
豆瓣电影高分排行榜爬虫
豆瓣电影高分排行榜爬虫
一、选题背景
随着经济发展,文化娱乐活动越来越为人们所重视,当代电影便是其中具有重要影响力的一项内容,好的电影能使人愉悦、促进文化交流、提升人文素养,而且还能一定程度上带动经济的发展。因此,了解、认知什么是好电影,什么是高分电影,便显得尤为重要。
本项目计划爬取豆瓣电影高分排行榜前250名,通过对爬取的信息进行统筹分析、可视化,直观的描述出高分电影的分数、类型等信息,更加清晰的展示出高分电影的特征,为大家认识、了解高分电影提供数据基础。
二、主题式网络爬虫设计方案
1、主题式网络爬虫名称
豆瓣电影高分排行榜爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
本项目爬取豆瓣电影高分排行榜页面前250名的电影信息,包括电影名、豆瓣评分、url、导演、主演、电影类型、时长、评分人数、简介,共计信息250条、9个字段,以xlsx格式保存为本地excel文件。
3.主题式网络爬虫设计方案概述
通过豆瓣电影排行榜页面,分析页面组成,找到排行榜数据接口,分析从接口可获得的信息字段,然后根据每部电影的具体url地址,进入详情页,再通过静态页面提取的方法,提取补充信息。最终将信息合并,保存至本地。
技术难点有解析接口与相应请求信息,以及每部电影详情页当中,信息不一定完整,有可能造成提取失败,因此需要在爬取过程中做出应对措施。
三、主题页面的结构特征分析
1、主题页面的结构与特征分析
通过刷新与加载页面,找到所需电影信息主要来自于动态加载的json数据,字段包括casts、cover、cover_x、cover_y、directors、id、rate、star、title、url,请求地址为https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=%E7%94%B5%E5%BD%B1&start=0,其中最后一个参数为翻页参数,所需提交的表单信息有sort、range、tags、start。
2、Htmls页面解析
通过电影url进入详情页,分析页面组成,可知所需补充提取的信息(电影类型、时长、评分人数、简介)均由静态页面构成,可直接通过xpath提取。

3、数据获取流程
首先模拟浏览器向排行榜接口发送请求,每次所得数据包含了20个电影的信息。然后通过循环操作提取json数据,将每部影片信息依次保存,同时进入电影详情页,xpath提取补充数据。通过变换翻页参数重复请求,最终得到所需的全部电影信息。
三、 网络爬虫程序设计
1.数据爬取与采集
import requests import json from lxml import etree import pandas as pd import matplotlib.pyplot as plt import jieba from wordcloud import WordCloud from scipy.optimize import leastsq import numpy as np ''' 豆瓣电影高分排行榜 https://movie.douban.com/tag/#/?sort=S&range=0,10&tags=%E7%94%B5%E5%BD%B1 ''' #设置请求头. headers={ 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.110 Safari/537.36 Edg/96.0.1054.62', 'Host':'movie.douban.com', } #获取影片列表. def get_list(start0): url=f'https://movie.douban.com/j/new_search_subjects?sort=S&range=0,10&tags=%E7%94%B5%E5%BD%B1&start={start0}' post_data = { 'sort': 'S', 'range': '0,10', 'tags': '电影', 'start': start0, } response=requests.get(url,headers=headers,data=post_data) return response.content.decode('utf-8') movie_title=[] #名称 movie_rate=[] #评分 movie_url=[] #地址 movie_directors=[] #导演 movie_casts=[] #主演 genre=[] #类型 runtime=[] #时长 rating_people=[] #评分人数 summary=[] #简介 #获取影片详细信息 def get_info(url): response=requests.get(url,headers=headers).text html=etree.HTML(response) try: #提取类型 genre0=html.xpath('//span[@property="v:genre"]//text()') except: genre0=0 try: #提取时长 runtime0=html.xpath('//span[@property="v:runtime"]//text()')[0] except: