

【守护】“实时”远程监控进程/服务器/数据库运行状态并MQTT推送消息到客户端
借助mosquitto“实时”远程监控服务器数据库运行状态
公司的项目还处于开发阶段,我把整个后台服务临时放在阿里云上供前端测试,用的阿里云的ECS云服务器,HTTP请求服务器和数据库服务都安装在一台机子上(穷啊,凑合用),做测试用,配置相当低:单核1Gb。其实我对服务器多大配置能承受多大访问压力并没有多大概念。前不久使用Jmeter进行http接口性能测试,发现短时间内访问量比较大时,总是会请求错误,根据返回的结果提示是数据库错误,查看一下数据库状态,果真数据库宕机了。
service mysqld status
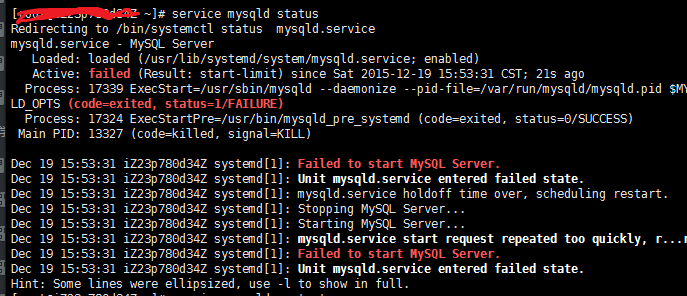
只要数据库服务崩溃了,后面的请求就都会出错,所以想用一种方法来监控服务器数据库服务的状态。自己想了几种方案,大致分为两类
1.当有请求到来时,如果发生数据库连接错误,就(通过邮件或者短息)推送信息给管理员,管理员手动去重启数据库服务。
2.在系统中设置一个定时任务,每隔一段时间检查一次数据库服务状态,如果服务停了就重启并通知管理员。
这里介绍的是第二种方法,主要通过shell脚本实现,下面具体说明如何实现。
首先检测Mysql的状态
#!/bin/bashpgrep -x mysqld &> /dev/nullif [ $? -ne 0 ]thenecho "At time: `date` :MySQL is stop .">> /var/log/mysql_messagesservice mysql start#echo "At time: `date` :MySQL server is stop."elseecho "MySQL server is running ."fi
将上述脚本保存到mysql.sh中,上传到服务器,运行该脚本可以发现输出数据库服务正在运行
# sh mysql.shMySQL server is running
这里我还出现一个小插曲,就是shell脚本总是运行错误,可以参考下面。原来是windows系统和类Unix系统的换行符不一样。
shell编程报错:“syntax error near unexpected token `” - xyp84的专栏 - 博客频道 - CSDN.NET
解决方法参考下面任意一个就行了:
Notepad++中Windows,Unix,Mac三种格式之间的转换 - 如月王子的个人空间 - 开源中国社区
dos格式的文件转换为unix格式 - leipei - 博客园
如果是用sublime编辑器还可以参考
Sublime Text2 默认语言格式(windows/unix)设置,快捷键 - 鸿网互联[68IDC.CN]
脚本如果还执行不了的可能性是文件没有执行权限
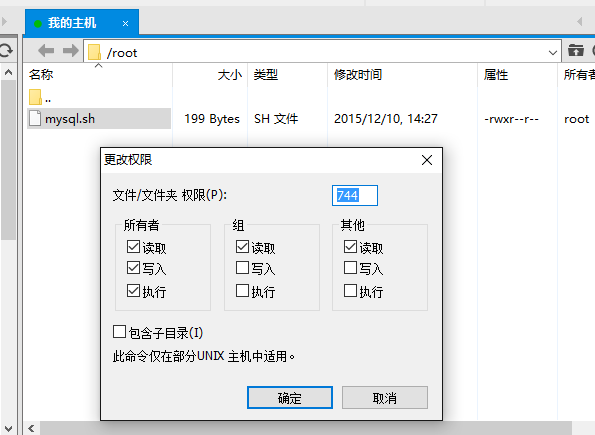
每隔一定时间自动运行脚本
linux上定期执行脚本用的是cron进程
命令:
-
crontab -e
输入(如果不能输入,按键盘上的Insert键就能输入了)*/5 * * * * /your_dir/mysql.sh
*/5表示分钟能被5整除,及每5分钟执行一次,后面4个*号,分别表示 小时,日,月,星期。
编辑完毕,按ESC键退出,输入:wq保存后退出。
重启cron就可以了
-
service cron restart
这样就会每隔5分钟,执行一次检测mysql的脚本。
使用上面的shell脚本并不会推送数据库状态消息给管理员,这里就要借助我以前写的一篇博客了。
Centos7-mqtt消息中间件mosquitto的安装和配置
借助mosquitto服务可以将消息推送到管理员客户端。
#!/bin/bashpgrep -x mysqld &> /dev/nullif [ $? -ne 0 ]thenmosquitto_pub -t mysql_status -m "Failed"service mysql start#echo "At time: `date` :MySQL server is stop."elsemosquitto_pub -t mysql_status -m "Running"fi
