

【ceph】ceph分布式存储MDS(各种状态、源码)
目录
compat fs 运维 up ceph xx mds MDS
1. mds存储
- 元数据的内存缓存,为了加快元数据的访问。
- 保存了文件系统的元数据(对象里保存了子目录和子文件的名称和inode编号)
- 还保存cephfs日志journal,日志是用来恢复mds里的元数据缓存
- 重启mds的时候会通过replay的方式从osd上加载之前缓存的元数据
2. mds冷备/热备
- 冷备就是备份的mds,只起到一个进程备份的作用,并不备份lru元数据。主备进程保持心跳关系,一旦主的mds挂了,备份mds replay()元数据到缓存,当然这需要消耗一点时间。
- 热备除了进程备份,元数据缓存还时时刻刻的与主mds保持同步,当 active mds挂掉后,热备的mds直接变成主mds,并且没有replay()的操作,元数据缓存大小和主mds保持一致。
说明:
- rejoin把客户端的inode加载到mds cache。
- replay把从cephfs的journal恢复内存。
3. mds主备切换策略
- 默认每个standby都一样
- 指定后补
- mds standby for name指定一 MDS 守护进程的名字,此进程将作为它的候补
- mds standby for rank此 MDS 将作为本机架上 MDS 守护进程的候补
- 优先级最高standby replay
ceph 单活mds主从切换流程 https://www.freesion.com/article/4579430299/
ceph-mds的standby_replay高速热备状态:https://uzshare.com/view/812012
4. 节点失效机制
- 一个活跃的MDS定期向monitor发送交互信息,如果一个MDS在mds_beacon_grace(默认15s)时间内没有向monitor注册,则认为该MDS失效。
5. 恢复过程
- 失效节点的相关日志被读入内存;
- 处理有争议的子树分配问题和涉及多个MDS的transaction;
- 与client重新建立会话并重新保存打开文件的状态;
- 接替失效节点的MDS加入到MDS集群的分布式缓存中
6. resolve阶段的事件
- 恢复节点向所有MDS发送一个resolve信息,该信息中包含了当前恢复节点管理的子树、在迁移过程中出现故障的子树;
- 其他正常运行的MDS也要将这些信息发送给正在恢复的MDS;
- 恢复中的MDS根据收到的子树信息重建自己缓存中的子树层次结构。
7. 重建分布式缓存和锁状态
- 恢复节点向所有MDS发送一个rejoin信息,该信息包含了恢复节点所知道的接受节点拥有的元数据副本信息并宣称自己没有管理的恢复文件;
- 原来有效的节点向恢复节点发送信息,告诉恢复节点自己拥有的元数据副本,并且向恢复节点加入锁状态
- 恢复节点将自己原本不知道的副本信息加入到自己的缓存中
Ceph MDS States状态详解
元数据服务器(MDS)在CephFS的正常操作过程中经历多个状态。例如,一些状态指示MDS从MDS的先前实例从故障转移中恢复。在这里,我们将记录所有这些状态,并包括状态图来可视化转换。
MDS 的各种状态:https://drunkard.github.io/cephfs/mds-states/
ceph/mds-states.rst at master · ceph/ceph · GitHub
常见状态
up:active 这个状态是正常运行的状态。 这个表明该mds在rank中是可用的状态。 up:standby 这个状态是灾备状态,用来接替主挂掉的情况。 up:standby_replay 灾备守护进程就会持续读取某个处于 up 状态的 rank 的元数据日志。这样它就有元数据的热缓存,在负责这个 rank 的守护进程失效时,可加速故障切换。 一个正常运行的 rank 只能有一个灾备重放守护进程( standby replay daemon ),如果两个守护进程都设置成了灾备重放状态,那么其中任意一个会取胜,另一个会变为普通的、非重放灾备状态。 一旦某个守护进程进入灾备重放状态,它就只能为它那个 rank 提供灾备。如果有另外一个 rank 失效了,即使没有灾备可用,这个灾备重放守护进程也不会去顶替那个失效的。
不太常见的或过渡状态
up:boot 此状态在启动期间被广播到CEPH监视器。这种状态是不可见的,因为监视器立即将MDS分配给可用的秩或命令MDS作为备用操作。这里记录了完整性的状态。 up:creating The MDS is creating a new rank (perhaps rank 0) by constructing some per-rank metadata (like the journal) and entering the MDS cluster. up:starting The MDS is restarting a stopped rank. It opens associated per-rank metadata and enters the MDS cluster. up:stopping When a rank is stopped, the monitors command an active MDS to enter the up:stopping state. In this state, the MDS accepts no new client connections, migrates all subtrees to other ranks in the file system, flush its metadata journal, and, if the last rank (0), evict all clients and shutdown (see also CephFS 管理命令). up:replay The MDS taking over a failed rank. This state represents that the MDS is recovering its journal and other metadata. 日志恢复阶段,他将日志内容读入内存后,在内存中进行回放操作。 