
【mySQL】MySQL JOIN原理
MySQL JOIN原理
先看一下实验的两张表:
表comments,总行数28856
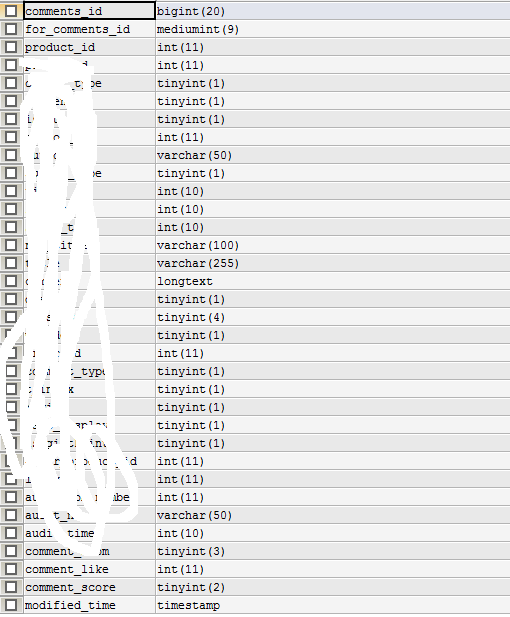
表comments_for,总行数57,comments_id是有索引的,ID列为主键。
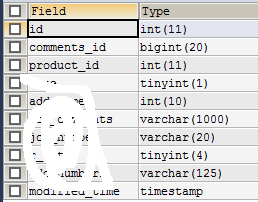
以上两张表是我们测试的基础,然后看一下索引,comments_for这个表comments_id是有索引的,ID为主键。
最近被公司某一开发问道JOIN了MySQL JOIN的问题,细数之下发下我对MySQL JOIN的理解并不是很深刻,所以也查看了很多文档,最后在InsideMySQL公众号看到了两篇关于JOIN的分析,感觉写的太好了,拿出来分享一下我对于JOIN的实际测试吧。下面先介绍一下MySQL关于JOIN的算法,总共分为三种(来源为InsideMySQL):
MySQL是只支持一种JOIN算法Nested-Loop Join(嵌套循环链接),不像其他商业数据库可以支持哈希链接和合并连接,不过MySQL的Nested-Loop Join(嵌套循环链接)也是有很多变种,能够帮助MySQL更高效的执行JOIN操作:
(1)Simple Nested-Loop Join(图片为InsideMySQL取来)
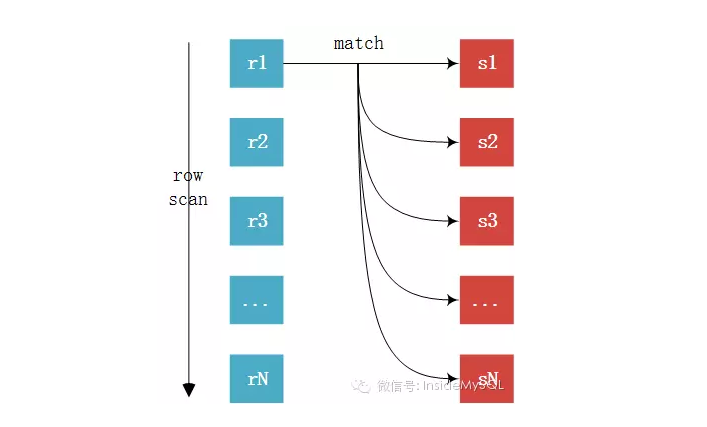
这个算法相对来说就是很简单了,从驱动表中取出R1匹配S表所有列,然后R2,R3,直到将R表中的所有数据匹配完,然后合并数据,可以看到这种算法要对S表进行RN次访问,虽然简单,但是相对来说开销还是太大了
(2)Index Nested-Loop Join,实现方式如下图:
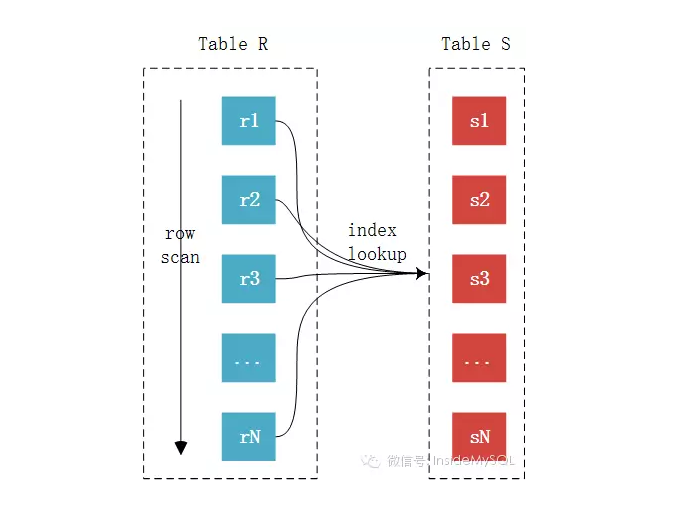
索引嵌套联系由于非驱动表上有索引,所以比较的时候不再需要一条条记录进行比较,而可以通过索引来减少比较,从而加速查询。这也就是平时我们在做关联查询的时候必须要求关联字段有索引的一个主要原因。