服务器发布主题为“mysql_status”的消息,再使用客户端来接收该消息。
import paho.mqtt.client as mqtt# The callback for when the client receives a CONNACK response from the server.def on_connect(client, userdata, flags, rc):print("Connected with result code "+str(rc))# Subscribing in on_connect() means that if we lose the connection and# reconnect then subscriptions will be renewed.client.subscribe("mysql_status")#订阅,第一个参数是订阅的主题# The callback for when a PUBLISH message is received from the server.def on_message(client, userdata, msg):print(msg.topic+" "+str(msg.payload))client = mqtt.Client()client.on_connect = on_connectclient.on_message = on_messageclient.connect("主机名或ip", 1883, 60)#第一个参数为主机名,及Mosquitto所在服务器,第二个参数是端口# Blocking call that processes network traffic, dispatches callbacks and# handles reconnecting.# Other loop*() functions are available that give a threaded interface and a# manual interface.client.loop_forever()
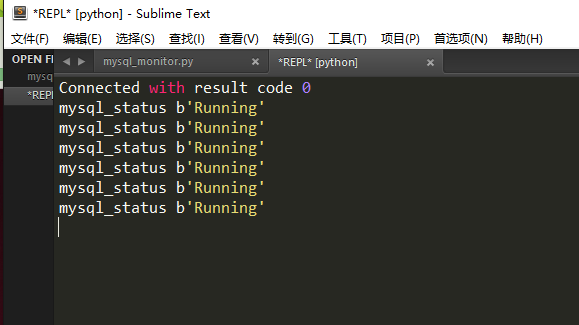
参考:
shell脚本:监控MySQL服务是否正常_数据库技术_Linux公社-Linux系统门户网站
Linux进程状态解析 之 R、S、D、T、Z、X (主要有三个状态)
Linux是一个多用户,多任务的系统,可以同时运行多个用户的多个程序,就必然会产生很多的进程,而每个进程会有不同的状态。
Linux进程状态:R (TASK_RUNNING),可执行状态。
只有在该状态的进程才可能在CPU上运行。而同一时刻可能有多个进程处于可执行状态,这些进程的task_struct结构(进程控制块)被放入对应CPU的可执行队列中(一个进程最多只能出现在一个CPU的可执行队列中)。进程调度器的任务就是从各个CPU的可执行队列中分别选择一个进程在该CPU上运行。
很多操作系统教科书将正在CPU上执行的进程定义为RUNNING状态、而将可执行但是尚未被调度执行的进程定义为READY状态,这两种状态在linux下统一为 TASK_RUNNING状态。
Linux进程状态:S (TASK_INTERRUPTIBLE),可中断的睡眠状态。
处于这个状态的进程因为等待某某事件的发生(比如等待socket连接、等待信号量),而被挂起。这些进程的task_struct结构被放入对应事件的等待队列中。当这些事件发生时(由外部中断触发、或由其他进程触发),对应的等待队列中的一个或多个进程将被唤醒。
通过ps命令我们会看到,一般情况下,进程列表中的绝大多数进程都处于TASK_INTERRUPTIBLE状态(除非机器的负载很高)。毕竟CPU就这么一两个,进程动辄几十上百个,如果不是绝大多数进程都在睡眠,CPU又怎么响应得过来。
