

【linux】随机读写之DirectIO|MMAP和DIRECT IO区别
目录
随机读写之DirectIO
原文:https://blog.csdn.net/alex_xfboy/article/details/91865675
在上一节中讲过MappedByteBuffer VS FileChannel它们称得上零拷贝技术,但留下了顺序读比随机读快,顺序写比随机写快的问题,在我们的实际应用场景中为了回避随机读写需求,通常的做法都是对其进行文件分片(又将随机变成了有序),而本节借助Direct IO来彻底解决该问题。
注:只有 Linux 系统才支持 Direct IO,还被 Linus 喷过,据说在 Jdk10 发布之后将会得到原生支持
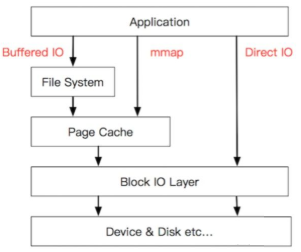
| buffered io | 普通文件操作,对性能、吞吐量没有特殊要求,由kernel通过page cache统一管理缓存,page cache的创建和回收由kernel控制。 默认是异步写,如果使用sync,则是同步写,保证该文件所有的脏页落盘后才返回(对于db transaction很重要,通过sync保证redo log落盘,从而保证一致性) |
| mmap | 对文件操作的吞吐量、性能有一定要求,且对内存使用不敏感,不要求实时落盘的情况下使用。mmap对比buffered io,可以减少一次从page cache -> user space的内存拷贝,大文件场景下能大幅度提升性能。同时mmap将把文件操作转换为内存操作,避免lseek。通过msync回写硬盘(此处只说IO相关的应用,抛开进程内存共享等应用)。 |
| direct io | 性能要求较高、内存使用率也要求较高的情况下使用。 适合DB场景,DB会将数据缓存在自己的cache中,换入、换出算法由DB控制,因为DB比kernel更了解哪些数据应该换入换出,比如innodb的索引,要求常驻内存,对于redo log不需要重读读写,更不要page cache,直接写入磁盘就好。 |
顺序读写 & 随机读写
定义不难理解,其实就是要有序,不要随机切换位置,比如:
thread1:write position[0~4096)
thread2:write position[4096~8194)
而非
thread1:write position[0~4096)
thread3:write position[8194~12288)
thread2:write position[4096~8194)
ExecutorService executor = Executors.newFixedThreadPool(64);
AtomicLong position = new AtomicLong(0);
//并发写(达到随机写的描述)
for(int i=0;i<1024;i++){
final int index = i;
executor.execute(()->{
fileChannel.write(ByteBuffer.wrap(new byte[4*1024]),position.getAndAdd(4*1024));
})
}
//加锁保证了顺序写
for(int i=0;i<1024;i++){
final int index = i;
executor.execute(()->{
write(new byte[4*1024]);
})
}
public synchronized void write(byte[] data){
fileChannel.write(ByteBuffer.wrap(new byte[4*1024]),position.getAndAdd(4*1024));
}思考:顺序写为什么比随机写要快?
这正是page cache在起作用!
disk cache分为两种:
1)buffer cache以块为单位,缓存裸分区中的内容,(如super block、inode)。
2)page cache是以页为单位缓存分区中文件的内容(通常为4K) ,它是位于 application buffer(用户内存)和 disk file(磁盘)之间的一层缓存。
linux2.4中,两者是并存的,但会造成mmap情况下,同一份数据会在两个cache空间内存在,造成空间浪费,在linux2.6中,两者合并,buffer cache也使用page cache的数据结构,只是在free统计内存时,会把page cache中缓存裸分区的部分统计为buffer cache。
当用户发起一个 fileChannel.read(4kb) 时:
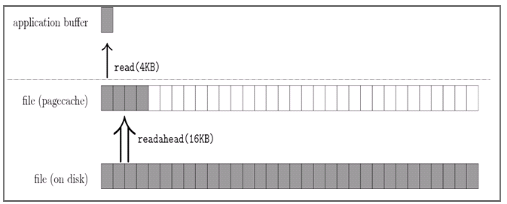
- 操作系统从磁盘加载了磁盘块(block) 16kb进入 PageCache,这被称为预读(为了减少实际磁盘IO)
- 应用程序(application buffer)操作(read)其实是从 PageCache 拷贝 4kb 进入用户内存
关于扇区、磁盘块、Page(PageCache)在N年前谈过要有一定的了解!
