


AlexNet模型的解析及tensorflow实现
AlexNet是ImageNet LSVRC 2012比赛中分类效果第一的深度神经网络模型,点击链接下载论文http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf
1.模型的表现及结果
AlexNet模型主要在ILSVRC2010数据集与ILSVRC2012数据集上进行了训练与测试。在2012年的测试集上,模型取得top-5 error 15.3%,比第2名26.2%高了不少。由于ILSVRC2010的测试集的标签可用,AlexNet在2010测试集上[top-1error 37.5%,top-5 error 17.0%],比当时的第一名[top-1 error 45.7%,top-5 error 25.7%]效果好了不少。
2.数据集
ILSVRC2012的数据集约120万张图像,共包含1000个类。对图像数据集进行的预处理包括:
(a) 统一所有的图像大小为256x256。将图像的短边缩放为256,然后截取缩放后的图像中心256x256的图像;
(b) 对缩放后的 256*256 训练图像统计均值,并对所有图像减去均值。具体实现时并不像论文所写的计算每个像素的均值,而是统计所有图像的RGB均值[r,g,b],并在训练以及测试时减去这个均值[r,g,b]。网络上有预训练好的AlexNet模型代码,其中训练集的RGB均值为[124., 117., 104.]。
训练集与测试集的图像不参与均值的计算,但是会进行缩放,并且减去均值。
数据扩增部分采取的操作:
3.网络结构
3.1 AlexNet由8层神经网络层组成,分别是 input -> { 卷积层1 -> 卷积层2 -> 卷积层3 -> 卷积层4 -> 卷积层5 -> FC6 -> FC7 -> FC8 } -> softmax。网络的输入是[N, 227, 227, 3],图像的大小是[227, 227, 3]。