Linux进程状态:D (TASK_UNINTERRUPTIBLE),不可中断的睡眠状态。
与TASK_INTERRUPTIBLE状态类似,进程处于睡眠状态,但是此刻进程是不可中断的。不可中断,指的并不是CPU不响应外部硬件的中断,而是指进程不响应异步信号。
绝大多数情况下,进程处在睡眠状态时,总是应该能够响应异步信号的。否则你将惊奇的发现,kill -9竟然杀不死一个正在睡眠的进程了!于是我们也很好理解,为什么ps命令看到的进程几乎不会出现TASK_UNINTERRUPTIBLE状态,而总是TASK_INTERRUPTIBLE状态。
而TASK_UNINTERRUPTIBLE状态存在的意义就在于,内核的某些处理流程是不能被打断的。如果响应异步信号,程序的执行流程中就会被插入一段用于处理异步信号的流程(这个插入的流程可能只存在于内核态,也可能延伸到用户态),于是原有的流程就被中断了。(参见《linux内核异步中断浅析》)
在进程对某些硬件进行操作时(比如进程调用read系统调用对某个设备文件进行读操作,而read系统调用最终执行到对应设备驱动的代码,并与对应的物理设备进行交互),可能需要使用TASK_UNINTERRUPTIBLE状态对进程进行保护,以避免进程与设备交互的过程被打断,造成设备陷入不可控的状态。这种情况下的TASK_UNINTERRUPTIBLE状态总是非常短暂的,通过ps命令基本上不可能捕捉到。
linux系统中也存在容易捕捉的TASK_UNINTERRUPTIBLE状态。执行vfork系统调用后,父进程将进入TASK_UNINTERRUPTIBLE状态,直到子进程调用exit或exec(参见《神奇的vfork》)。
通过下面的代码就能得到处于TASK_UNINTERRUPTIBLE状态的进程:
#include void main() { if (!vfork()) sleep(100); }
编译运行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out 4371 pts/0 D+ 0:00 ./a.out 4372 pts/0 S+ 0:00 ./a.out 4374 pts/1 S+ 0:00 grep a.out
然后我们可以试验一下TASK_UNINTERRUPTIBLE状态的威力。不管kill还是kill -9,这个TASK_UNINTERRUPTIBLE状态的父进程依然屹立不倒。
上面我们介绍了Linux进程的R、S、D三种状态,这里接着上面的文章介绍另外三个状态。
Linux进程状态:T (TASK_STOPPED or TASK_TRACED),暂停状态或跟踪状态。
向进程发送一个SIGSTOP信号,它就会因响应该信号而进入TASK_STOPPED状态(除非该进程本身处于TASK_UNINTERRUPTIBLE状态而不响应信号)。(SIGSTOP与SIGKILL信号一样,是非常强制的。不允许用户进程通过signal系列的系统调用重新设置对应的信号处理函数。)
向进程发送一个SIGCONT信号,可以让其从TASK_STOPPED状态恢复到TASK_RUNNING状态。
当进程正在被跟踪时,它处于TASK_TRACED这个特殊的状态。“正在被跟踪”指的是进程暂停下来,等待跟踪它的进程对它进行操作。比如在gdb中对被跟踪的进程下一个断点,进程在断点处停下来的时候就处于TASK_TRACED状态。而在其他时候,被跟踪的进程还是处于前面提到的那些状态。
对于进程本身来说,TASK_STOPPED和TASK_TRACED状态很类似,都是表示进程暂停下来。
而TASK_TRACED状态相当于在TASK_STOPPED之上多了一层保护,处于TASK_TRACED状态的进程不能响应SIGCONT信号而被唤醒。只能等到调试进程通过ptrace系统调用执行PTRACE_CONT、PTRACE_DETACH等操作(通过ptrace系统调用的参数指定操作),或调试进程退出,被调试的进程才能恢复TASK_RUNNING状态。
