
linux下部署kafka和zookeeper集群
因为kafka是依赖于zookeeper来协调管理的,安装kafka之前我们需要先安装zookeeper,而zookeeper的运行又需要jdk来编译,所以安装zookeeper之前应该先安装jkd。所以,我们需要依次安装:jdk——>zookeeper——>kafka。
一、安装jdk
1、检查系统是否安装了openJDK
有的CentOS系统默认安装了openJDK,检查当前系统是否已安装openJDK,如果安装了先卸载。检查openJDK是否安装:rpm -qa|grep jdk,如果安装了openJDK,先卸载掉openJDK。
2、下载jdk
链接:https://pan.xunlei.com/s/VMy6jDb8mbQSvi-TzaEVTg-6A1 提取码:dywg
3、新建java目录,将jdk安装包上传到java目录
# cd /usr/local
# mkdir java
4、解压安装包
tar -zxvf jdk-8u162-linux-x64.tar.gz
5、配置环境变量
# vi /etc/profile
在文件末尾添加如下配置:
export JAVA_HOME=/usr/local/java/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar
6、使/etc/profile生效
# source /etc/profile
7、验证是否安装成功
# java -version
二、搭建zookeeper集群
因为我只有一台Linux服务器,所以在一台机器上创建三个zk实例,通过设置不同的端口号,搭建一个zookeeper伪集群。
1、先在官网下载了最新版本:https://zookeeper.apache.org/releases.html
wget https://archive.apache.org/dist/zookeeper/zookeeper-3.5.7/apache-zookeeper-3.5.7-bin.tar.gz
记一个坑:zookeeper的3.5.5—>3.6.0这几个版本,在下载的时候你会发现它有-bin.tar.gz和tar.gz两个版本,我们一般自然而然的就下载了tar.gz,这是个坑,这几个版本的tar.gz是源码包,里面没有jar包,我们要下载-bin.tar.gz才能正确安装。
2、新建一个zookeeper-cluster目录,将安装包上传到zookeeper-cluster目录下
# cd /usr/local/
# mkdir zookeeper-cluster
3、解压安装包
# cd zookeeper-cluster/ # tar -zxvf zookeeper-3.4.14.tar.gz
4、配置zk1(先配一个节点,然后再复制两份修改相关配置)
# mv zookeeper-3.4.14 zk1 > 新建data、logs目录,分别用来存放数据和日志 # cd zk1/ # mkdir {data,logs} > 进入conf,将zoo_sample.cfg 重命名为 zoo.cfg # cd zk1/conf/ # mv zoo_sample.cfg zoo.cfg > 修改conf下的zoo.cfg配置文件 ① 修改:dataDir=/usr/local/zookeeper-cluster/zk1/data ② 添加:dataLogDir=/usr/local/zookeeper-cluster/zk1/logs ③ clientPort=2181【clientPort是客户端的请求端口】 ④ 在zoo.cfg文件末尾追加【注意IP是内网IP,伪集群的话写127.0.0.1也可以】 server.1=172.17.80.219:2881:3881 server.2=172.17.80.219:2882:3882 server.3=172.17.80.219:2883:3883
解释:server.实例ID=实例IP:zk服务之间通信端口:zk服务之间投票选举端口;
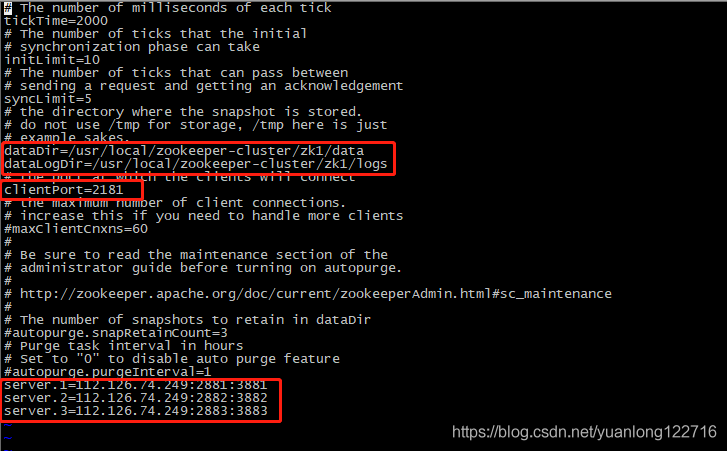
> 在 zk1 的 data 目录下创建一个 myid 文件,内容为1
# cd zk1/data/ # echo 1 > myid
至此,zk1节点配置完成,我们复制两份zk2、zk3,再修改zk2、zk3的相关配置就可以了。
5、配置zk2 > 用zk1复制一份zk2 # cd /usr/local/zookeeper-cluster/ # cp -r zk1 zk2 > 修改zk2的zoo.conf文件 dataDir=/usr/local/zookeeper-cluster/zk2/data dataLogDir=/usr/local/zookeeper-cluster/zk2/logs clientPort=2182 > 修改zk2的data目录下的myid文件 # cd /usr/local/zookeeper-cluster/zk2/data/ # vi myid 将内容修改为2。 6、配置zk3 > 用zk1复制一份zk3 # cd /usr/local/zookeeper-cluster/ # cp -r zk1 zk3 > 修改zk3的zoo.conf文件 dataDir=/usr/local/zookeeper-cluster/zk3/data dataLogDir=/usr/local/zookeeper-cluster/zk3/logs clientPort=2183 > 修改zk3的data目录下的myid文件 # cd /usr/local/zookeeper-cluster/zk3/data/ # vi myid 将内容修改为3
7、开放防火墙端口
开放上面配置涉及到的端口:
2181/2182/2183、2881/2882/2883、3881/3882/3883
8、启动集群
# cd /usr/local/zookeeper-cluster/zk1/bin/ # ./zkServer.sh start # cd /usr/local/zookeeper-cluster/zk2/bin/ # ./zkServer.sh start # cd /usr/local/zookeeper-cluster/zk3/bin/ # ./zkServer.sh start
9、查看启动状态
# cd /usr/local/zookeeper-cluster/zk1/bin/ # ./zkServer.sh status # cd /usr/local/zookeeper-cluster/zk2/bin/ # ./zkServer.sh status # cd /usr/local/zookeeper-cluster/zk3/bin/ # ./zkServer.sh status
三、搭建kafka集群