常见的block大小为512Bytes,1KB,4KB,查看本机 blockSize 大小的方式,通常为 4kb
为何加载block为16kb,该值也很讲究blockSize*4,难道也发生了4次IO?非也,这又涉及到IO合并(readahead算法)!另外该值并非固定值值,内核的预读算法则会以它认为更合适的大小进行预读 I/O,比如16-128KB,当然可以手动进行调整。对这块敢兴趣的同学可以看文末的引用资料
当用户继续访问接下来的[4kb,16kb]的磁盘内容时,便是直接从 PageCache 去访问了!当我看到下图也有些不适应,确实我们离开发操作系统的老外(老码农)还远着呢,只能大致领略的它味道。

内存吃紧时PageCache 会受影响吗?
肯定是会影响的,PageCache 是动态调整的,可以通过 linux 的系统参数进行调整,默认是占据总内存的 20%。可以通过free命令进行监控(cache:page cache和slab所占用的内存之和,buff/cache:buffers + cache),它一个内核配置接口 /proc/sys/vm/drop_caches 可以允许用户手动清理cache来达到释放内存的作用,这个文件有三个值:1、2、3
Writing to this will cause the kernel to drop clean caches, dentries and inodes from memory, causing that memory to become free.
- To free pagecache:
- * echo 1 > /proc/sys/vm/drop_caches
- To free dentries and inodes:
- * echo 2 > /proc/sys/vm/drop_caches
- To free pagecache, dentries and inodes:
- * echo 3 > /proc/sys/vm/drop_caches
- As this is a non-destructive operation, and dirty objects are notfreeable, the user should run "sync" first in order to make sure allcached objects are freed.
- This tunable was added in 2.6.16.
毛刺现象
现代操作系统会使用尽可能多的空闲内存来充当 PageCache,当操作系统回收 PageCache 内存的速度低于应用写缓存的速度时,会影响磁盘写入的速率,直接表现为写入 RT 增大,这被称之为“毛刺现象”
Direct IO
去掉PageCache的确可以实现高效的随机读,的确也有存在的价值!采用 Direct IO + 自定义内存管理机制会使得产品更加的可控,高性能。

如何使用呢?
使用 Direct IO 最终需要调用到 c 语言的 pwrite 接口,并设置 O_DIRECT flag,使用 O_DIRECT 存在不少限制:
- 操作系统限制:Linux 操作系统在 2.4.10 及以后的版本中支持 O_DIRECT flag,老版本会忽略该 Flag;Mac OS 也有类似于 O_DIRECT 的机制
- 用于传递数据的缓冲区,其内存边界必须对齐为 blockSize 的整数倍
- 用于传递数据的缓冲区,其传递数据的大小必须是 blockSize 的整数倍
- 数据传输的开始点,即文件和设备的偏移量,必须是 blockSize 的整数倍
目前Java 目前原生并不支持,但github已经有封装好了 Java 的 JNA 库(smacke/jaydio),实现了 Java 的 Direct IO。
它自己搞了一套 Buffer 接口跟 JDK 的类库不兼容,且读写实现里面加了一块 Buffer 用于缓存内容至 Block 对齐有点破坏 Direct IO 的语义。
int bufferSize = 1<<23; // Use 8 MiB buffers
byte[] buf = new byte[bufferSize];
DirectRandomAccessFile fin = new DirectRandomAccessFile(new File("hello.txt"), "r", bufferSize);
DirectRandomAccessFile fout = new DirectRandomAccessFile(new File("world.txt"), "rw", bufferSize);
while (fin.getFilePointer() < fin.length()) {
int remaining = (int)Math.min(bufferSize, fin.length()-fin.getFilePointer());
fin.read(buf,0,remaining);
fout.write(buf,0,remaining);
}
fin.close();
fout.close();
当然也有人对它进行了再度封装,可参阅J-DirectIO。
MMAP和DIRECT IO区别
看完此文,题目不言自明。转自 http://blog.chinaunix.net/uid-27105712-id-3270102.html
在Linux 开发中,有几个关系到性能的东西,技术人员非常关注:进程,CPU,MEM,网络IO,磁盘IO。本篇文件打算详细全面,深入浅出。剖析文件IO的细节。从多个角度探索如何提高IO性能。
阐述之前,要先有个大视角,让我们站在万米高空,鸟瞰我们的文件IO,它们设计是分层的,分层有2个好处,一是架构清晰,二是解耦。让我们看一下下面这张图。