Linux进程状态:Z (TASK_DEAD - EXIT_ZOMBIE),退出状态,进程成为僵尸进程。
进程在退出的过程中,处于TASK_DEAD状态。
在这个退出过程中,进程占有的所有资源将被回收,除了task_struct结构(以及少数资源)以外。于是进程就只剩下task_struct这么个空壳,故称为僵尸。
之所以保留task_struct,是因为task_struct里面保存了进程的退出码、以及一些统计信息。而其父进程很可能会关心这些信息。比如在shell中,$?变量就保存了最后一个退出的前台进程的退出码,而这个退出码往往被作为if语句的判断条件。
当然,内核也可以将这些信息保存在别的地方,而将task_struct结构释放掉,以节省一些空间。但是使用task_struct结构更为方便,因为在内核中已经建立了从pid到task_struct查找关系,还有进程间的父子关系。释放掉task_struct,则需要建立一些新的数据结构,以便让父进程找到它的子进程的退出信息。
父进程可以通过wait系列的系统调用(如wait4、waitid)来等待某个或某些子进程的退出,并获取它的退出信息。然后wait系列的系统调用会顺便将子进程的尸体(task_struct)也释放掉。
子进程在退出的过程中,内核会给其父进程发送一个信号,通知父进程来“收尸”。这个信号默认是SIGCHLD,但是在通过clone系统调用创建子进程时,可以设置这个信号。
通过下面的代码能够制造一个EXIT_ZOMBIE状态的进程:
#include void main() { if (fork()) while(1) sleep(100); }
编译运行,然后ps一下:
kouu@kouu-one:~/test$ ps -ax | grep a\.out 10410 pts/0 S+ 0:00 ./a.out 10411 pts/0 Z+ 0:00 [a.out] 10413 pts/1 S+ 0:00 grep a.out
只要父进程不退出,这个僵尸状态的子进程就一直存在。那么如果父进程退出了呢,谁又来给子进程“收尸”?
当进程退出的时候,会将它的所有子进程都托管给别的进程(使之成为别的进程的子进程)。托管给谁呢?可能是退出进程所在进程组的下一个进程(如果存在的话),或者是1号进程。所以每个进程、每时每刻都有父进程存在。除非它是1号进程。
1号进程,pid为1的进程,又称init进程。
linux系统启动后,第一个被创建的用户态进程就是init进程。它有两项使命:
1、执行系统初始化脚本,创建一系列的进程(它们都是init进程的子孙);
2、在一个死循环中等待其子进程的退出事件,并调用waitid系统调用来完成“收尸”工作;
init进程不会被暂停、也不会被杀死(这是由内核来保证的)。它在等待子进程退出的过程中处于TASK_INTERRUPTIBLE状态,“收尸”过程中则处于TASK_RUNNING状态。
Linux进程状态:X (TASK_DEAD - EXIT_DEAD),退出状态,进程即将被销毁。
而进程在退出过程中也可能不会保留它的task_struct。比如这个进程是多线程程序中被detach过的进程(进程?线程?参见《linux线程浅析》)。或者父进程通过设置SIGCHLD信号的handler为SIG_IGN,显式的忽略了SIGCHLD信号。(这是posix的规定,尽管子进程的退出信号可以被设置为SIGCHLD以外的其他信号。)
此时,进程将被置于EXIT_DEAD退出状态,这意味着接下来的代码立即就会将该进程彻底释放。所以EXIT_DEAD状态是非常短暂的,几乎不可能通过ps命令捕捉到。
进程的初始状态
进程是通过fork系列的系统调用(fork、clone、vfork)来创建的,内核(或内核模块)也可以通过kernel_thread函数创建内核进程。这些创建子进程的函数本质上都完成了相同的功能——将调用进程复制一份,得到子进程。(可以通过选项参数来决定各种资源是共享、还是私有。)