kafka配置与启动 (kafka_2.13-3.0.0)
wget https://archive.apache.org/dist/kafka/2.4.1/kafka_2.11-2.4.1.tgz
2、新建一个kafka-cluster目录,将安装包上传到kafka-cluster目录下
# cd /usr/local/
# mkdir kafka-cluster
3、解压安装包,重命名
# tar -zxvf kafka_2.12-2.4.0.tgz # mv kafka_2.12-2.4.0 kafka1
4、修改配置文件
# cd /usr/local/kafka-cluster/kafka1/config/
# vi server.properties
※修改如下配置项
# 集群内不同实例的broker.id必须为不重复的数字 broker.id=0 # listeners配置kafka的host和port【同样使用内网IP】 listeners=PLAINTEXT://172.17.80.219:9092 # kafka数据和log的存放目录 log.dirs=/usr/local/kafka-cluster/kafka1/logs # zookeeper集群的ip和端口,用英文逗号分隔 zookeeper.connect=172.17.80.219:2181,172.17.80.219:2182,172.17.80.219:2183 # 在配置文件中添加如下配置,表示允许删除topic delete.topic.enable=true
5、配置kafka2(将kafka1拷一份,修改相关配置) # cp -r kafka1 kafka2 # cd kafka2/config/ # vi server.properties broker.id=1 listeners=PLAINTEXT://172.17.80.219:9093 log.dirs=/usr/local/kafka-cluster/kafka2/logs zookeeper.connect=172.17.80.219:2181,172.17.80.219:2182,172.17.80.219:2183 delete.topic.enable=true 6、配置kafka3(将kafka1拷一份,修改相关配置) # cp -r kafka1 kafka3 # cd kafka3/config/ # vi server.properties broker.id=2 listeners=PLAINTEXT://172.17.80.219:9094 log.dirs=/usr/local/kafka-cluster/kafka3/logs zookeeper.connect=172.17.80.219:2181,172.17.80.219:2182,172.17.80.219:2183 delete.topic.enable=true
kafka基本配置
#基本配置 #broker的全局唯一编号,不能重复 broker.id=0 #删除topic功能使能 delete.topic.enable=true # The number of threads that the server uses for receiving requests from the network and sending responses to the network num.network.threads=6 # The number of threads that the server uses for processing requests, which may include disk I/O num.io.threads=16 # The send buffer (SO_SNDBUF) used by the socket server socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) socket.request.max.bytes=104857600 #生产数据的配置 #kafka运行日志存放的路径 log.dirs=/home/export/service/kafka-cluster/kafka1/logs num.partitions=3 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. num.recovery.threads.per.data.dir=2 ############################# Internal Topic Settings ############################# # The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state" # For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3. offsets.topic.replication.factor=2 transaction.state.log.replication.factor=2 transaction.state.log.min.isr=2 # The minimum age of a log file to be eligible for deletion due to age log.retention.hours=168 # The maximum size of a log segment file. When this size is reached a new log segment will be created. log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies log.retention.check.interval.ms=300000 #zookeeper的信息 #配置连接zookeeper集群地址 zookeeper.connect=192.168.2.221:2181,192.168.2.241:2181,192.168.2.211:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000 ############################# Group Coordinator Settings ############################# # The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance. # The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms. # The default value for this is 3 seconds. # We override this to 0 here as it makes for a better out-of-the-box experience for development and testing. # However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup. group.initial.rebalance.delay.ms=0 ############################# Socket Server Settings ############################# # The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 listeners=PLAINTEXT://192.168.2.221:9092 host.name=192.168.2.221