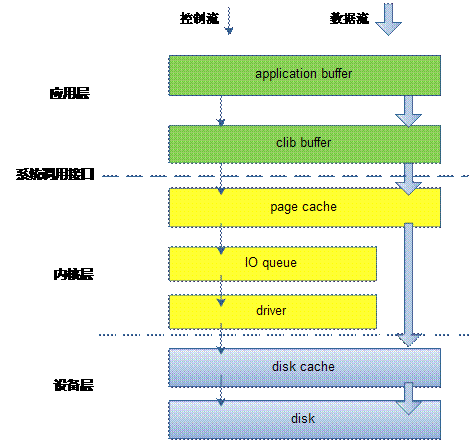
1. 穿越各层写文件方式
程序的最终目的是要把数据写到磁盘上, 但是系统从通用性和性能角度,尽量提供一个折中的方案来保证这些。让我们来看一个最常用的写文件典型example,也是路径最长的IO。
{
char *buf = malloc(MAX_BUF_SIZE);
strncpy(buf, src, , MAX_BUF_SIZE);
fwrite(buf, MAX_BUF_SIZE, 1, fp);
fclose(fp);
}这里malloc的buf对于图层中的application buffer,即应用程序的buffer;
调用fwrite后,把数据从application buffer 拷贝到了 CLib buffer,即C库标准IObuffer。fwrite返回后,数据还在CLib buffer,如果这时候进程core掉。这些数据会丢失。没有写到磁盘介质上。当调用fclose的时候,fclose调用会把这些数据刷新到磁盘介质上。除了fclose方法外,还有一个主动刷新操作fflush 函数,不过fflush函数只是把数据从CLib buffer 拷贝到page cache 中,并没有刷新到磁盘上,从page cache刷新到磁盘上可以通过调用fsync函数完成。
从上面类子看到,一个常用的fwrite函数过程,基本上历经千辛万苦,数据经过多次copy,才到达目的地。有人心生疑问,这样会提高性能吗,反而会降低性能吧。这个问题先放一放。
有人说,我不想通过fwrite+fflush这样组合,我想直接写到page cache。这就是我们常见的文件IO调用read/write函数。这些函数基本上是一个函数对应着一个系统调用,如sys_read/sys_write. 调用write函数,是直接通过系统调用把数据从应用层拷贝到内核层,从application buffer 拷贝到 page cache 中。
1)系统调用,write会触发用户态/内核态切换?是的。那有没有办法避免这些消耗。
2)这时候该mmap出场了,mmap把page cache 地址空间映射到用户空间,应用程序像操作应用层内存一样,写文件。省去了系统调用开销。
3)那如果继续刨根问底,如果想绕过page cache,直接把数据送到磁盘设备上怎么办。通过open文件带上O_DIRECT参数,这是write该文件。就是直接写到设备上。
4)如果继续较劲,直接写扇区有没有办法。这就是所谓的RAW设备写,绕开了文件系统,直接写扇区,想fdsik,dd,cpio之类的工具就是这一类操作。
2. IO调用链
列举了上述各种穿透各种cache 层写操作,可以看到系统提供的接口相当丰富,满足你各种写要求。下面通过讲解图一,了解一下文件IO的调用链。
1) fwrite是系统提供的最上层接口,也是最常用的接口。它在用户进程空间开辟一个buffer,将多次小数据量相邻写操作先缓存起来,合并,最终调用write函数一次性写入(或者将大块数据分解多次write调用)。
2)Write函数通过调用系统调用接口,将数据从应用层copy到内核层,所以write会触发内核态/用户态切换。当数据到达page cache后,内核并不会立即把数据往下传递。而是返回用户空间。数据什么时候写入硬盘,有内核IO调度决定,所以write是一个异步调用。这一点和read不同,read调用是先检查page cache里面是否有数据,如果有,就取出来返回用户,如果没有,就同步传递下去并等待有数据,再返回用户,所以read是一个同步过程。当然你也可以把write的异步过程改成同步过程,就是在open文件的时候带上O_SYNC标记。
数据到了page cache后,内核有pdflush线程在不停的检测脏页,判断是否要写回到磁盘中。把需要写回的页提交到IO队列——即IO调度队列。又IO调度队列调度策略调度何时写回。
提到IO调度队列,不得不提一下磁盘结构。这里要讲一下,磁头和电梯一样,尽量走到头再回来,避免来回抢占是跑,磁盘也是单向旋转,不会反复逆时针顺时针转的。从网上copy一个图下来,具体这里就不介绍。
IO队列有2个主要任务。一是合并相邻扇区的,二是排序。合并相信很容易理解,排序就是尽量按照磁盘选择方向和磁头前进方向排序。因为磁头寻道时间是和昂贵的。
这里IO队列和我们常用的分析工具IOStat关系密切。IOStat中rrqm/s wrqm/s表示读写合并个数。avgqu-sz表示平均队列长度。
内核中有多种IO调度算法。当硬盘是SSD时候,没有什么磁道磁头,人家是随机读写的,加上这些调度算法反而画蛇添足。OK,刚好有个调度算法叫noop调度算法,就是什么都不错(合并是做了)。刚好可以用来配置SSD硬盘的系统。
从IO队列出来后,就到了驱动层(当然内核中有更多的细分层,这里忽略掉),驱动层通过DMA,将数据写入磁盘cache。
至于磁盘cache时候写入磁盘介质,那是磁盘控制器自己的事情。如果想要睡个安稳觉,确认要写到磁盘介质上。就调用fsync函数吧。可以确定写到磁盘上了。
3. 一致性和安全性
谈完调用细节,再将一下一致性问题和安全问题。既然数据没有到到磁盘介质前,可能处在不同的物理内存cache中,那么如果出现进程死机,内核死,掉电这样事件发生。数据会丢失吗。
当进程死机后:只有数据还处在application cache或CLib cache时候,数据会丢失。数据到了page cache。进程core掉,即使数据还没有到硬盘。数据也不会丢失。
当内核core掉后,只要数据没有到达disk cache,数据都会丢失。
掉电情况呢,哈哈,这时候神也救不了你,哭吧。
那么一致性呢,如果两个进程或线程同时写,会写乱吗?或A进程写,B进程读,会写脏吗?