那么既然调用进程处于TASK_RUNNING状态(否则,它若不是正在运行,又怎么进行调用?),则子进程默认也处于TASK_RUNNING状态。
另外,在系统调用调用clone和内核函数kernel_thread也接受CLONE_STOPPED选项,从而将子进程的初始状态置为 TASK_STOPPED。
进程状态变迁
进程自创建以后,状态可能发生一系列的变化,直到进程退出。而尽管进程状态有好几种,但是进程状态的变迁却只有两个方向——从TASK_RUNNING状态变为非TASK_RUNNING状态、或者从非TASK_RUNNING状态变为TASK_RUNNING状态。
也就是说,如果给一个TASK_INTERRUPTIBLE状态的进程发送SIGKILL信号,这个进程将先被唤醒(进入TASK_RUNNING状态),然后再响应SIGKILL信号而退出(变为TASK_DEAD状态)。并不会从TASK_INTERRUPTIBLE状态直接退出。
进程从非TASK_RUNNING状态变为TASK_RUNNING状态,是由别的进程(也可能是中断处理程序)执行唤醒操作来实现的。执行唤醒的进程设置被唤醒进程的状态为TASK_RUNNING,然后将其task_struct结构加入到某个CPU的可执行队列中。于是被唤醒的进程将有机会被调度执行。
而进程从TASK_RUNNING状态变为非TASK_RUNNING状态,则有两种途径:
1、响应信号而进入TASK_STOPED状态、或TASK_DEAD状态;
2、执行系统调用主动进入TASK_INTERRUPTIBLE状态(如nanosleep系统调用)、或TASK_DEAD状态(如exit系统调用);或由于执行系统调用需要的资源得不到满足,而进入TASK_INTERRUPTIBLE状态或TASK_UNINTERRUPTIBLE状态(如select系统调用)。
显然,这两种情况都只能发生在进程正在CPU上执行的情况下。
---------------------
原文:https://blog.csdn.net/sdkdlwk/article/details/65938204
在Linux中,如何找到并杀掉僵尸进程?
如果你经常使用 Linux,你应该遇到这个术语“僵尸进程Zombie Processes”。 那么什么是僵尸进程? 它们是怎么产生的? 它们是否对系统有害? 我要怎样杀掉这些进程? 下面将会回答这些问题。
什么是僵尸进程?
我们都知道进程的工作原理。我们启动一个程序,开始我们的任务,然后等任务结束了,我们就停止这个进程。 进程停止后, 该进程就会从进程表中移除。
你可以通过 System-Monitor 查看当前进程。

但是,有时候有些程序即使执行完了也依然留在进程表中。
那么,这些完成了生命周期但却依然留在进程表中的进程,我们称之为 “僵尸进程”。
它们是如何产生的?
当你运行一个程序时,它会产生一个父进程以及很多子进程。 所有这些子进程都会消耗内核分配给它们的内存和 CPU 资源。
这些子进程完成执行后会发送一个 Exit 信号然后死掉。这个 Exit 信号需要被父进程所读取。父进程需要随后调用 wait 命令来读取子进程的退出状态,并将子进程从进程表中移除。
若父进程正确第读取了子进程的 Exit 信号,则子进程会从进程表中删掉。
但若父进程未能读取到子进程的 Exit 信号,则这个子进程虽然完成执行处于死亡的状态,但也不会从进程表中删掉。
僵尸进程对系统有害吗?
不会。由于僵尸进程并不做任何事情, 不会使用任何资源也不会影响其它进程, 因此存在僵尸进程也没什么坏处。 不过由于进程表中的退出状态以及其它一些进程信息也是存储在内存中的,因此存在太多僵尸进程有时也会是一些问题。
你可以想象成这样:
“你是一家建筑公司的老板。你每天根据工人们的工作量来支付工资。 有一个工人每天来到施工现场,就坐在那里, 你不用付钱, 他也不做任何工作。 他只是每天都来然后呆坐在那,仅此而已!”