up:resolve The MDS enters this state from up:replay if the Ceph file system has multiple ranks (including this one), i.e. it’s not a single active MDS cluster. The MDS is resolving any uncommitted inter-MDS operations. All ranks in the file system must be in this state or later for progress to be made, i.e. no rank can be failed/damaged or up:replay. 用于解决跨多个mds出现权威元数据分歧的场景,对于服务端包括子树分布、Anchor表更新等功能,客户端包括rename、unlink等操作。 up:reconnect An MDS enters this state from up:replay or up:resolve. This state is to solicit reconnections from clients. Any client which had a session with this rank must reconnect during this time, configurable via mds_reconnect_timeout. 恢复的mds需要与之前的客户端重新建立连接,并且需要查询之前客户端发布的文件句柄,重新在mds的缓存中创建一致性功能和锁的状态。mds不会同步记录文件打开的信息,原因是需要避免在访问mds时产生多余的延迟,并且大多数文件是以只读方式打开。 up:rejoin The MDS enters this state from up:reconnect. In this state, the MDS is rejoining the MDS cluster cache. In particular, all inter-MDS locks on metadata are reestablished. If there are no known client requests to be replayed, the MDS directly becomes up:active from this state. 把客户端的inode加载到mds cache up:clientreplay The MDS may enter this state from up:rejoin. The MDS is replaying any client requests which were replied to but not yet durable (not journaled). Clients resend these requests during up:reconnect and the requests are replayed once again. The MDS enters up:active after completing replay.
失败状态
down:failedNo MDS actually holds this state. Instead, it is applied to the rank in the file system. For example:
$ ceph fs dump ... max_mds 1 in 0 up {} failed 0 ...Rank 0 is part of the failed set.
down:damagedNo MDS actually holds this state. Instead, it is applied to the rank in the file system. For example:
$ ceph fs dump ... max_mds 1 in 0 up {} failed damaged 0 ...Rank 0 has become damaged (see also 灾难恢复) and placed in the
damagedset. An MDS which was running as rank 0 found metadata damage that could not be automatically recovered. Operator intervention is required.down:stoppedNo MDS actually holds this state. Instead, it is applied to the rank in the file system. For example:
$ ceph fs dump ... max_mds 1 in 0 up {} failed damaged stopped 1 ...The rank has been stopped by reducing
max_mds(see also 多活 MDS 守护进程的配置).
主从切换流程:
handle_mds_map state change up:boot --> up:replay
handle_mds_map state change up:replay --> up:reconnect
handle_mds_map state change up:reconnect --> up:rejoin
handle_mds_map state change up:rejoin --> up:active
原文链接:https://blog.csdn.net/weixin_44389885/article/details/86621717
状态图
这张状态图展示了 MDS/rank 可能的状态转变,图例如下:
颜色
-
Green: MDS is active.
-
Orange: MDS is in transient state trying to become active.
-
Red: MDS is indicating a state that causes the rank to be marked failed.
-
Purple: MDS and rank is stopping.
