

【C++11】线程池 简单实现
适合应用线程池的场合
线程分为三个过程:T1、T2、T3。
T1:线程创建时间
T2:线程执行时间,包括线程的同步等时间
T3:线程销毁时间
线程本身的开销所占的比例为(T1+T3) / (T1+T2+T3)。如果线程执行的时间很短的话,开销可能占到20%-50%左右。如果任务执行时间很长的话,这笔开销将是不可忽略的。
除此之外,线程池能够减少创建的线程个数。因此线程池的出现正是着眼于减少线程本身带来的开销。线程池采用预创建的技术。
对于FTP服务器以及Telnet服务器,通常传送文件的时间较长,开销较大,那么此时,我们采用线程池未必是理想的方法,我们可以选择“即时创建,即时销毁”的策略。
总之线程池通常适合下面的几个场合:
(1)单位时间内处理任务频繁而且任务处理时间短
(2)对实时性要求较高。如果接受到任务后在创建线程,可能满足不了实时要求,因此必须采用线程池进行预创建。
最简单的线程池实现
ThreadPool.h
#pragma once
#include <iostream>
#include<stdlib.h>
#include<thread>
#include<mutex>
#include<condition_variable>
#include<vector>
#include<functional>
#include<queue>
#define N 10
using namespace std;
class ThreadPool{
public:
//自定义void()的函数类型
typedef function<void()>Task;
ThreadPool();
~ThreadPool();
public:
size_t initnum;
//线程数组
vector<thread>threads ;
//任务队列
queue<Task>task ;
//互斥锁条件变量
mutex _mutex ;
condition_variable cond ;
//线程池是否处于停止
bool stop ;
//队列是否为空
bool isEmpty ;
//队列是否为满
bool isFull;
public:
void addTask(const Task&f);
void start(int num);
void setSize(int num);
void worker();
void join();
};
ThreadPool.cpp
#include"ThreadPool.h"
ThreadPool ::ThreadPool(): stop(false), isEmpty(true), isFull(false)
{
}
//设置池中初始线程数
void ThreadPool::setSize(int num)
{
(*this).initnum = num ;
}
//添加任务
void ThreadPool::addTask(const Task &f)
{
if(!stop)
{
//保护共享资源
unique_lock<mutex>lk(_mutex);
//要是任务数量到了最大,就等待处理完再添加
while(isFull)
{
cond.wait(lk);
}
//给队列中添加任务
task.push(f);
if(task.size() == initnum)
isFull = true;
cout << "Add a task" << endl;
isEmpty = false ;
cond.notify_one();
}
}
void ThreadPool::join()
{
//线程池结束工作
for(size_t i = 0 ; i < threads.size(); i++)
{
threads[i].join() ;
}
}
void ThreadPool::worker()
{
//不断遍历队列,判断要是有任务的话,就执行
while(!stop)
{
unique_lock<mutex>lk(_mutex);
//队列为空的话,就等待任务
while(isEmpty)
{
cond.wait(lk);
}
Task ta ;
//转移控制快,将左值引用转换为右值引用
ta = move(task.front());
task.pop();
if(task.empty())
{
isEmpty = true ;
}
isFull = false ;
ta();
cond.notify_one();
}
}
void ThreadPool::start(int num)
{
setSize(num);
for(int i = 0; i < num; i++)
{
threads.push_back(thread(&ThreadPool::worker, this));
}
}
ThreadPool::~ThreadPool()
{
}
join的必要:
举个例子,现在有 A, B, C 三件事情,只有做完 A 和 B 才能去做 C,而 A 和 B 可以并行完成。
int main(){
thread t = new thread(A);
B(); // 此时 A 与 B 并行进行
t.join(); // 确保 A 完成
C();
}Test.cpp
#include <iostream>
#include"ThreadPool.h"
void func(int i){
cout<<"task finish"<<"------>"<<i<<endl;
}
int main()
{
ThreadPool p ;
p.start(N);
int i=0;
while(1){
i++;
//调整线程之间cpu调度,可以去掉
this_thread::sleep_for(chrono::seconds(1));
auto task = bind(func,i);
p.addTask(task);
}
p.finish();
return 0;
}
简单的makefile
CC = g++
CXXFLAGS=-lpthread -g
target:Test.cpp ThreadPool.o
$(CC) Test.cpp ThreadPool.o -o Test $(CXXFLAGS)
ThreadPool.o:ThreadPool.cpp
$(CC) -c ThreadPool.cpp $(CXXFLAGS)