7、启动kafka集群(分别启动各实例)
# cd /usr/local/kafka-cluster/kafka1/bin/ # ./kafka-server-start.sh ../config/server.properties # cd /usr/local/kafka-cluster/kafka2/bin/ # ./kafka-server-start.sh ../config/server.properties # cd /usr/local/kafka-cluster/kafka3/bin/ # ./kafka-server-start.sh ../config/server.properties
启动kafka:bin/kafka-server-start.sh -daemon ./config/server.properties &
※ 启动的时候可能会报错"Cannot allocate memory"
这是因为单机上搭建伪集群内存不够导致的,我们可以修改启动脚本,将heap内存改小些,默认为1G,可以改为512M,如果还是不够再修改为256M。
# vi bin/kafka-server-start.sh


8、开放防火墙端口
9092/9093/9094
9、通过命令简单体验一下kafka
创建一个topic,我们实现生产者向topic写数据,消费者从topic拿数据。 首先进入到bin目录下, # cd kafka1/bin/ ① 创建一个topic # ./kafka-topics.sh --create --zookeeper 172.17.80.219:2181 --replication-factor 2 --partitions 2 --topic first # 参数解释 # 172.17.80.219:2181 ZK的服务IP:端口号 # --replication-factor 2 分区的副本数为2 # --partitions 2 分区数为2 # --topic first topic的名字是first # cd /usr/local/kafka-cluster/kafka1/logs/ 可以看到,logs下有两个目录:first-0、first-1,这就是我们创建的topic的两个分区(我们定义的分区副本是2,这是分区0和1的其中一个副本)
② 查看有哪些topic
# ./kafka-topics.sh --list --zookeeper 172.17.80.219:2181
③ 查看topic的详细信息
# ./kafka-topics.sh -zookeeper 172.17.80.219:2181 -describe -topic first
结果解释: 第1行表示:topic的名字、分区数、每个分区的副本数; 第2和第3行,每行表示一个分区的信息,以第2行为例, Topic: first Partition: 0 Leader: 2 Replicas: 2,0 Isr: 2,0 表示topic为first,0号分区,Replicas表示分区的副本分别在broker.id为0和2的机器上, Leader表示分区的leader在broker.id=2的实例上,Isr是在投票选举的时候用的,哪个分区副本的数据和leader数据越接近,这个分区所在的broker.id就越靠前,当leader挂掉时,就取Isr中最靠前的一个broker来顶替leader。
④ 发送消息(连的是kafka的broker)
# ./kafka-console-producer.sh --broker-list 172.17.80.219:9092 --topic first
参数解释:172.17.80.219:9092 Kafka服务IP:端口 说明:我们知道,kafka集群中,只有leader负责读和写,其他flower节点只同步信息,不提供服务,在leader宕机时,flower会顶替leader,继续向外提供服务。我们发送消息的时候,如果指定的结点是flower,flower会将该请求转发到leader。
⑤ 另开一个窗口启动消费者
# ./kafka-console-consumer.sh --zookeeper 172.17.80.219:2181 --from-beginning --topic first【0.8版本以前的写法,现在推荐下面那种写法】
# ./kafka-console-consumer.sh --bootstrap-server 172.17.80.219:9092 --from-beginning --topic first
※ 在生产端输入一些字符,可以在消费端看到已获取到这些字符
说明:新版的kafka消费者在消费的时候,使用的是--bootstrap-server,不再是--zookeeper,这是因为在0.8版本以前,offset维护在zookeeper中,而数据维护在kafka broker中,所以消费者在读取数据的时候先要和zookeeper通信获取到offset,然后再和broker通信去获取数据。但是在0.8版本以后,kafka将offset维护到了kafka的broker中,kafka会自动创建一个topic:"_consumer_offsets"来保存offset的信息,消费者在消费的时候只需要和broker进行一次通信,从而提高了效率。
⑥ 删除topic
# ./kafka-topics.sh --zookeeper 172.17.80.219:2181 --delete --topic first
作者:南辞、归
本博客所有文章仅用于学习、研究和交流目的,欢迎非商业性质转载。
博主的文章没有高度、深度和广度,只是凑字数。由于博主的水平不高,不足和错误之处在所难免,希望大家能够批评指出。
博主是利用读书、参考、引用、抄袭、复制和粘贴等多种方式打造成自己的文章,请原谅博主成为一个无耻的文档搬运工!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号