-
Black: MDS is indicating a state that causes the rank to be marked damaged.
形状
-
Circle圆: an MDS holds this state.
-
Hexagon六边形: no MDS holds this state (it is applied to the rank).
线
- A double-lined shape indicates the rank is "in".
.. graphviz:: mds-state-diagram.dot
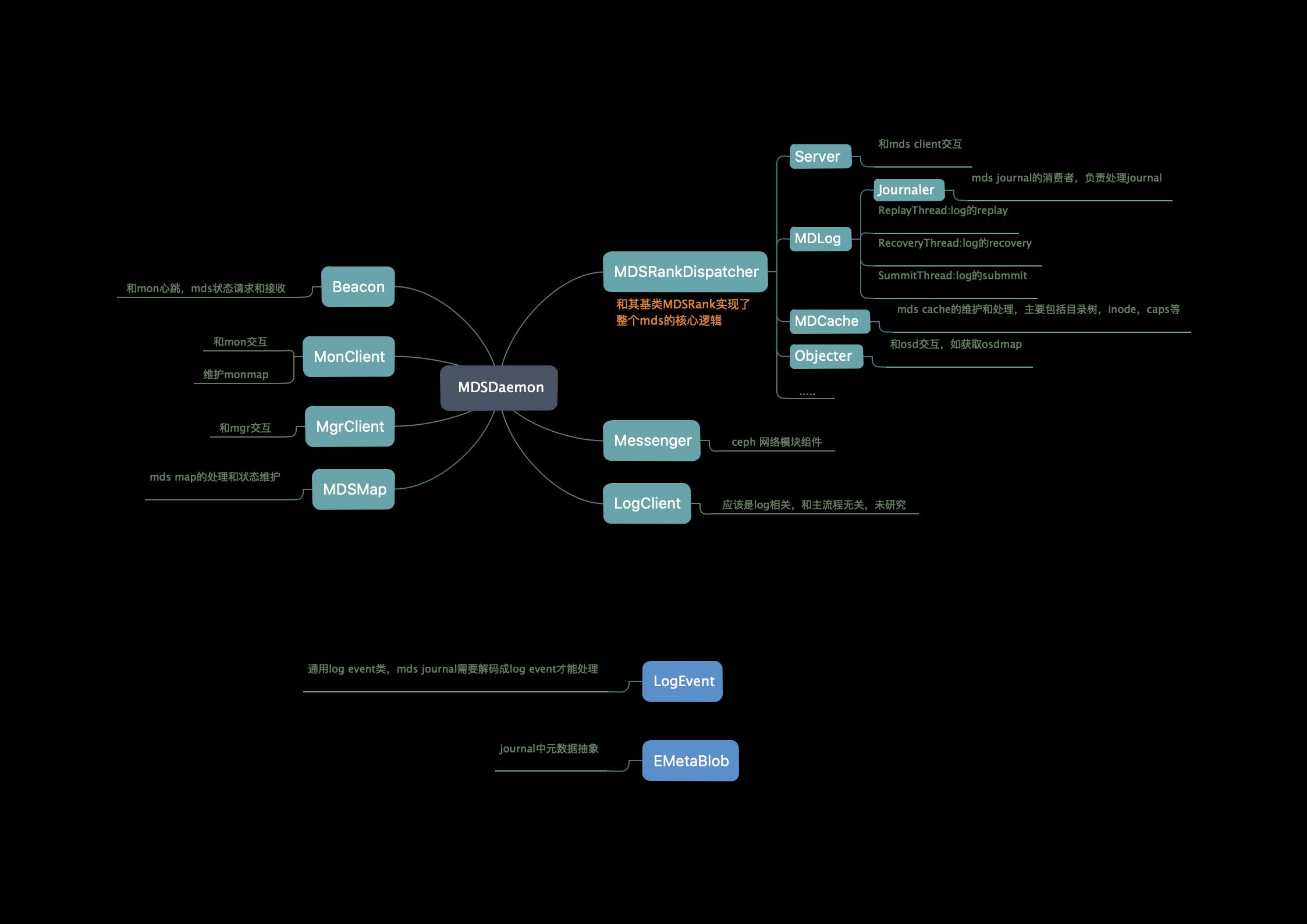
MDS源码分析
MDS源码分析-1 启动流程 :https://www.jianshu.com/p/335073659591
MDS源码分析-2 消息分发:https://www.jianshu.com/p/729d0352eceb
MDS源码分析-3 LOOKUP & GETATTR:https://www.jianshu.com/p/ed31f361eb4b
MDS源码分析-4 OPEN & OPENC:https://www.jianshu.com/p/c20d92171b67
MDS源码分析-6 mdlog https://www.jianshu.com/p/454dce048ff6
MDS源码分析-7 mkdir https://www.jianshu.com/p/8ecc29aa809f
MDS是如何启动的:https://www.jianshu.com/p/742e18f53f3a
CEPH 单活MDS主从切换流程 https://www.freesion.com/article/4579430299/
MDSRank类解析 https://blog.csdn.net/weixin_34212762/article/details/92579017
compat fs 运维 up ceph xx mds MDS
ceph 运维操作-MDS:https://www.icode9.com/content-4-938539.html
1.说明
1.1介绍
MDS全称Ceph Metadata Server,是CephFS服务依赖的元数据服务。
2. 常用操作
2.1 查看mds的状态
$ ceph mds stat
test_fs-1/1/1 up test1_fs-1/1/1 up {[test1_fs:0]=ceph-xx-osd03.gz01=up:active,[test_fs:0]=ceph-xx-osd00=up:active}
2.2 查看mds的映射信息
$ ceph mds dump
dumped fsmap epoch 50
fs_name test_fs
epoch 50
flags 4
created 2017-09-05 10:06:56.343105
modified 2017-09-05 10:06:56.343105
tableserver 0
root 0
session_timeout 60
session_autoclose 300