clean:
rm *.o
运行截图
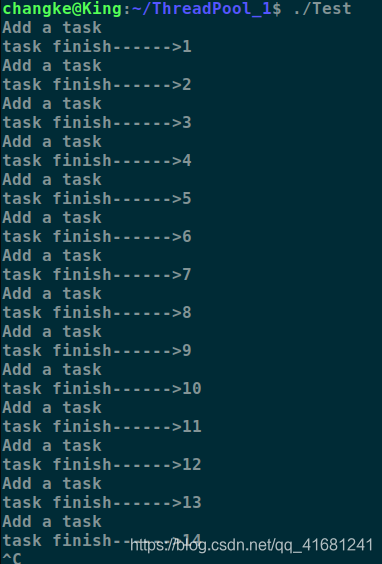
原文链接:https://blog.csdn.net/qq_41681241/article/details/86723964
牛逼的线程池(有返回值)
感谢github上大神的分享:https://github.com/progschj/ThreadPool
线程池代码
代码非常的简洁,只有一个头文件ThreadPool.h,这里贴出来作为备份。
#ifndef TG_THREAD_POOL_H
#define TG_THREAD_POOL_H
#include <vector>
#include <queue>
#include <memory>
#include <thread>
#include <mutex>
#include <condition_variable>
#include <future>
#include <functional>
#include <stdexcept>
class tg_thread_pool
{
public:
tg_thread_pool(size_t);
~tg_thread_pool();
template<class F, class... Args>
auto enqueue(F &&f, Args &&... args) -> std::future<typename
std::result_of<F(Args...)>::type>;
private:
std::vector<std::thread> _threads;
std::queue<std::function<void()>> _que;
std::mutex _mutex;
std::condition_variable _condition;
bool _stop;
};
inline tg_thread_pool::tg_thread_pool(size_t num) : _stop(false)
{
for(size_t i = 0; i < num; ++i)
{
_threads.emplace_back(
[this]
{
for(;;)
{
std::function<void()> task;
{
std::unique_lock<std::mutex> lock(this->_mutex);
this->_condition.wait(lock, [this] { return this->_stop || !this->_que.empty(); });
if(this->_stop && this->_que.empty())
{
return;
}
task = std::move(this->_que.front());
this->_que.pop();
}
task();
}
}
);
}
}
template<class F, class... Args>
auto tg_thread_pool::enqueue(F &&f, Args &&... args)
- > std::future<typename std::result_of<F(Args...)>::type>
{
using return_type = typename std::result_of<F(Args...)>::type;
auto task = std::make_shared< std::packaged_task<return_type()> >(
std::bind(std::forward<F>(f), std::forward<Args>(args)...)
);
std::future<return_type> res = task->get_future();
{
std::unique_lock<std::mutex> lock(_mutex);
if(_stop)
throw std::runtime_error("enqueue on stopped ThreadPool");
_que.emplace([task]()
{
(*task)();
});
}
_condition.notify_one();
return res;
}
inline tg_thread_pool::~tg_thread_pool()
{
{
std::unique_lock<std::mutex> lock(_mutex);
_stop = true;
}
_condition.notify_all();
for(std::thread &worker : _threads)
worker.join();
}
#endif // TG_THREAD_POOL_H基本使用方法
#include <iostream>
#include "./other/tg_thread_pool.h"
void func()
{
std::this_thread::sleep_for(std::chrono::milliseconds(100));
std::cout<<"worker thread ID:"<<std::this_thread::get_id()<<std::endl;
}
int main()
{
tg_thread_pool pool(4);
auto result = pool.enqueue([](int answer) { return answer; }, 42);
std::cout << result.get() << std::endl;//42
for(int i=0;i<10;i++)
{
pool.enqueue(func);
}
return 0;
}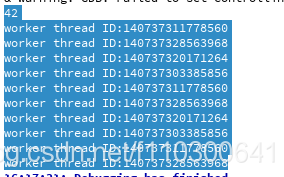
可以看出,四个线程都在运行。
线程池,最简单的就是生产者消费者模型了。池里的每条线程,都是消费者,他们消费并处理一个个的任务,而任务队列就相当于生产者了。
线程池最简单的形式是含有一个固定数量的工作线程来处理任务,典型的数量是std::thread::hardware_concurrency()



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· AI技术革命,工作效率10个最佳AI工具