这个工人就是僵尸进程的一个活生生的例子。但是, 如果你有很多僵尸工人, 你的建设工地就会很拥堵从而让那些正常的工人难以工作。
那么如何找出僵尸进程呢?
打开终端并输入下面命令:
ps aux | grep Z
会列出进程表中所有僵尸进程的详细内容。
如何杀掉僵尸进程?
正常情况下我们可以用 SIGKILL 信号来杀死进程,但是僵尸进程已经死了, 你不能杀死已经死掉的东西。 因此你需要输入的命令应该是
kill -s SIGCHLD pid
将这里的 pid 替换成父进程的进程 id,这样父进程就会删除所有以及完成并死掉的子进程了。
你可以把它想象成:
“你在道路中间发现一具尸体,于是你联系了死者的家属,随后他们就会将尸体带离道路了。”
不过许多程序写的不是那么好,无法删掉这些子僵尸(否则你一开始也见不到这些僵尸了)。 因此确保删除子僵尸的唯一方法就是杀掉它们的父进程。
linux下c创建僵尸进程、查看僵尸进程、杀死僵尸进程
僵尸进程(Zombie process)通俗来说指那些虽然已经终止的进程,但仍然保留一些信息,等待其父进程为其收尸。也就是说父进程没有结束,但是子进程结束了,父进程没死,没办法给子进程收尸,真的是只有父进程死了才能收尸,哈哈,同时也没有显示的调用wait/waitpid给其子进程收尸。当然,父进程提前死亡,子进程会交给init进程,所以收尸的问题就交给init进程了。百度百科的僵尸进程说的很好,可以看一下!
一,在linux下生成一个僵尸进程的c代码
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <signal.h>
#include <linux/wait.h>
int main(int argc,char **argv)
{
int i=0;
pid_t pid=fork();
if(pid==-1) return 0;
else if(pid==0)
{
printf("son pid is %d\n",getpid());
while(1)
{
printf("son---i=%d\n",i);
i++;
sleep(1);
if(i==5)
break;
}
printf("son is over!\n");
}else if(pid>0)
{
printf("parent pid is %d\n",getpid());
while(1) sleep(100);
}
return 0;
}
这样就是在子进程已经结束,但是父进程永远也不会结束,也没有调用wait/waitpid。那么子进程就成为僵尸进程。
编译,gcc makeDefunct.c -o makeDefunct
我的文件名是makeDefunct.c 运行./makeDefunct
二、如何查看僵尸进程
可以利用top命令,效果如下,上文中创建的僵尸进程
可以发现我的服务器下只有一个僵尸进程。
也可以用 ps -aux |grep Z 来查看僵尸进程,效果如下:
僵尸进程的状态显示的是Z
三、如何杀死僵尸进程
从僵尸进程的概念可以看出,父进程没有结束导致的,我们把父进程杀死,父进程就会寻找他自己创建的子进程,从而杀死僵尸进程。所以我们要杀死父进程就可以。所以第一步要找到父进程 ps -ef | grep defunct_process_pid(僵尸进程pid) 然后执行,kill -s 9 父进程的pid。演示如下:
可以看出,先找到僵尸进程的pid,我这里使用ps -aux |grep make 是因为我的c文件是make开头的。然后在找到僵尸进程的父进程的pid 11781
然后杀死 kill -s 9 11781
检查一下是否杀死了僵尸进程
执行top后得到的结果如下图:
没有僵尸进程了已经被杀死了。
---------------------
原文:https://blog.csdn.net/u011123091/article/details/81220827



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· TypeScript + Deepseek 打造卜卦网站:技术与玄学的结合
· 阿里巴巴 QwQ-32B真的超越了 DeepSeek R-1吗?
· 【译】Visual Studio 中新的强大生产力特性
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 【设计模式】告别冗长if-else语句:使用策略模式优化代码结构