这种算法在链接查询的时候,驱动表会根据关联字段的索引进行查找,当在索引上找到了符合的值,再回表进行查询,也就是只有当匹配到索引以后才会进行回表。至于驱动表的选择,MySQL优化器一般情况下是会选择记录数少的作为驱动表,但是当SQL特别复杂的时候不排除会出现错误选择。
在索引嵌套链接的方式下,如果非驱动表的关联键是主键的话,这样来说性能就会非常的高,如果不是主键的话,关联起来如果返回的行数很多的话,效率就会特别的低,因为要多次的回表操作。先关联索引,然后根据二级索引的主键ID进行回表的操作。这样来说的话性能相对就会很差。
(3)Block Nested-Loop Join,实现如下:
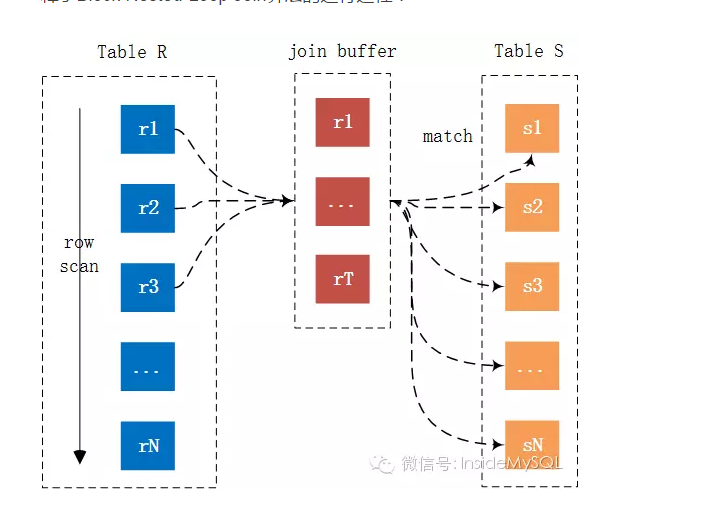
在有索引的情况下,MySQL会尝试去使用Index Nested-Loop Join算法,在有些情况下,可能Join的列就是没有索引,那么这时MySQL的选择绝对不会是最先介绍的Simple Nested-Loop Join算法,而是会优先使用Block Nested-Loop Join的算法。
Block Nested-Loop Join对比Simple Nested-Loop Join多了一个中间处理的过程,也就是join buffer,使用join buffer将驱动表的查询JOIN相关列都给缓冲到了JOIN BUFFER当中,然后批量与非驱动表进行比较,这也来实现的话,可以将多次比较合并到一次,降低了非驱动表的访问频率。也就是只需要访问一次S表。这样来说的话,就不会出现多次访问非驱动表的情况了,也只有这种情况下才会访问join buffer。
在MySQL当中,我们可以通过参数join_buffer_size来设置join buffer的值,然后再进行操作。默认情况下join_buffer_size=256K,在查找的时候MySQL会将所有的需要的列缓存到join buffer当中,包括select的列,而不是仅仅只缓存关联列。在一个有N个JOIN关联的SQL当中会在执行时候分配N-1个join buffer。
上面介绍完了,下面看一下具体的列子
(1)全表JOIN
EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id;
看一下输出信息:

可以看到在全表扫描的时候comments_for 作为了驱动表,此事因为关联字段是有索引的,所以对索引idx_commentsid进行了一个全索引扫描去匹配非驱动表comments ,每次能够匹配到一行。此时使用的就是Index Nested-Loop Join,通过索引进行了全表的匹配,我们可以看到因为comments_for 表的量级远小于comments ,所以说MySQL优先选择了小表comments_for 作为了驱动表。
(2)全表JOIN+筛选条件
SELECT * FROM comments gc JOIN comments_for gcf ON gc.comments_id=gcf.comments_id WHERE gc.comments_id =2056

此时使用的是Index Nested-Loop Join,先对驱动表comments 的主键进行筛选,符合一条,对非驱动表comments_for 的索引idx_commentsid进行seek匹配,最终匹配结果预计为影响一条,这样就是仅仅对非驱动表的idx_commentsid索引进行了一次访问操作,效率相对来说还是非常高的。
(3)看一下关联字段是没有索引的情况:
EXPLAIN SELECT * FROM comments gc JOIN comments_for gcf ON gc.order_id=gcf.product_id
我们看一下执行计划:

从执行计划我们就可以看出,这个表JOIN就是使用了Block Nested-Loop Join来进行表关联,先把comments_for (只有57行)这个小表作为驱动表,然后将comments_for 的需要的数据缓存到JOIN buffer当中,批量对comments 表进行扫描,也就是只进行一次匹配,前提是join buffer足够大能够存下comments_for的缓存数据。
而且我们看到执行计划当中已经很明确的提示:Using where; Using join buffer (Block Nested Loop)
一般情况出现这种情况就证明我们的SQL需要优化了。
要注意的是这种情况下,MySQL也会选择Simple Nested-Loop Join这种暴力的方法,我还没搞懂他这个优化器是怎么选择的,但是一般是使用Block Nested-Loop Join,因为CBO是基于开销的,Block Nested-Loop Join的性能相对于Simple Nested-Loop Join是要好很多的。
(4)看一下left join
EXPLAIN SELECT * FROM comments gc LEFT JOIN comments_for gcf ON gc.comments_id=gcf.comments_id
看一下执行计划:

这种情况,由于我们的关联字段是有索引的,所以说Index Nested-Loop Join,只不过当没有筛选条件的时候会选择第一张表作为驱动表去进行JOIN,去关联非驱动表的索引进行Index Nested-Loop Join。
如果加上筛选条件gc.comments_id =2056的话,这样就会筛选出一条对非驱动表进行Index Nested-Loop Join,这样效率是很高的。
如果是下面这种:
EXPLAIN SELECT * FROM comments_for gcf LEFT JOIN comments gc ON gc.comments_id=gcf.comments_id WHERE gcf.comments_id =2056
通过gcf表进行筛选的话,就会默认选择gcf表作为驱动表,因为很明显他进行过了筛选,匹配的条件会很少,具体可以看下执行计划:
 此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
此,join基本上已经很明了了,未完待续中,欢迎大家指出错误,我会认真改正。。。。
热衷于学习讨论MySQL和SQL Server,NoSQL等数据库技术,欢迎加入SQL优化群:659336691



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· winform 绘制太阳,地球,月球 运作规律
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· AI与.NET技术实操系列(五):向量存储与相似性搜索在 .NET 中的实现
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 超详细:普通电脑也行Windows部署deepseek R1训练数据并当服务器共享给他人