runtime0=0 try: #提取评分人数 rating_people0=html.xpath('//span[@property="v:votes"]//text()')[0] except: rating_people0=0 try: #提取简介 summary0=html.xpath('//span[@property="v:summary"]//text()')[0] except: summary0=0 genre.append(genre0) runtime.append(runtime0) rating_people.append(rating_people0) summary.append(summary0) #获取影片信息. def get_movie(response): json_data=json.loads(response) for i in json_data['data']: #循环提取json内容 print('正在获取: ',i) movie_title.append(i['title']) movie_rate.append(i['rate']) movie_url.append(i['url']) movie_directors.append(i['directors']) movie_casts.append(i['casts']) get_info(i['url']) #运行爬虫,提取前260个. for i in range(0,250,20): response=get_list(i) get_movie(response) #整合数据,保存前250. result=pd.DataFrame({'title':movie_title[0:250],'rate':movie_rate[0:250],'url':movie_url[0:250],'directors':movie_directors[0:250],'casts':movie_casts[0:250],'genre':genre[0:250],'runtime':runtime[0:250],'rating_people':rating_people[0:250],'summary':summary[0:250]}) print(result)
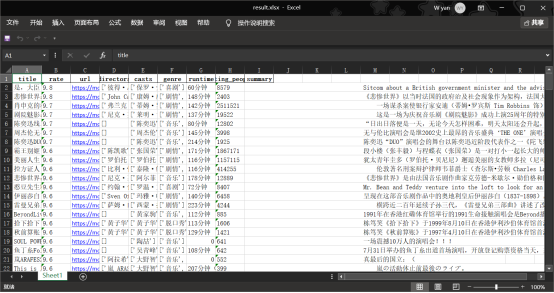
运行后结果如下,得到250条影片信息:
2、对数据进行清洗和处理
#读取数据. data=pd.read_excel('result.xlsx') print(data) #数据清洗. #去除空格、换行. def remove_rn(str0): if str0==0: return None return str0.replace('\n','').replace('\r','') data['title']=data['title'].apply(remove_rn) data['url']=data['url'].apply(remove_rn) data['directors']=data['directors'].apply(remove_rn) data['casts']=data['casts'].apply(remove_rn) data['summary']=data['summary'].apply(remove_rn) #去除summary中特殊字符,无描述的替换为空格. def remove_u(str0): if str0==None: return ' ' return str0.replace('\u3000','') data['summary']=data['summary'].apply(remove_u) #修正directors、casts内容. def get_dc(str0): if len(str0)==2: return None return str0[2:-2] data['directors']=data['directors'].apply(get_dc) data['casts']=data['casts'].apply(get_dc) #提取时长数字. def get_runtime(str0): if str0==0: return None return str0[:-2] data['runtime']=data['runtime'].apply(get_runtime) #提取主要影片类型. def get_main_genre(str0): return str0[0] data['main_genre']=data['genre'].apply(get_main_genre) #保存清洗后的数据. data.to_excel('result(清洗后).xlsx',index=None)
运行后得到结果如下:

3、文本分析