max_file_size 1099511627776
last_failure 0
last_failure_osd_epoch 4787
compat compat={},rocompat={},incompat={1=base v0.20,2=client writeable ranges,3=default file layouts on dirs,4=dir inode in separate object,5=mds uses versioned encoding,6=dirfrag is stored in omap,8=file layout v2}
max_mds 1
in 0
up {0=104262}
failed
damaged
stopped
data_pools [2]
metadata_pool 3
inline_data disabled
balancer
standby_count_wanted 1
104262: 100.0.0.34:6800/1897776151 'ceph-xx-osd00' mds.0.37 up:active seq 151200
2.3 删除mds节点
$ ceph mds rm 0 mds.ceph-xx-osd00
2.4 增加数据存储池
$ ceph mds add_data_pool <pool>
2.5 关闭mds集群
$ ceph mds cluster_down marked fsmap DOWN
2.6 启动mds集群
$ ceph mds cluster_up unmarked fsmap DOWN
2.7 可删除兼容功能
$ ceph mds compat rm_compat <int[0-]>
2.8 可删除不兼容的功能
$ ceph mds compat rm_incompat <int[0-]>
2.9 查看兼容性选项
$ ceph mds compat show
2.10 删除数据存储池
$ ceph mds remove_data_pool <pool>
2.11 停止指定mds
$ ceph mds stop <node1>
2.12 向某个mds发送命令
$ ceph mds tell <node> <args> [<args>...]
2.13 添加mds机器
#添加一个机器 new_host 到现有mds集群中 su - ceph -c "ceph-deploy --ceph-conf /etc/ceph/ceph.conf mds create $new_host"
2.14 查看客户端session
ceph daemon mds.ceph-xx-mds01.gz01 session ls
2.15 MDS 加回集群
systemctl daemon-reload
systemctl start ceph-mds.target
mds 启动过程
ceph mds启动流程_jiang4357291的博客-CSDN博客_ceph中mds



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· 字符编码:从基础到乱码解决
· SpringCloud带你走进微服务的世界