
【TensorFlow】TensorFlow入门:第一个机器学习Demo
本文主要通过一个简单的 Demo 介绍 TensorFlow 初级 API 的使用方法,因为自己也是初学者,因此本文的目的主要是引导刚接触 TensorFlow 或者 机器学习的同学,能够从第一步开始学习 TensorFlow。阅读本文先确认具备以下基础技能:
- 会使用 Python 编程(初级就OK,其实 TensorFlow 也支持 Java、C++、Go)
- 一些数组相关的知识(线性代数没忘干净就行)
- 最好再懂点机器学习相关的知识(临时百度、Google也来得及)
基础知识
张量(Tensor)
TensorFlow 内部的计算都是基于张量的,因此我们有必要先对张量有个认识。张量是在我们熟悉的标量、向量之上定义的,详细的定义比较复杂,我们可以先简单的将它理解为一个多维数组:
3 # 这个 0 阶张量就是标量,shape=[]
[1., 2., 3.] # 这个 1 阶张量就是向量,shape=[3]
[[1., 2., 3.], [4., 5., 6.]] # 这个 2 阶张量就是二维数组,shape=[2, 3]
[[[1., 2., 3.]], [[7., 8., 9.]]] # 这个 3 阶张量就是三维数组,shape=[2, 1, 3]
- 1
- 2
- 3
- 4
TensorFlow 内部使用tf.Tensor类的实例来表示张量,每个 tf.Tensor有两个属性:
- dtype Tensor 存储的数据的类型,可以为
tf.float32、tf.int32、tf.string… - shape Tensor 存储的多维数组中每个维度的数组中元素的个数,如上面例子中的shape
我们现在可以敲几行代码看一下 Tensor 。在命令终端输入 python 或者 python3 启动一个 Python 会话,然后输入下面的代码:
# 引入 tensorflow 模块
import tensorflow as tf
# 创建一个整型常量,即 0 阶 Tensor
t0 = tf.constant(3, dtype=tf.int32)
# 创建一个浮点数的一维数组,即 1 阶 Tensor
t1 = tf.constant([3., 4.1, 5.2], dtype=tf.float32)
# 创建一个字符串的2x2数组,即 2 阶 Tensor
t2 = tf.constant([['Apple', 'Orange'], ['Potato', 'Tomato']], dtype=tf.string)
# 创建一个 2x3x1 数组,即 3 阶张量,数据类型默认为整型
t3 = tf.constant([[[5], [6], [7]], [[4], [3], [2]]])
# 打印上面创建的几个 Tensor
print(t0)
print(t1)
print(t2)
print(t3)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
上面代码的输出为,注意shape的类型:
>>> print(t0)
Tensor("Const:0", shape=(), dtype=int32)
>>> print(t1)
Tensor("Const_1:0", shape=(3,), dtype=float32)
>>> print(t2)
Tensor("Const_2:0", shape=(2, 2), dtype=string)
>>> print(t3)
Tensor("Const_3:0", shape=(2, 3, 1), dtype=int32)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
print 一个 Tensor 只能打印出它的属性定义,并不能打印出它的值,要想查看一个 Tensor 中的值还需要经过Session 运行一下:
>>> sess = tf.Session()
>>> print(sess.run(t0))
3
>>> print(sess.run(t1))
[ 3. 4.0999999 5.19999981]
>>> print(sess.run(t2))
[[b'Apple' b'Orange']
[b'Potato' b'Tomato']]
>>> print(sess.run(t3))
[[[5]
[6]
[7]]
[[4]
[3]
[2]]]
>>>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
数据流图(Dataflow Graph)
数据流是一种常用的并行计算编程模型,数据流图是由节点(nodes)和线(edges)构成的有向图:
- 节点(nodes) 表示计算单元,也可以是输入的起点或者输出的终点
- 线(edges) 表示节点之间的输入/输出关系
在 TensorFlow 中,每个节点都是用 tf.Tensor的实例来表示的,即每个节点的输入、输出都是Tensor,如下图中 Tensor 在 Graph 中的流动,形象的展示 TensorFlow 名字的由来
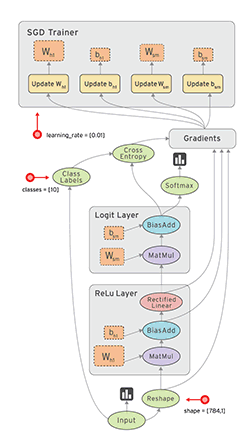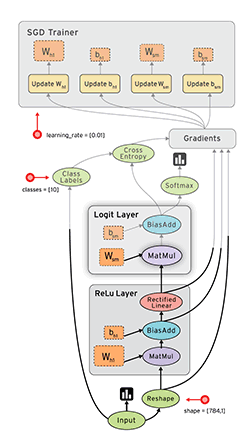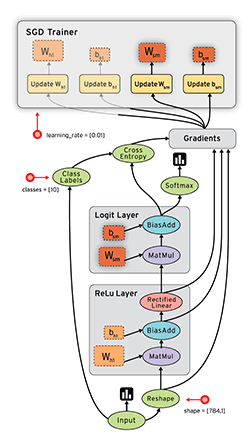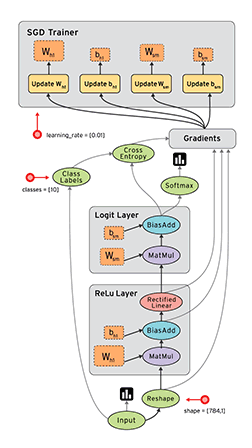
TensorFlow 中的数据流图有以下几个优点:
- 可并行 计算节点之间有明确的线进行连接,系统可以很容易的判断出哪些计算操作可以并行执行
- 可分发 图中的各个节点可以分布在不同的计算单元(CPU、 GPU、 TPU等)或者不同的机器中,每个节点产生的数据可以通过明确的线发送的下一个节点中
- 可优化 TensorFlow 中的 XLA 编译器可以根据数据流图进行代码优化,加快运行速度
- 可移植 数据流图的信息可以不依赖代码进行保存,如使用Python创建的图,经过保存后可以在C++或Java中使用
Sesssion
我们在Python中需要做一些计算操作时一般会使用NumPy,NumPy在做矩阵操作等复杂的计算的时候会使用其他语言(C/C++)来实现这些计算逻辑,来保证计算的高效性。但是频繁的在多个编程语言间切换也会有一定的耗时,如果只是单机操作这些耗时可能会忽略不计,但是如果在分布式并行计算中,计算操作可能分布在不同的CPU、GPU甚至不同的机器中,这些耗时可能会比较严重。
TensorFlow 底层是使用C++实现,这样可以保证计算效率,并使用 tf.Session类来连接客户端程序与C++运行时。上层的Python、



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 全程不用写代码,我用AI程序员写了一个飞机大战
· DeepSeek 开源周回顾「GitHub 热点速览」
· 记一次.NET内存居高不下排查解决与启示
· 物流快递公司核心技术能力-地址解析分单基础技术分享
· .NET 10首个预览版发布:重大改进与新特性概览!