#电影简介词云. #获取文本. text=list(data['summary']) print(text) text=' '.join(text) text=text.replace(',','').replace('。','').replace('“','').replace('“','').replace(' ','').replace('\n','').replace('、','').replace('—','').replace('(','').replace(')','').replace('…','').replace('·','') #分词. text_list=jieba.cut(text) text_list2=' '.join(text_list) text_list3=text_list2.split(' ') #去重. words_list=list(set(text_list3)) words_count=[text_list3.count(i) for i in words_list] words_data=pd.DataFrame({'words':words_list,'counts':words_count}) #词语、词频从大到小排列. words_data=words_data.sort_values('counts',ascending=False) #绘制词云. exclude0=["的","我","是","都","就","也","你","她","他","有","这","人","很","和","我们","要","在","等","了","不",'A','自己','中','与','被','将','上','年','对','他们','从','却','后','并','但','着','饰','为','日','于','の'] wc=WordCloud(background_color='white',stopwords=exclude0,font_path="C:\Windows\Fonts\simfang.ttf").generate(' '.join(list(words_data['words']))) plt.figure() plt.axis('off') plt.imshow(wc,interpolation="bilinear")
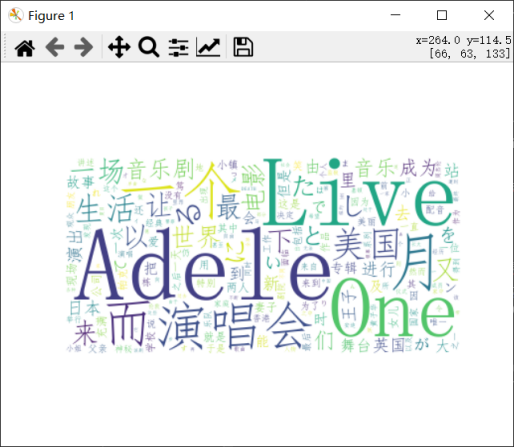
运行后得到词云如下:
4、数据分析可视化
#前50名柱状图. x=data['title'][0:50] y=data['rate'][0:50] plt.figure() plt.barh(x,y,height=0.5) plt.rcParams['font.sans-serif']=['SimHei'] #matplotlib中文字体. plt.xlim(9.2,10) plt.xlabel('评分') ax=plt.gca() ax.spines['right'].set_visible(False) #取消边框 ax.spines['top'].set_visible(False) ax.spines['left'].set_visible(False)
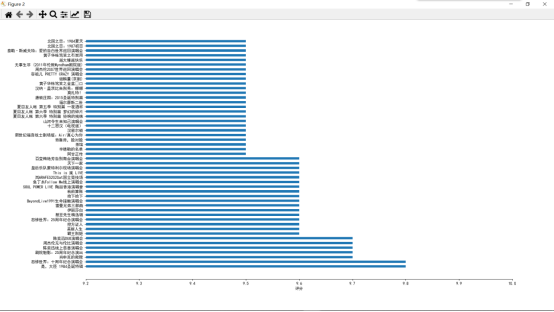
运行后得到前50名影片评分柱状图,结果如下:
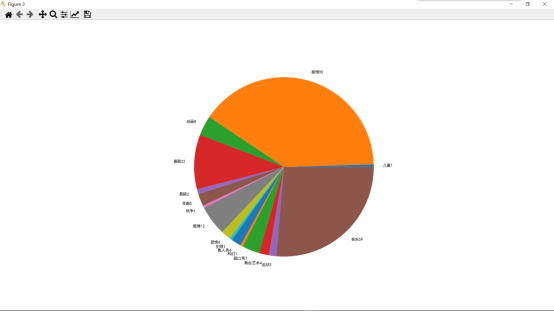
#影片类型饼状图. x=data.groupby('main_genre')['main_genre'].unique() y=data.groupby('main_genre')['main_genre'].count() x=[x[i][0]+str(y[i]) for i in range(len(x))] plt.figure() plt.pie(y,labels=x)
运行后得到前250名影片中,各类型影片数量的饼状图,如下:
5、数据分析
#影片评分与评分人数的关系. rate_l=list(data['rate']) rating_people_l=list(data['rating_people']) plt.figure() plt.scatter(rating_people_l,rate_l) x0=np.array(rating_people_l) y0=np.array(rate_l) def model(p,x): a,b=p return a*x+b def error(p,x,y): return model(p,x)-y p0=[1,20] model1=leastsq(error,p0,args=(x0,y0)) a,b=model1[0] x_l=np.linspace(0,3000000,100000) y_l=a*x_l+b plt.plot(x_l,y_l,c='red',label=str(a)+'*x+'+str(b),alpha=0.7) plt.xlim(0,3000000) plt.ylim(8,10) plt.xlabel('评论人数') plt.ylabel('评分') plt.legend() plt.show()
运行后得到评论人数与评分的散点图、线性回归直线如下:

五、项目总结
1.结论
豆瓣高分影片分数集中于9.0分以上。前250名影片中,剧情片90部,数量最多,音乐片次之,59部,第三高分类型为喜剧,22部。评论人数与影片评分高低无明显相关关系。
本次项目基本达到预期。
2.收获与建议
进行爬虫项目前,要清晰、有逻辑地分析网页和数据来源,确定好爬虫思路,爬取过程中,所得的数据不一定完整,也不一定能直接使用,要做好对应补充、清洗措施。将来的项目中,程序要更加逻辑化,更加简洁,以便高效完成任务。
