flags & NOHZ_BALANCE_KICK) sched_balance_domains(rq, CPU_IDLE); //标志设置了nohz_balance_kick,进行负载均衡 } if (time_after(next_balance, rq->next_balance)) { next_balance = rq->next_balance; update_next_balance = 1; } } /* * next_balance will be updated only when there is a need. * When the CPU is attached to null domain for ex, it will not be * updated. */ if (likely(update_next_balance)) nohz.next_balance = next_balance; if (flags & NOHZ_STATS_KICK) WRITE_ONCE(nohz.next_blocked, now + msecs_to_jiffies(LOAD_AVG_PERIOD)); abort: /* There is still blocked load, enable periodic update */ if (has_blocked_load) WRITE_ONCE(nohz.has_blocked, 1); //设置has blocked,表示本次idle balance没完成 }
nohz并非在kickee cpu上做负载均衡,而是在所有idle cpu上尝试做负载均衡。不想newidle balance,它只在自己的cpu,沿着domain做balance。
nohz的情形分析完了。