文章写到这里,写得太长了,就举出各种各样的例子。讲一下大概判断原则吧。fwrite操作的buffer是在进程私有空间,两个线程读写,肯定需要锁保护的。如果进程,各有各的地址空间。是否要加锁,看应用场景。
write操作如果写大小小于PIPE_BUF(一般是4096),是原子操作,能保证两个进程“AAA”,“BBB”写操作,不会出现“ABAABB”这样的数据交错。O_APPEND 标志能保证每次重新计算pos,写到文件尾的原子性。
数据到了内核层后,内核会加锁,会保证一致性的。
4. 性能问题
性能从系统层面和设备层面去分析;磁盘的物理特性从根本上决定了性能。IO的调度策略,系统调用也是致命杀手。
磁盘的寻道时间是相当的慢,平均寻道时间大概是在10ms,也就是是每秒只能100-200次寻道。
磁盘转速也是影响性能的关键,目前最快15000rpm,大概就每秒500转,满打满算,就让磁头不寻道,设想所有的数据连续存放在一个柱面上。大家可以算一下每秒最多可以读多少数据。当然这个是理论值。一般情况下,盘片转太快,磁头感应跟不上,所以需要转几圈才能完全读出磁道内容。
另外设备接口总线传输率是实际速率的上限。
另外有些等密度磁盘,磁盘外围磁道扇区多,线速度快,如果频繁操作的数据放在外围扇区,也能提高性能。
利用多磁盘并发操作,也不失为提高性能的手段。
这里给个业界经验值:机械硬盘顺序写~30MB,顺序读取速率一般~50MB好的可以达到100多M, SSD读达到~400MB,SSD写性能和机械硬盘差不多。
O_DIRECT 和 RAW设备最根本的区别是O_DIRECT是基于文件系统的,也就是在应用层来看,其操作对象是文件句柄,内核和文件层来看,其操作是基于inode和数据块,这些概念都是和ext2/3的文件系统相关,写到磁盘上最终是ext3文件。
而RAW设备写是没有文件系统概念,操作的是扇区号,操作对象是扇区,写出来的东西不一定是ext3文件(如果按照ext3规则写就是ext3文件)。
一般基于O_DIRECT来设计优化自己的文件模块,是不满系统的cache和调度策略,自己在应用层实现这些,来制定自己特有的业务特色文件读写。但是写出来的东西是ext3文件,该磁盘卸下来,mount到其他任何linux系统上,都可以查看。
而基于RAW设备的设计系统,一般是不满现有ext3的诸多缺陷,设计自己的文件系统。自己设计文件布局和索引方式。举个极端例子:把整个磁盘做一个文件来写,不要索引。这样没有inode限制,没有文件大小限制,磁盘有多大,文件就能多大。这样的磁盘卸下来,mount到其他linux系统上,是无法识别其数据的。
两者都要通过驱动层读写;在系统引导启动,还处于实模式的时候,可以通过bios接口读写raw设备。
《直接io的优缺点》https://www.ibm.com/developerworks/cn/linux/l-cn-directio/
《aio和direct io关系以及DMA》http://blog.csdn.net/brucexu1978/article/details/7085924
《io模型矩阵》http://www.ibm.com/developerworks/cn/linux/l-async/
《为什么nginx引入多线程:减少阻塞IO影响》http://www.aikaiyuan.com/10228.html
《aio机制在nginx之中的使用:output chain 》http://www.aikaiyuan.com/8867.html
《nginx对Linux native AIO机制的封装》http://www.aikaiyuan.com/8869.html
《nginx output chain 分析》https://my.oschina.net/astute/blog/316954
《sendfile和read/write的内核切换次数》http://www.cnblogs.com/zfyouxi/p/4196170.html