输入层:
输入: [227x227x3]
第1层:conv1 -> relu -> norm1 -> max pool1
conv1:96个11x11 filter, stride=4, pad=0. output=[55x55x96]
max pool1:3x3 filter, stride=2. output=[27x27x96]
第2层:conv2 -> relu -> norm2 -> max pool2
conv2: 256个5x5 filter, stride=1, pad=2. output=[27x24x256]
max pool2: 3x3 filter, stride=2. output=[13x13x256]
第3层:conv3 -> relu
conv3: 384个3x3 filter, stride=1, pad=1. output=[13x13x384]
第4层:conv4 -> relu
conv4: 384个3x3 filter, stride=1, pad=1. output=[13x13x384]
第5层:conv5 -> relu -> max pool5
conv5: 256个3x3 filter, stride=1, pad=1. output=[13x13x256]
max pool5: 3x3 filter, stride=2. output=[6x6x256]
第6层:
FC6 -> relu -> dropout 6, 4096个神经元
第7层:
FC7 -> relu -> dropout 7, 4096个神经元
第8层:
FC8, 1000个神经元
3.2 神经网络层的说明,按照它们的重要程度的顺序进行
(a) Relu非线性
神经元的输出函数一般是tanh(x)或者sigmoid(x),本文使用Relu非线性函数 f(x) = max(0, x). 在利用梯度下降进行训练时,饱和非线性函数(tanh,sigmoid)比非饱和非线性函数(relu)速度更慢。使用relu的深层卷积网络比使用tanh的网络训练要快上几倍。
(b) Training on GPUs
GTX580 GPU内存3GB,在两块这样的GPU上进行训练,利用并行的方式。
(c) Local Response Normalization(LRN)
Relu已经不需要normalization就可以防止饱和现象,但是本文发现LRN依然可以帮助提升模型的泛化性能。本文的LRN如下,
其中 aix,y 含义是第 i 个卷积核在(x,y)处的输出经过 relu 的结果,bix,y 指的是aix,y 经过LRN后的结果。
n是邻近的n个卷积核输出,卷积核的书序是训练之前就人为确定的,N是本层的所有卷积核数目。k,n,α,β是超参数,由验证集决定,训练中使用 k = 2, n = 5, α = 10-4, β = 0.75
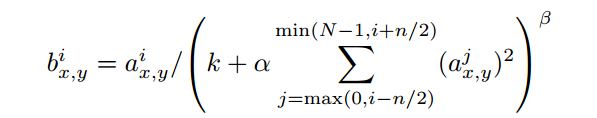
LRN分别减少模型的top-1 error 1.4%和top-5 error 1.2%。
(d) Overlapping Pooling
常规的pooling都是 z=2, s=2, 本文使用z=3, s=2,所以pooling时会有重叠现象,这减少模型的top-1 error 0.4% 和 top-5 error 0.3%,而且观察到重叠池化不易过拟合。
3.3 损失函数(优化目标)
AlexNet模型的优化目标是 最大化多类逻辑回归,等价于最大化交叉熵(maxmizing the average cross training case of the log-probability of the correct label under the prediction distribution)。
4. 减少过拟合
整个模型大概有6000万的参数,主要采用2种方法减少过拟合。
4.1 数据扩增(Data Augmentation)
减少模型的过拟合最简单与常用的方法就是人工的扩增数据集。本文使用的扩增图像数据的方法计算简单,所以新增的图像无须提前存储在硬盘上(即可以随时生成)。
第一种是图像平移与水平翻转,训练时,在256x256图像上取 224x224 大小的图像以及它们的水平翻转图像,因此一张图像可以扩展到 (256-224)*(256-224)* 2 = 2048张,数据集可以扩展到2048倍。 实际都是取227x227的图像作为模型的输入,因此2048倍变为(256-227+1)*(256-227+1)* 2 =1800,这样就扩增了数据集1800倍。
测试时,取 256x256 图像的4个角与中心的224x224图像以及它们的水平翻转图像共10张,输入模型后,将softmax层在这10个图像上的预测平均值作为原图像的预测。
第二种是改变训练集的图像在RGB通道的值。本文对训练集图像的RGB通道像素执行PCA,将PCA的特征值乘上随机量,随机量是从均值为0,标准差0.1的高斯分布中取的。
原图像 = [p1, p2, p3] [α1, α2, α3]T,加入随机量之后图像 = [p1, p2, p3] [α1λ1, α2λ2, α3λ3]T,λ就是随机量。
4.2 Dropout
训练过程中,以概率p使隐层中的神经元的输出为0,则神经元就被 dropout了,它们的输出不会影响到前向传播,也不会参与BP。每次迭代都有不同的神经元被dropout,可以看作是模型得到不同结构的网络,这些网络共享权重。Dropout使得一个神经元的输出不能依赖于特定的神经元,减少了神经元之间复杂的互适应关系,使得模型学到的特征更加健壮。
测试时,不使用dropout,全部神经元参与预测,但是所有神经元的输出 x 0.5。
本文在全连接层的前2层使用dropout技术,可以缓解过拟合问题。但是dropout使得迭代次数加倍才能收敛。
5. 模型实现的一些细节
5.1 使用SGD优化模型,batch_size=128, momentum=0.9,weight_decay=0.0005,
i 是迭代次数,ν是momentum,ε是学习率,<φL/φω|ωi>是第i个batch Di的关于ωi偏导的平均
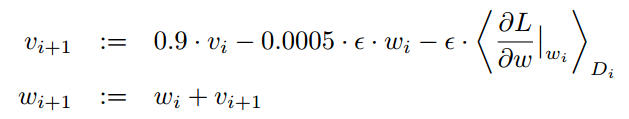
5.2 初始化参数
每层的权重w初始化:均值=0,标准差=0.01的高斯分布
第2,4,5层,全连接层 的偏差biases初始化:全1
其余层的偏差biases:全0
5.3 学习率
初始学习率0.01。当验证集精度不再增加时,就手动的将学习率减小10倍,在训练停止前学习率减小了3次(学习率1e-5)。总共进行了90个epoch的训练,在两块NVIDIA GTX580 3GB GPU上面运行了5~6天。
6. 结果
6.1 模型在ImageNet数据集上的效果


6.2 模型评估
第一个图可视化显示了与图像紧邻的卷积核学到的特征。
第2个图显示了图像经过模型后产生的 (FC-7)4096维特征,如果两个图像的4096维特征的欧氏距离比较近,那么模型就认为这两个图像在全局水平上比较相似(内容相似,类别相同等...)。
第1层的96个卷积核直接从图像上学到的特征。由于两个GPU分开连接,GPU1上的卷积核主要学到颜色无关的特征,而GPU2主要学到颜色相关的特征。每次训练都是这种特征差异,而且与随机初始化无关。

左边是ILSVRC-2010的8张图像,每张图像下面的黑色字体是图像的正确标签,紧接着的下面是模型预测的图像的前5个最有可能的标签。红色标签标示模型的预测正确(top-5)。


右边的第一列是ILSVRC-2010测试集的图像,剩下的6列是训练集中的图像,经过模型产生的特征4096维特征(FC-7),与测试集图像的4096维特征的欧氏距离最近的6个图像。
计算两个4096维特征的欧氏距离,计算效率比较低,但是可以训练自动编码机(AE)将长向量压缩为短二维码,这可以作为一个比较好的图像检索方法。
7. 讨论
在视频处理方面使用更深更大的卷积网络,因为视频中包含了静态图像所不具备的丰富的时空信息。

